
Transformers & Diffusers
Wat zijn transformers?
Transformer models
Transformer models
- Geïntroduceerd in 2017
- Paper van Google Attention Is All You Need
- Baanbrekend en bepalend voor ontwikkeling taalmodellen

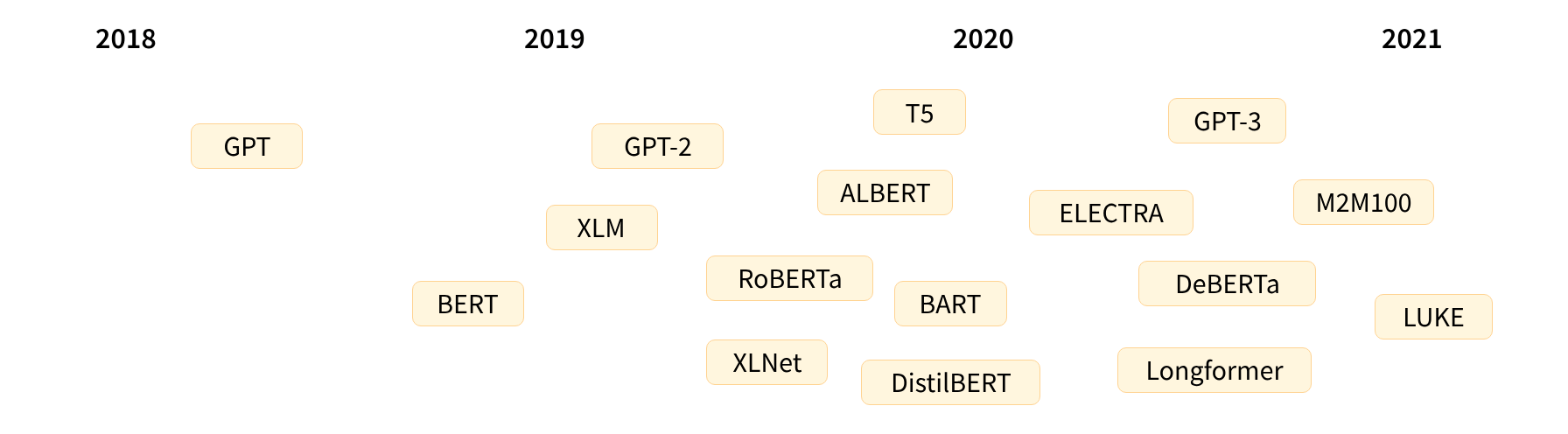
Transformer models
| Juni 2018 | GPT | het eerste vooraf getrainde Transformer-model, gebruikt voor fine-tuning op verschillende NLP-taken |
| Oktober 2018 | BERT | een ander groot vooraf getraind model, ontworpen om betere samenvattingen van zinnen te produceren |
| Februari 2019 | GPT-2 | een verbeterde (en grotere) versie van GPT die niet onmiddellijk openbaar werd vrijgegeven vanwege ethische zorgen. |
| Oktober 2019 | DistilBERT | een gedistilleerde versie van BERT die 60% sneller is, 40% lichter in geheugen, en toch 97% van de prestaties van BERT behoudt. |
| Oktober 2019 | BART en T5 | twee grote vooraf getrainde modellen die dezelfde architectuur gebruiken als het oorspronkelijke Transformer-model (de eerste die dat doet). |
| Mei 2020 | GPT-3 | een nog grotere versie van GPT-2 die goed presteert op verschillende taken zonder de noodzaak van fine-tuning (genaamd zero-shot learning) |
Transformer models
- GPT-like (ofwel auto-regressive Transformer modellen)
- BERT-like (ofwel auto-encoding Transformer modellen)
- BART/T5-like (ofwel sequence-to-sequence Transformer modellen)
- Alle bovenstaande modellen zijn taalmodellen.
Taalmodellen
- Zijn getraind via self-supervised learning
- Geen mensen nodig om data te labelen
- Een voor-getraind model moet worden gefine-tuned met behulp van supervised learning
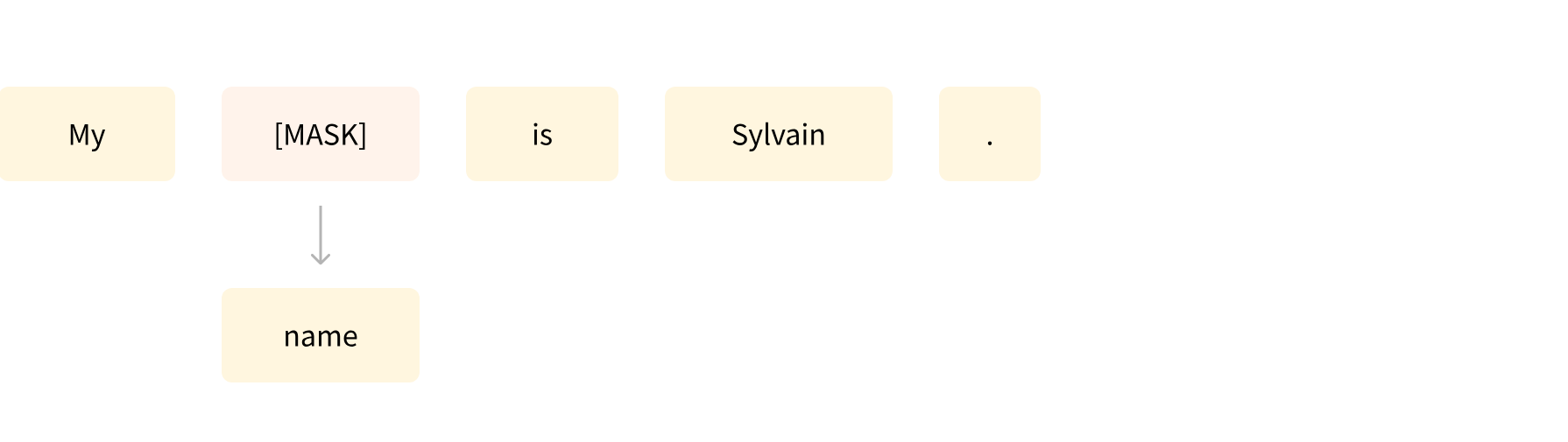
- Masked language modeling
Taalmodellen
- Causal language modeling

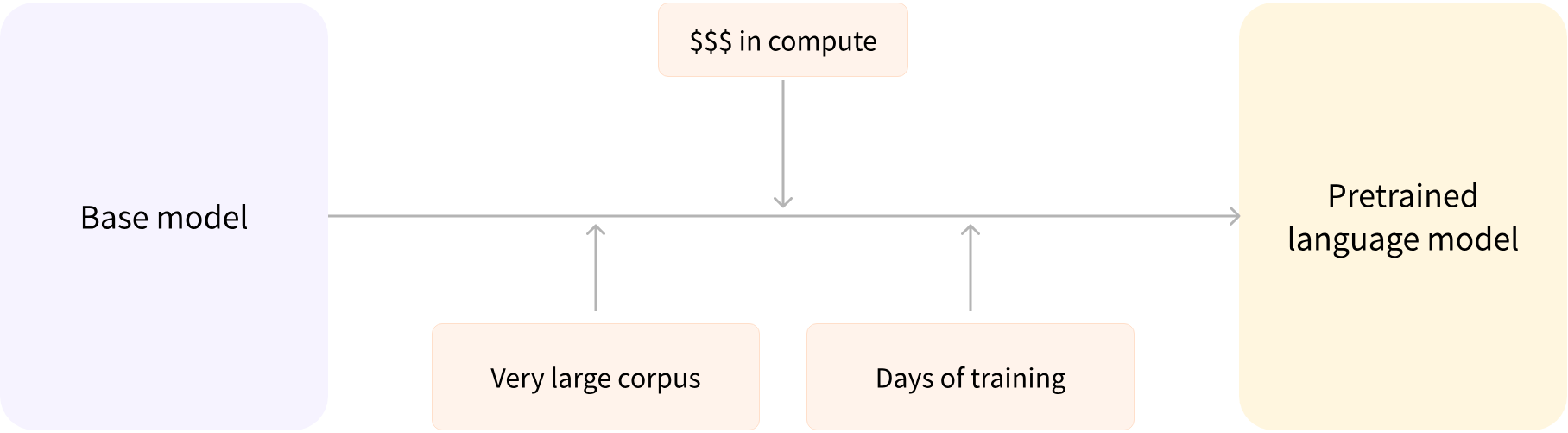
Transfer Learning
- Voor-trainen (pretraining) van een model op heel veel data
Transfer Learning
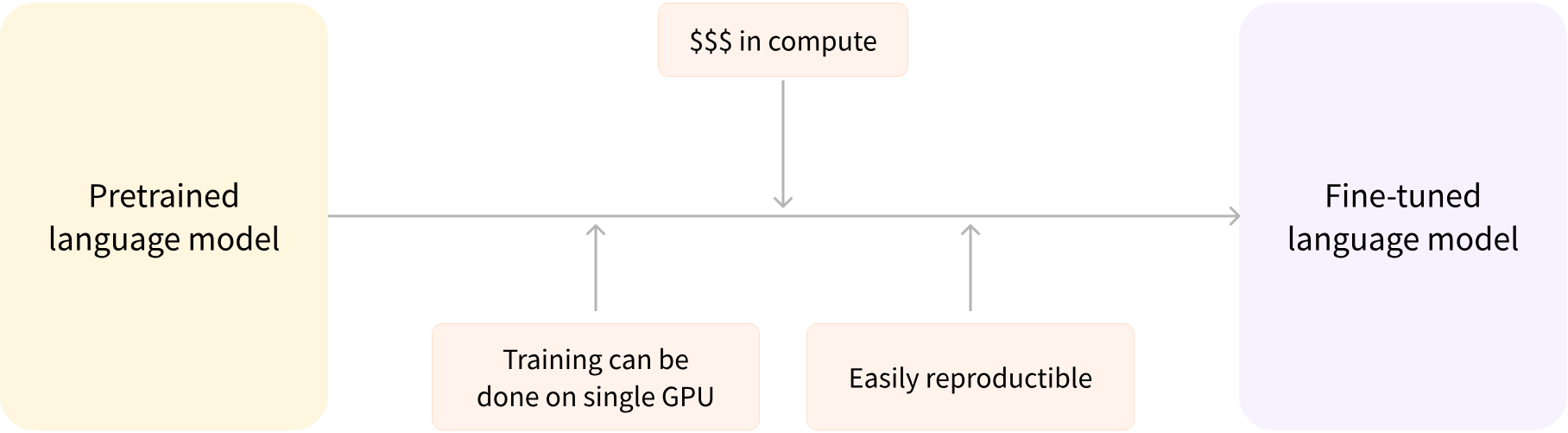
- Fine-tuning nadat een model is voorgetraind
Transfer Learning
Voordelen van fine-tuning:
- Fine-tuning dataset heeft overeenkomsten
- Kennisoverdracht
- Data-efficiëntie
- Tijd- en resourcebesparing
- Goede resultaten
- Minimale gegevensvereisten
De kennis die het vooraf getrainde model heeft verworven, wordt "overgedragen", vandaar de term transfer learning.
Transformer Architectuur
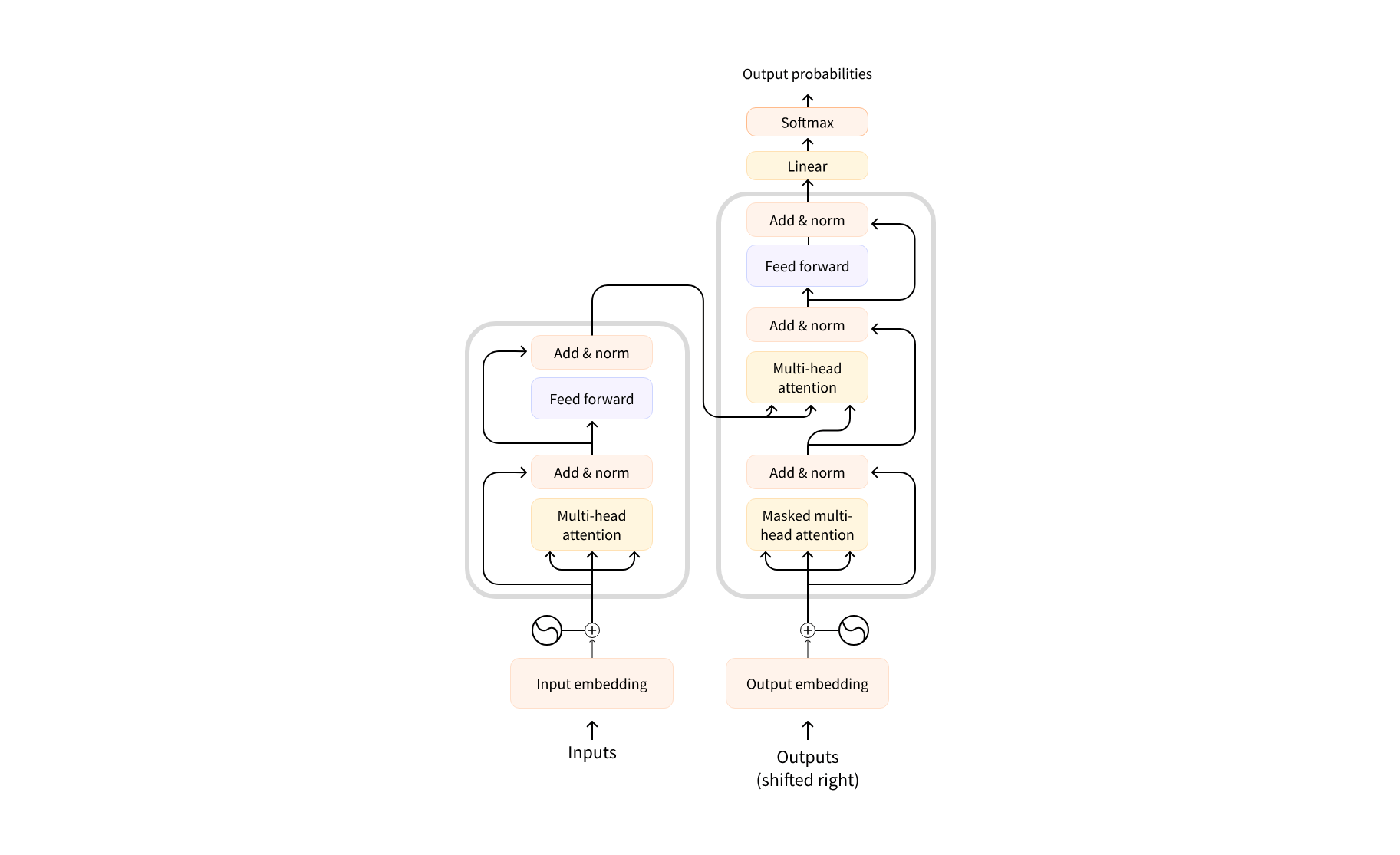
De originele architecture, zoals voorgesteld in Attention is all you need
Transformer Architectuur
- Encoder: de encoder ontvangt een invoer en bouwt daar een representatie van (features) op, in vectoren. Dit betekent dat het model geoptimaliseerd is om inzicht te krijgen in de invoer.
- Decoder: de decoder gebruikt de representatie (features) van de encoder samen met andere invoer om een doelsequentie te genereren. Dit betekent dat het model geoptimaliseerd is voor het genereren van uitvoer.
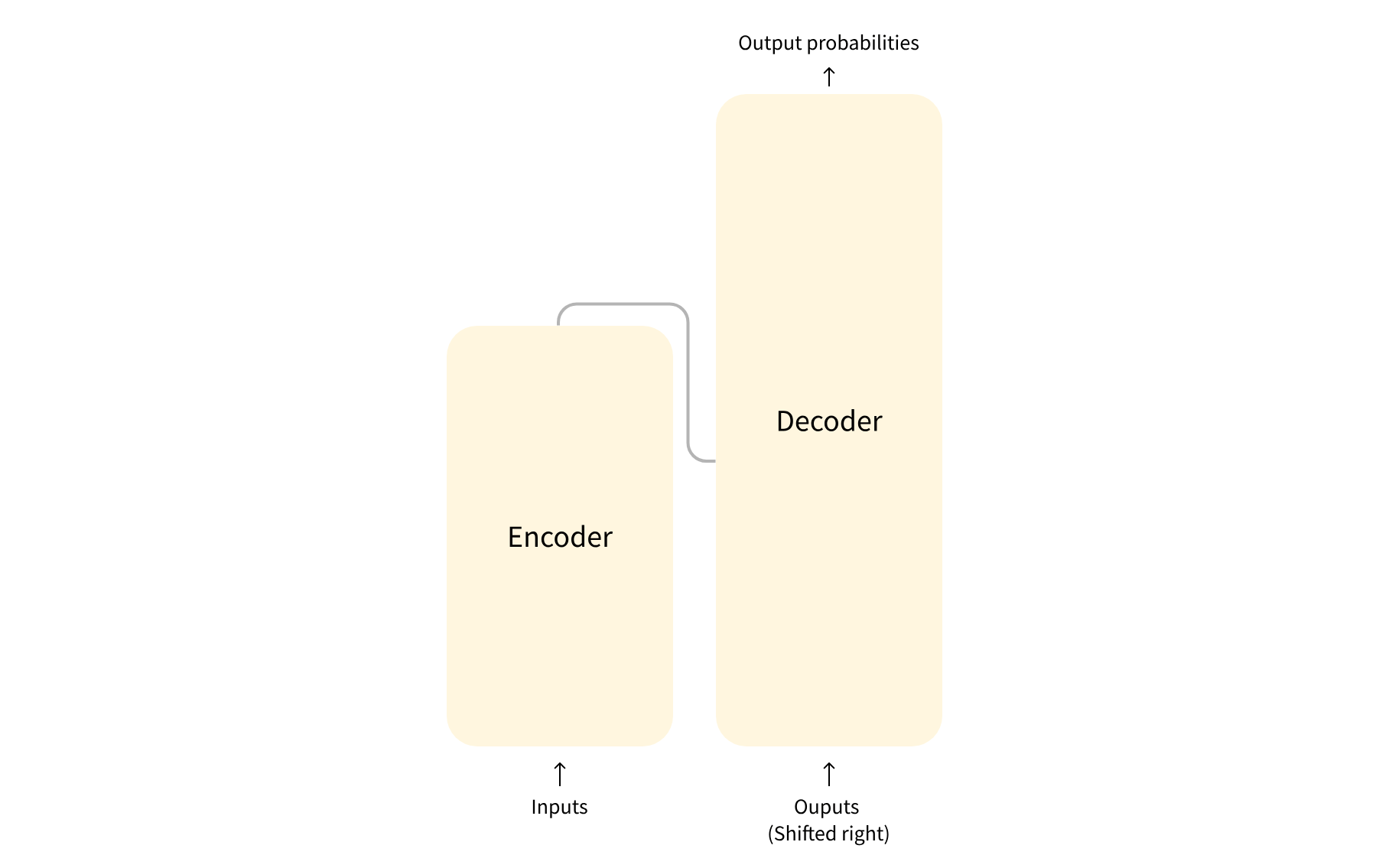
Transformer Architectuur
Encoder-only models: Geschikt voor taken die begrip van de invoer vereisen, zoals zinsclassificatie en herkenning van benoemde entiteiten. Bijv. BERT
Transformer Architectuur
Decoder-only models: Geschikt voor generatieve taken zoals tekstgeneratie. Bijv. GPT
Transformer Architectuur
Encoder-decoder models of sequence-to-sequence models: Geschikt voor generatieve taken die een invoer vereisen, zoals vertaling of samenvatting.
Architectuur vs Checkpoints
- Architectuur: Dit is het skelet van het model, de definitie van elke laag en elke operatie die binnen het model plaatsvindt.
- Checkpoints: Dit zijn de gewichten die in een gegeven architectuur worden geladen.
- Model: Dit is een overkoepelende term die niet zo precies is als "architectuur" of "checkpoint"; het kan beide betekenen.
Bijvoorbeeld, BERT is een architectuur, terwijl bert-base-cased, een set gewichten getraind door het Google-team voor de eerste release van BERT, een checkpoint is. Men kan echter zeggen "het BERT-model" en "het bert-base-cased-mode
Tokenizers

Tokenizers

Tokenizers
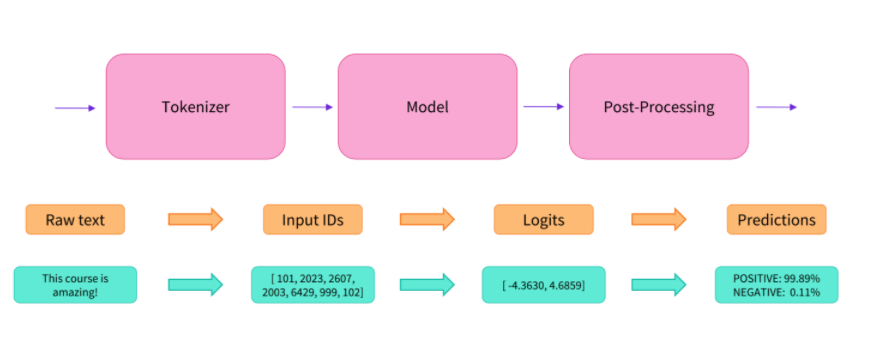
Transformers & Diffusers
Natural Language Processing
Wat is NLP?
NLP is een vakgebied van de taalkunde en machine learning gericht op het begrijpen van alles wat met menselijke taal te maken heeft. Het doel van NLP taken is niet alleen om afzonderlijke woorden te begrijpen, maar ook om de context van die woorden te begrijpen.
NLP Taken
Encoder taken
- Sentiment Analysis
- Zero-shot Classification
- Named Entity Recognition (NER)
- Mask Filling
- (extractive) Question Answering
Decoder taken
Encoder-Decoder
- Summarization
- Translation
Sentiment Analysis
Sentimentanalyse tagt gegevens als positief, negatief of neutraal en helpt bedrijven bij het analyseren van gegevens, het detecteren van inzichten en het automatiseren van processen.

Zero-shot classificatie
De zero-shot-classificatiepijplijn geeft de mogelijkheid om
- eigen labels te gebruiken voor classificatie, zonder afhankelijk te zijn van de labels van het vooraf getrainde model.
- tekst te classificeren met elke gewenste set labels.

Named Entity Recognition
Named Entity Recognition (NER) is een taak waarbij het model moet vinden welke delen van de invoertekst overeenkomen met entiteiten zoals personen, locaties of organisaties.

Mask Filling
- Eeenvoudig voorbeeld. Gegeven een zin, "De kat [MASK] op het dak", zou het model het woord "zat" voorspellen als het gemaskerde token.
- Tijdens het trainingsproces wordt het model bijgewerkt op basis van het verschil tussen zijn voorspellingen en de daadwerkelijke woorden in de zin.

Question Answer
Het Question-Answering pipeline beantwoordt vragen met behulp van informatie uit een gegeven context.

Text Generation
- Het idee hier is dat er een prompt is, het model zal het automatisch aanvullen door de resterende tekst te genereren.
- Dit lijkt op de voorspellende tekstfunctie die op veel telefoons te vinden is.
- Bijv. GPT, LLaMA,...

Summarization
Summarization is de taak om een tekst in te korten tot een kortere tekst terwijl alle (of de meeste) belangrijke aspecten die in de tekst worden genoemd behouden blijven.

Transformers & Diffusers
Diffusers
Wat zijn diffusers?
Diffusion models worden getraind om stap voor stap willekeurig Gaussian Noise te denoisen om iets te genereren zoals een afbeelding of audio. Dit heeft een enorme interesse in generatieve AI aangewakkerd. De Hugging Face diffusers bibliotheek is een bibliotheek die tot doel heeft diffusiemodellen voor iedereen breed toegankelijk te maken.
Wat zijn diffusers?
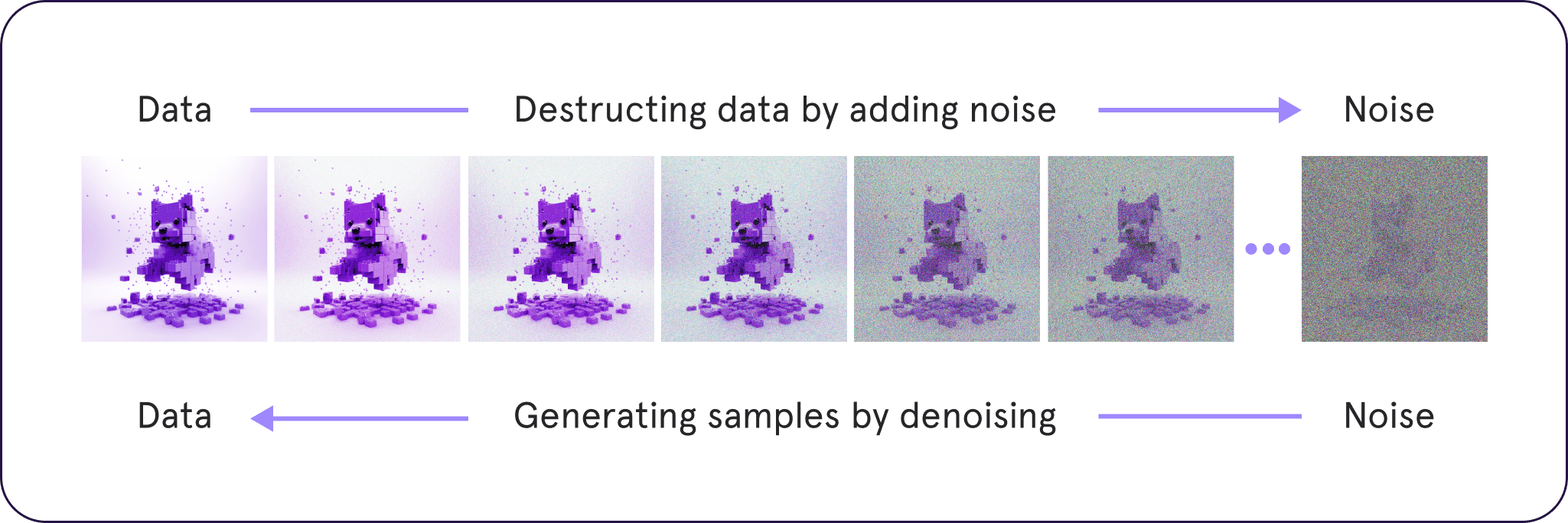
- Diffusion models beginnen met "ruwe" trainingsgegevens en leren om noise te verwijderen
- Anders dan GANs
- Tijdens de training wordt er ruis toegevoegd aan afbeeldingen en het model leert deze ruis te verwijderen.
Bestaande Modellen
Beperkingen
- Facial distortion
- Text generation issues
- Limited Prompt understanding
Impainting
Inpainting is een proces waar diffusiemodellen ontbrekende of "beschadigde" delen van een afbeelding reconstrueren. Door gebruik te maken van de structuur van afbeeldingen, voorspellen deze modellen en vullen ze de gaten in, met een krachtige oplossing voor beeldherstel, -aanpassing of -verbetering.

Outpainting
Outpainting houdt in dat de inhoud van een bestaande afbeelding wordt uitgebreid. Diffusiemodellen bereiken dit door de contextuele relaties binnen de afbeelding te begrijpen.

Types
| Taak | Beschrijving |
|---|---|
| Unconditional Image Generation | genereert een afbeelding van Gaussian Noise |
| Text-Guided Image Generation | genereert een afbeelding met behulp van een tekst prompt |
| Text-Guided Image-To-Image Translation | past een afbeelding aan op basis van een tekst prompt |
| Text-Guided Image-Impainting | past een gemaskeerd deelt van een afbeelding aan met een tekst prompt |
| Text-Guided Depth-to-Image Translation | past een deel van een afbeelding aan via een tekst prompt maar behoudt de structuur en de diepte |
Technology 2 - Transformers & Diffusers
By timdpaep



