











Carlos Avendaño
To arrive to actionable insights, the journey starts with a robust tracking strategy, a deep understanding of the data collection strengths and weakness and data driven decision makers identifying the correct events to track.
http://rstudio-pubs-static.s3.amazonaws.com/287288_4bbfdd47532944b4a1c343e1023b9d21.html
| Data Science | Ambos | Data Analytics |
|---|---|---|
| Optimización de Algoritmos | Análisis estadístico | Software de Data Analytics |
| Aprendizaje de Máquina | Python, R, JS, Java y SQL | Sistemas de gestión de bases de datos |
| Desarrollo de Sofware | Minería de datos | Herramientas de Inteligencia de negocios |
| Herramientas de Big Data | Resolución de problemas | Herramientas de Visualización |
| Storytelling |
https://www.knowledgehut.com/blog/data-science/data-scientist-career-path
No hay una definición universal
Incluso entre los expertos en el tema no existe una única definición
Pero entre las distintas definiciones hay algunas que son las mas “aceptadas” o reconocidas.
“Field of study that gives computers the ability to learn without being explicitly programmed” - Arthur Samuel 1959
Arthur Samuel creó un programa que “aprendió” a jugar damas chinas a través de hacer que el programa jugará contra sí mismo miles de veces
En otras palabras debe aprender a realizar acciones racionales(la que produce el mejor resultado) a largo plazo(investigación de operaciones PDM)
https://link.springer.com/article/10.1007/s44163-021-00009-x/figures/1
Creación de programas, aplicaciones o herramientas computarizadas que acceden a datos existentes para identificar patrones y auto-ajustarse para hacer predicciones.
Proceso que basado en ejemplos, ya sean estos datos en un excel, en una base de datos, observaciones de algún proceso de negocio, observaciones de un evento, resultados de un experimento científico, etc. permite de manera automática identificar patrones para predecir futuros eventos.
Proceso que permite crear modelos matemáticos y estadísticos de un fenómeno o proceso haciendo que la computadora encuentre el modelo más adecuado en lugar de que lo haga manualmente una persona. realiza esta tarea a partir de buscar el modelo que mejor se ajusta a los datos, ejemplos u observaciones existentes.
Podemos pensar que el algoritmo de MLcomo una función f(x), que dados datos de entrada “x” asigna a ellos valores de salida “y”
Esta función no será definida manualmente ,será encontrada por la computadora a partir de patrones en los datos.
Concluimos que ML es: derivar inteligencia a partir de datos, a partir de un proceso de “aprendizaje” o “entrenamiento” en el que dados muchos ejemplos previos, la computadora se ajusta a realizar una tarea predictiva en ejemplos futuros, esta tarea predictiva en la mayoría de los casos requeriría inteligencia humana.
Andrew Ng, experto y líder en la materia dice “Inteligencia artificial es el destino , machine learning es el cohete para llegar allá , Big Data es el combustible”
Cloudera(empresa líder en productos y servicios de Big Data) dice : “No puedes lograr inteligencia artificial sin machine learning, no puedes hacer machine learning sin data analytics, no puedes hacer data analytics sin una buena infraestructura de datos”
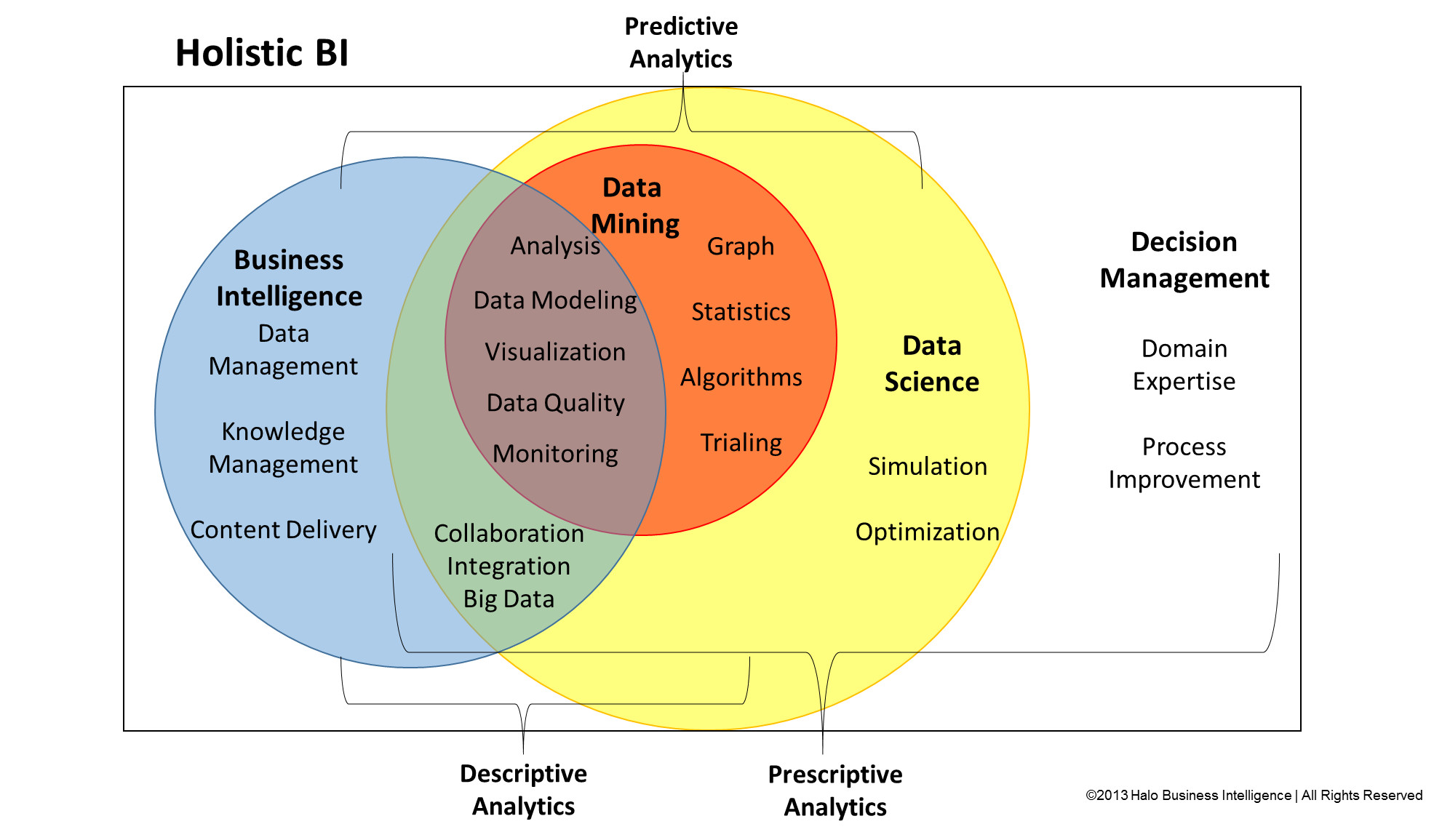
Data warehousing es una de las tareas de data engineering que consiste en crear una bodega de datos empresariales en el cual se integran, procesan , limpian y almacenan datos originados de distintas maneras y en distintas fuentes.
El data warehouse facilita y permite entonces hacer ML a gran escala en las empresas, a la vez que permite hacer lo que se conoce como “business intelligence”
La inteligencia de negocios consiste en poder analizar datos de toda la empresa de manera integrada, desde muchos puntos de vista para tomar decisiones de negocio fundamentadas e informadas.
Mi visión personal? Inteligencia de negocios combinada o reforzada con inteligencia artificial, para ambos casos el insumo son datos integrados, preprocesados y limpios(el data warehouse)
Cuando tenemos , o podemos adquirir muchos datos o ejemplos de una tarea o problema resolver.
Cuando queremos realizar predicciones de un evento o proceso, y existan datos o ejemplos históricos de este.
Aplicamos ML cuando queremos realizar tareas predictivas o tareas que parecieran requerir inteligencia humana, y contamos o podemos adquirir datos pasados.
Descubrimiento automático de patrones
Detección de anomalías(fraudes, defectos en manufactura, etc)
Modelos matemático/estadísticos predictivos, “aprendidos” (no creados manualmente) a partir de los datos de una organización
Reducción de dimensionalidad
Data mining: a veces usados como sinónimo, a veces se dice que se usa ML como recurso para hacer data mining, hay gran relación.
Diagnostico médico
Percepción(reconocimiento de imágenes y voz)
Detección de fraudes y anomalías
Descubrimiento de patrones comunes(basket analysis, reglas de asociación)
Chatbots
Traducción de idiomas
Detección de comentarios ofensivos o inapropiados.
Consiste en dar a la computadora o aplicación datos de ejemplo en donde para cada ejemplo, conocemos y le damos a la aplicación la “respuesta correcta” o esperada.
Si buscamos crear una aplicación que reconozca si en una imágen hay un gato o no, debemos recopilar imágenes ,identificar y anotar para cada imágen la existencia o no del gato.
Predicción de precios de casas, para lograr predecir el precio de casas futuras, necesitamos ejemplos con la “respuesta correcta”, es decir el precio real de otras casas de de ejemplo.
Regresión: el valor esperado, o a predecir(así como la respuesta correcta en los ejemplos) es un valor numérico decimal, continuo. Por ejemplo: 1.12, 334.45
Clasificación: el valor esperado , o predecir(así como la respuesta correcta en los ejemplos) es una categoría .Por ejemplo: “sí” o “no” , “gato” o “no-gato” , “click” o “no” click.El tipo básico de clasificación es “binario” es decir ,2 posibles categorías o valores, y con este como base se construyen casos de más de 2 categorías.Se realiza como paso previo una conversión de categoría a número, por ejemplo “si” y “no” a 1 y 0.
Algunos algoritmos de ML dan como resultado una probabilidad de que el resultado sea de cada categoría.
Lo utilizaremos para definir terminología y conceptos comunes en muchos tipos de ML
Es de tipo supervisado: para cada ejemplo(observación, o registro) sabemos la “respuesta correcta” o esperada.
Predecimos un número real.(cuanto o cuantos?)
Ejemplo: Buscamos identificar(estimar, predecir o aproximar) precio de venta de casas, usando como base datos de casas vendidas en el pasado
Lo utilizaremos para definir terminología y conceptos comunes en muchos tipos de ML
Es de tipo supervisado: para cada ejemplo(observación, o registro) sabemos la “respuesta correcta” o esperada.
Predecimos un número real.(cuanto o cuantos?)
Ejemplo: Buscamos identificar(estimar, predecir o aproximar) precio de venta de casas, usando como base datos de casas vendidas en el pasado
En aprendizaje no supervisado, no sabemos la “respuesta correcta”. Es decir, no conocemos:
La clase a la que pertenece un ejemplo(clasificación)
El valor numérico asociado o esperado(regresión)
Únicamente tenemos los datos y buscamos obtener patrones o estructura en ellos.
Dados datos históricos “X” acerca de algún evento, proceso o experimento, buscamos crear una herramienta que identifique cuando nuevos datos son anómalos, anormales, o fuera del comportamiento habitual. Por ejemplo:
Detección de fraudes: tenemos datos de comportamiento o actividades realizadas por usuarios y buscamos crear una herramienta que identifique comportamiento sospechoso
Manufactura: tenemos datos descriptivos de el proceso de fabricación y los artículos fabricados y buscamos crear una herramienta que detecte artículos defectuosos, antes de que sean enviados al cliente.
Monitoreo de websites y aplicaciones: una empresa digital puede decidir monitorear sus procesos y aplicaciones buscando identificar comportamientos anómalos(como ataques al website)
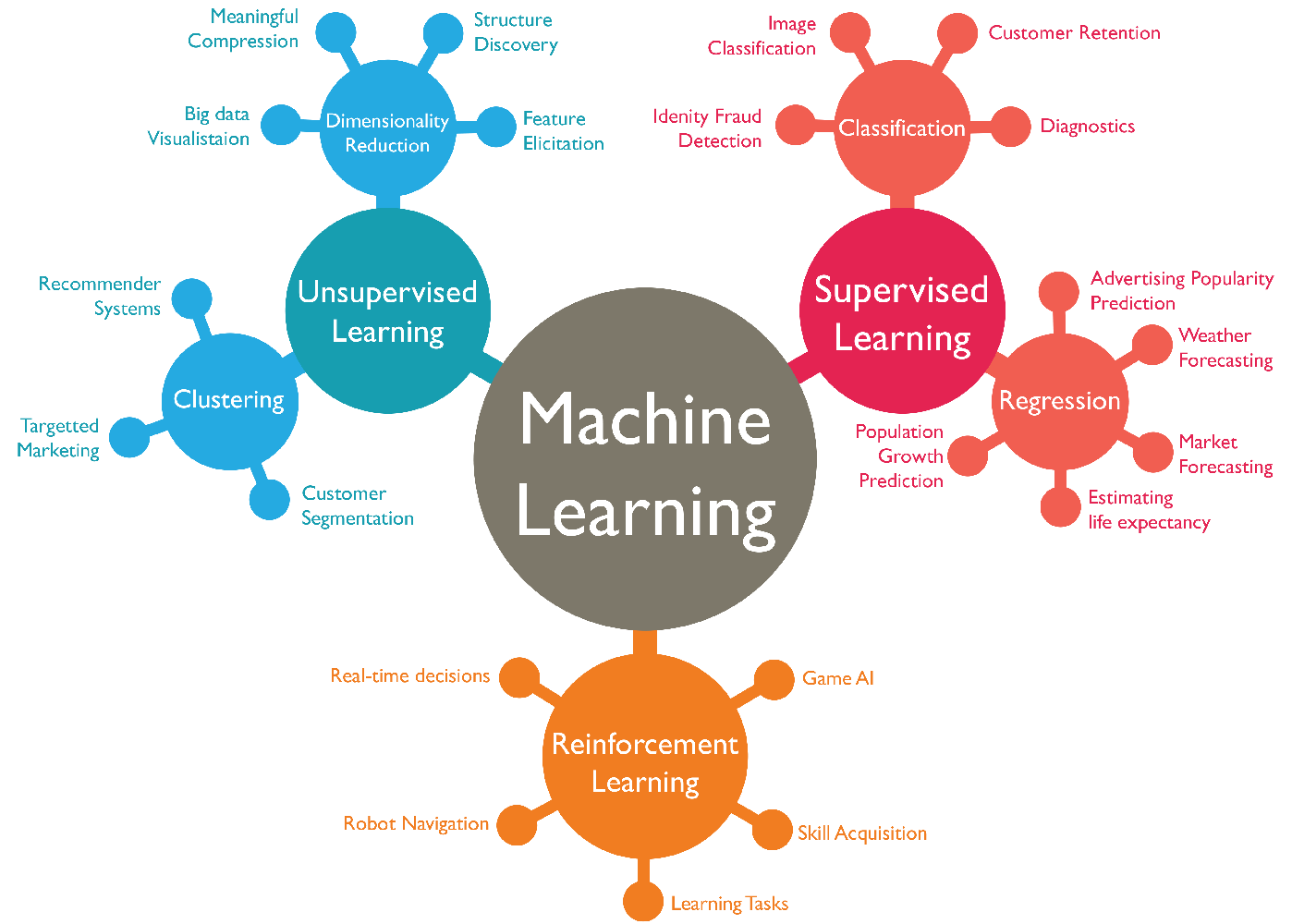
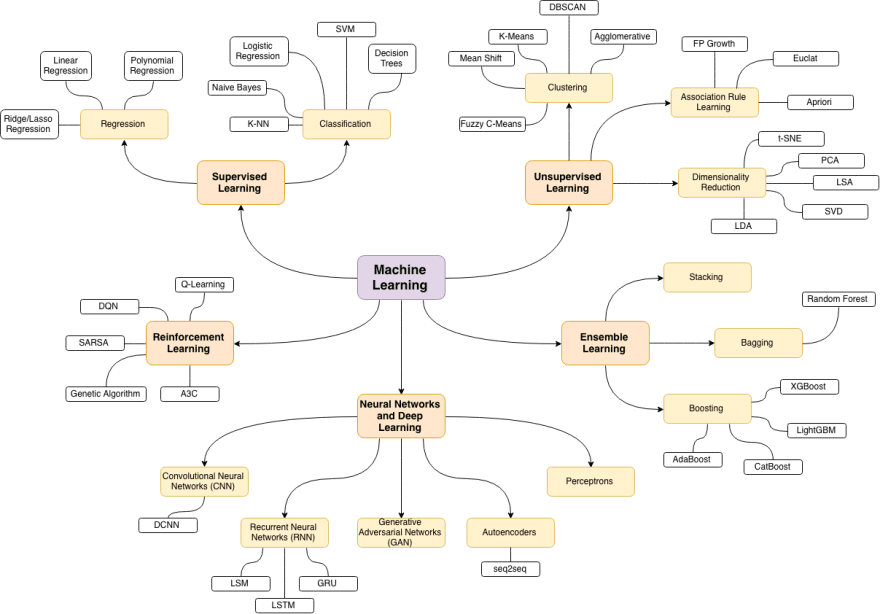
https://vitalflux.com/great-mind-maps-for-learning-machine-learning/
https://vitalflux.com/great-mind-maps-for-learning-machine-learning/
https://vitalflux.com/great-mind-maps-for-learning-machine-learning/
https://vitalflux.com/great-mind-maps-for-learning-machine-learning/
https://vitalflux.com/great-mind-maps-for-learning-machine-learning/
Aplicación web que permite crear y compartir documentos que contienen, código “vivo” , visualizaciones(imágenes, gráficas etc) y texto, muy útil para data science y machine learning .
Soporta más de 40 lenguajes de programación entre los principales esta Python, R y Scala.
Principal paquete de Python para operaciones científicas y numéricas, con soporte para vectores y matrices y operaciones entre estos(álgebra lineal), muy importante en data science y ML
Paquete que busca proveer facilidad y herramientas para realizar análisis de datos, es compatible y se basa en Python pero provee funcionalidad adicional con el objetivo de facilitar el análisis de datos, muy comúnmente usado en la fase de análisis exploratorio.
Paquete de graficación y visualización de datos flexible, personalizable, configurable y de calidad de publicación científica usado en para muchas tareas:
Pre-visualización y análisis exploratorio
Graficación de curvas de aprendizaje
Graficación de imágenes
Creación de informes y reportes
Librería de machine learning y data mining para Python, contiene algoritmos de clasificación, regresión y clustering así como funciones de pre-procesamiento,permite prototipar y crear pruebas de concepto rápidamente.
Plataforma para control de versiones en la web que utiliza como base Git
Renderiza los notebooks de Jupyter esto permite publicar en la web nuestro notebook y que otras personas lo puedan visualizar fácilmente.
Permite trabajar colaborativamente con otros desarrolladores o data scientist.
Portafolio en línea de tu trabajo y proyectos .
By Carlos Avendaño



