





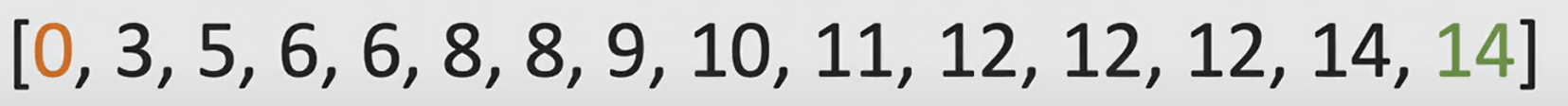

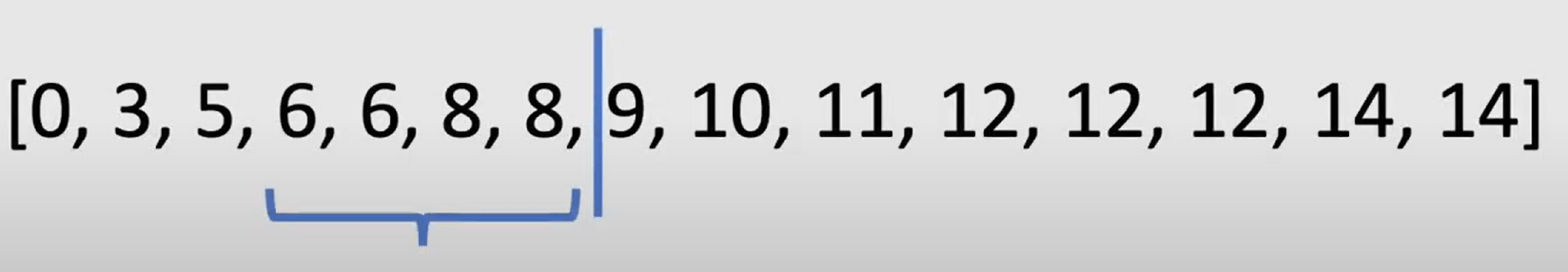



Santiago Quiñones Cuenca
Software Developer and Educator, Master in Software Engineering, Research UTPL {Loja, Ecuador} Repositories: http://github.com/lsantiago
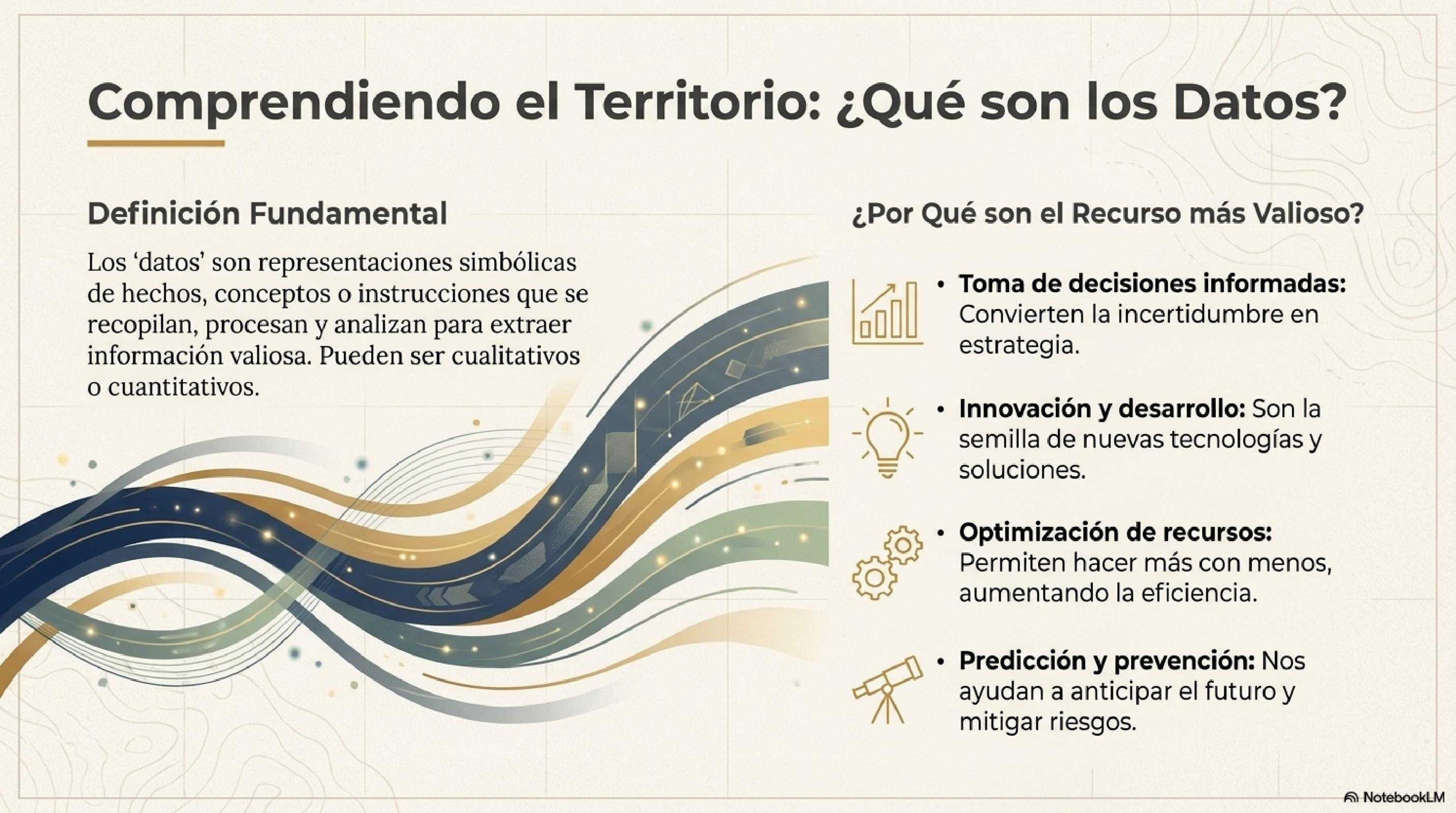
Programación funcional y reactiva - Computación
Datos
Debate en grupos
Grupos A: Beneficios de los datos
Grupos B: Desafios y preocupaciones
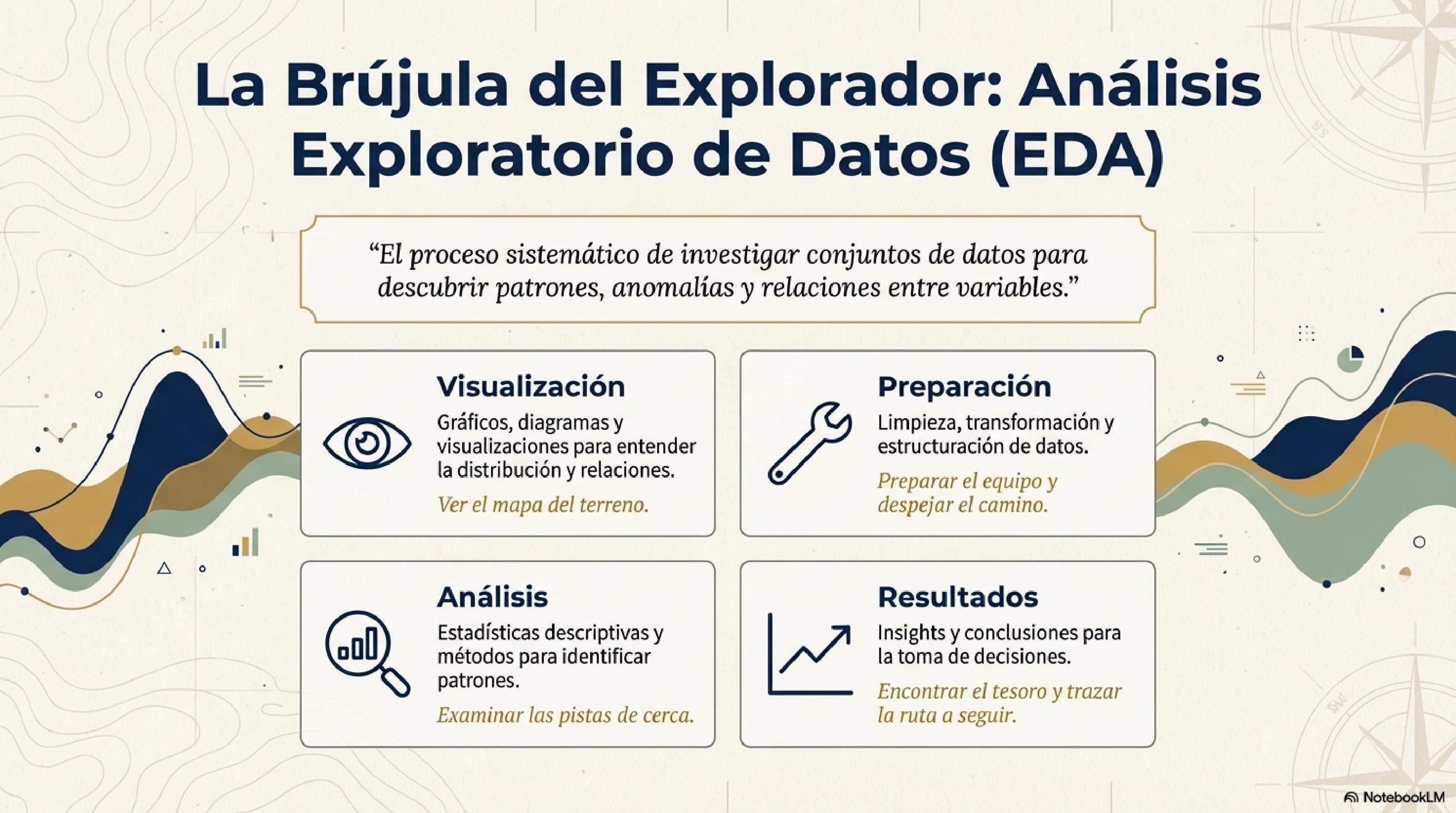
Análisis exploratorio de datos (EDA)
Estadísticas descriptivas
La media: "el promedio"
Estadísticas descriptivas
La media: "el promedio"
package bim2.semana12.json
package clases.bim2.semana11.paraleloc
import cats.effect.{IO, IOApp}
import fs2.text
import fs2.io.file.{Files, Path}
import fs2.data.csv.*
import fs2.data.csv.generic.semiauto.*
// 1. Case class
import models.Goleador
// 2. Derivación semiautomática
given CsvRowDecoder[Goleador, String] = deriveCsvRowDecoder[Goleador]
object Estadisticos:
def promedio(datos: List[Int]): Double =
if datos.isEmpty then 0.0
else datos.sum.toDouble / datos.length
object EDA_Goleador extends IOApp.Simple:
// Ruta al archivo
val filePath = Path("src/main/resources/data/Goleadores_LigaPro_2019.csv")
val run: IO[Unit] =
val lecturaCSV: IO[List[Goleador]] = Files[IO]
.readAll(filePath)
.through(text.utf8.decode)
.through(decodeUsingHeaders[Goleador](';'))
.compile
.toList
lecturaCSV.flatMap { goleadores =>
// Accedemos usando el nombre en mayúsculas (.GOLES)
val colGoles: List[Int] = goleadores.map(_.GOLES)
val resultadoPromedio = Estadisticos.promedio(colGoles)
IO.println("=" * 40) >>
IO.println(s" PROMEDIO DE GOLES: %.2f".format(resultadoPromedio)) >>
IO.println(s" Total de registros: ${goleadores.length}") >>
IO.println("=" * 40)
}.handleErrorWith { error =>
IO.println(s"Error procesando CSV: ${error.getMessage}")
}
Estadísticas descriptivas
El rango: el "tamaño" de los valores, la diferencia entre el valor más grande y el más pequeño
Estadísticas descriptivas
El rango: el "tamaño" de los valores, la diferencia entre el valor más grande y el más pequeño
// Completar el código
object Estadisticos:
def promedio(datos: List[Int]): Double =
if datos.isEmpty then 0.0
else datos.sum.toDouble / datos.length
def rango...
.....
// Invocar dentro del flatmap del Object
val rango = ....Estadísticas descriptivas
Desviación estándar: cuantifica la dispersión del conjunto de datos numéricos
Estadísticas descriptivas
Desviación estándar: cuantifica la dispersión del conjunto de datos numéricos
object Estadisticos:
def promedio(datos: List[Int]): Double =
if datos.isEmpty then 0.0
else datos.sum.toDouble / datos.length
def rango(datos: List[Int]): Int =
if datos.isEmpty then 0
else datos.max - datos.min
def desviacionEstandar(datos: List[Int]): Double =
val prom = promedio(datos)
datos.map(gol => math.pow(gol - prom, 2)).sum / datos.lengthEstadísticas descriptivas
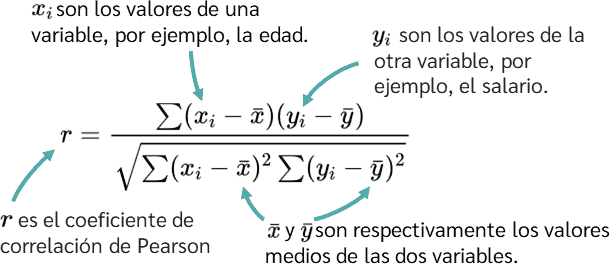
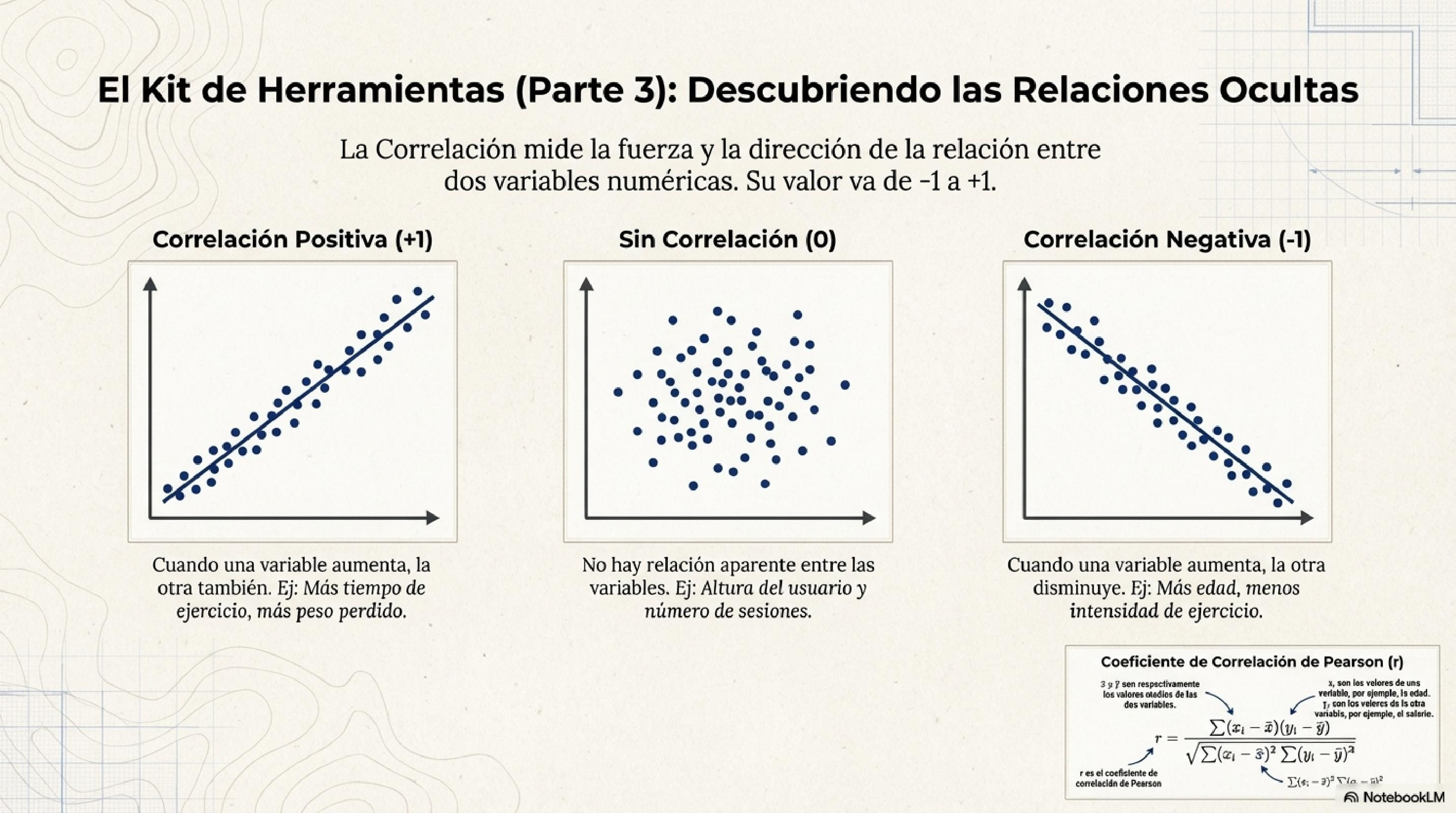
Correlación: Ayuda a entender la relación entre las dos variables numéricas. Mide la fuerza y dirección entre dos variables numéricas
El valor va de -1 a +1:
Estadísticas descriptivas
Correlación: Ayuda a entender entre las dos variables numéricas. Mide la fuerza y dirección entre dos variables numéricas
import scala.math.{sqrt, pow}
// Case class extendido con partidos jugados
case class GoleadorExtendido(
jugador: String,
club: String,
nacionalidad: String,
goles: Int,
autogol: String,
partidos: Int // Nuevo campo
)
object EDA5_correlacion extends App{
// Función para calcular correlación de Pearson
def calcularCorrelacion(x: List[Double], y: List[Double]): Double = {
require(x.length == y.length && x.nonEmpty, "Las listas deben tener el mismo tamaño y no estar vacías")
val n = x.length
val promedioX = x.sum / n
val promedioY = y.sum / n
val numerador = x.zip(y).map { case (xi, yi) =>
(xi - promedioX) * (yi - promedioY)
}.sum
val denominadorX = sqrt(x.map(xi => pow(xi - promedioX, 2)).sum)
val denominadorY = sqrt(y.map(yi => pow(yi - promedioY, 2)).sum)
numerador / (denominadorX * denominadorY)
}
// Simulamos algunos datos de ejemplo (en un caso real, estos vendrían del CSV)
val datos = List(
GoleadorExtendido("Jugador1", "Club A", "ECU", 10, "", 20),
GoleadorExtendido("Jugador2", "Club B", "ARG", 15, "", 25),
GoleadorExtendido("Jugador3", "Club C", "ECU", 8, "", 18),
GoleadorExtendido("Jugador4", "Club D", "COL", 20, "", 30),
GoleadorExtendido("Jugador5", "Club E", "ECU", 12, "", 22)
)
// Extraer listas de goles y partidos
val goles = datos.map(_.goles.toDouble)
val partidos = datos.map(_.partidos.toDouble)
// Calcular correlación
val correlacion = calcularCorrelacion(goles, partidos)
// Mostrar resultados
println(f"Correlación entre goles y partidos jugados: $correlacion%.4f")
// Interpretación de la correlación
val interpretacion = correlacion match {
case r if r > 0.7 => "Correlación positiva fuerte"
case r if r > 0.3 => "Correlación positiva moderada"
case r if r > -0.3 => "Correlación débil o nula"
case r if r > -0.7 => "Correlación negativa moderada"
case _ => "Correlación negativa fuerte"
}
println(s"Interpretación: $interpretacion")
// Mostrar datos para visualización
println("\nDatos:")
println("Jugador Goles Partidos Goles/Partido")
println("-" * 45)
datos.foreach { j =>
val golesPartido = j.goles.toDouble / j.partidos
println(f"${j.jugador}%-15s ${j.goles}%6d ${j.partidos}%9d ${golesPartido}%13.2f")
}
}Limpieza de datos
Proyecto Integrador o bimestral
Comentarios
Uso de Option
¿Por qué usar Option?
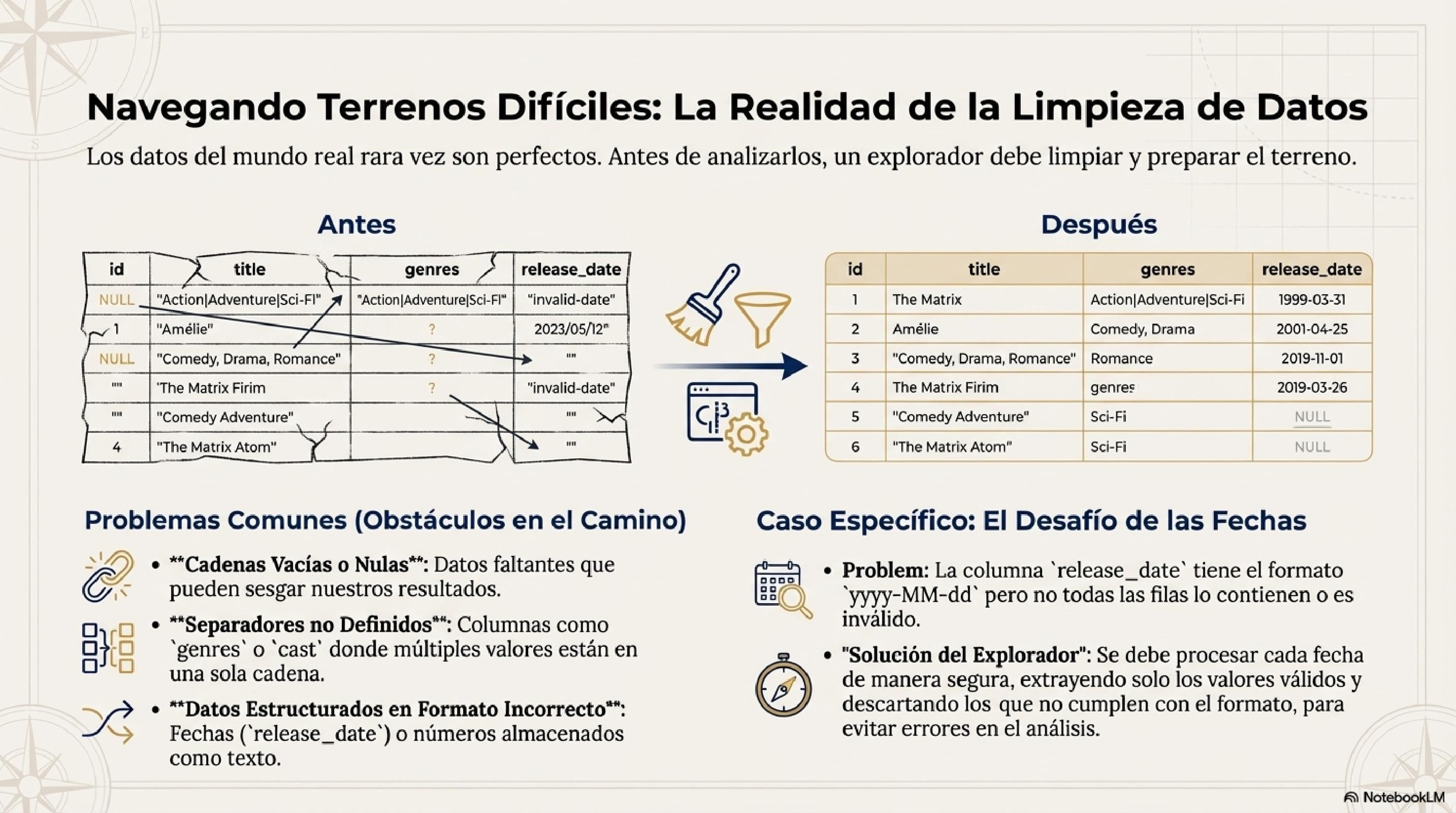
Algunos archivos CSV tienen valores vacíos o inválidos en campos numéricos.
Problema sin Option:
case class Goleador(JUGADOR: String, GOLES: Int)
// Si GOLES está vacío → Error: unable to decode '' as an integerSolución con Option:
case class Goleador(JUGADOR: String, GOLES: Option[Int])
// Si GOLES está vacío → None
// Si GOLES tiene valor → Some(10)CellDecoder personalizado:
given CellDecoder[Option[Int]] = CellDecoder.stringDecoder.map { s =>
s.trim.toIntOption // Retorna None si falla, Some(valor) si es válido
}Uso de Option
Operaciones
Uso de Option
Ejemplo
import cats.effect.{IO, IOApp}
import cats.syntax.all.* // <-- Agregar este import
import fs2.text
import fs2.io.file.{Files, Path}
import fs2.data.csv.*
import fs2.data.csv.generic.semiauto.*
// Case class con GOLES como Option[Int]
case class Goleador(
JUGADOR: String,
CLUB: String,
NACIONALIDAD: String,
GOLES: Option[Int],
AUTOGOL: String
)
// CellDecoder personalizado para Option[Int]
given CellDecoder[Option[Int]] = CellDecoder.stringDecoder.map { s =>
s.trim.toIntOption
}
// Derivación automática del decoder
given CsvRowDecoder[Goleador, String] = deriveCsvRowDecoder[Goleador]
object LeerGoleadoresOption extends IOApp.Simple:
val filePath = Path("src/main/resources/data/goleadores.csv")
val run: IO[Unit] =
Files[IO]
.readAll(filePath)
.through(text.utf8.decode)
.through(decodeUsingHeaders[Goleador](';'))
.compile
.toList
.flatMap { goleadores =>
val golesValidos = goleadores.flatMap(_.GOLES)
val goleadoresConDatos = goleadores.filter(_.GOLES.isDefined)
val goleadoresSinDatos = goleadores.filter(_.GOLES.isEmpty)
val totalGoleadores = goleadores.length
val promedioGoles = if (golesValidos.nonEmpty)
golesValidos.sum / golesValidos.length.toDouble
else 0.0
val maxGoles = golesValidos.maxOption.getOrElse(0)
val goleadorMax = goleadores.find(_.GOLES.contains(maxGoles))
IO.println(s"Total de goleadores: $totalGoleadores") >>
IO.println(s"Goleadores con datos válidos: ${goleadoresConDatos.length}") >>
IO.println(s"Goleadores con datos inválidos: ${goleadoresSinDatos.length}") >>
IO.println(s"Promedio de goles: $promedioGoles") >>
goleadorMax.fold(
IO.println("No se encontró máximo goleador")
)(g => IO.println(s"Máximo goleador: ${g.JUGADOR} con $maxGoles goles")) >>
IO.println("\nRegistros con datos inválidos:") >>
goleadoresSinDatos.traverse_(g =>
IO.println(s" - ${g.JUGADOR} (${g.CLUB})")
)
}JSON
Herramientas
JSONViewer: http://jsonviewer.stack.hu/
Herramientas
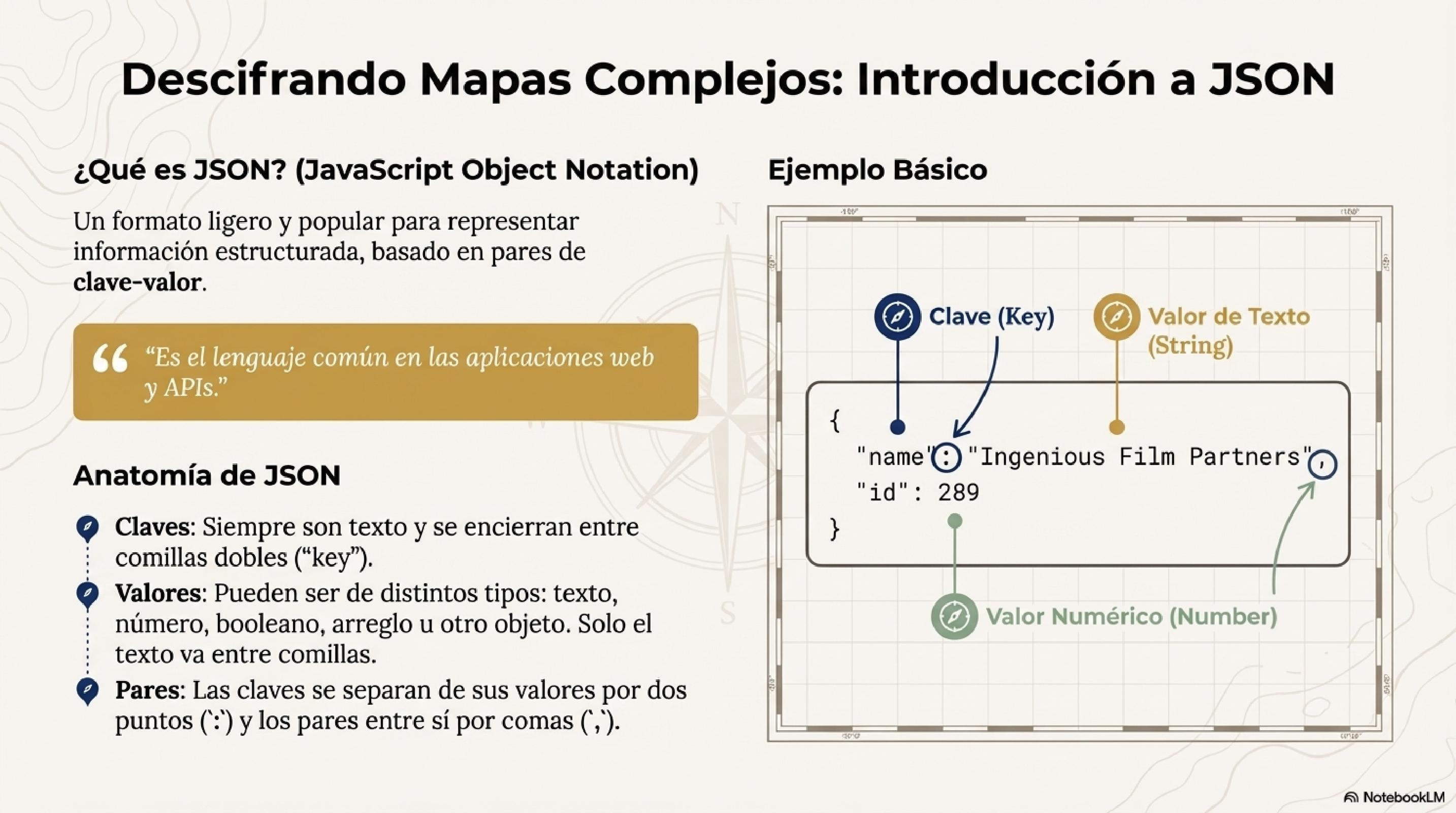
{
"nombre": "Cristina Guaman",
"edad": 30,
"esProfesor": true,
"direccion": {
"ciudad": "Loja",
"pais": "Ecuador"
},
"hobbies": ["leer", "cocinar", "viajar"],
"certificados": null
}
JSON
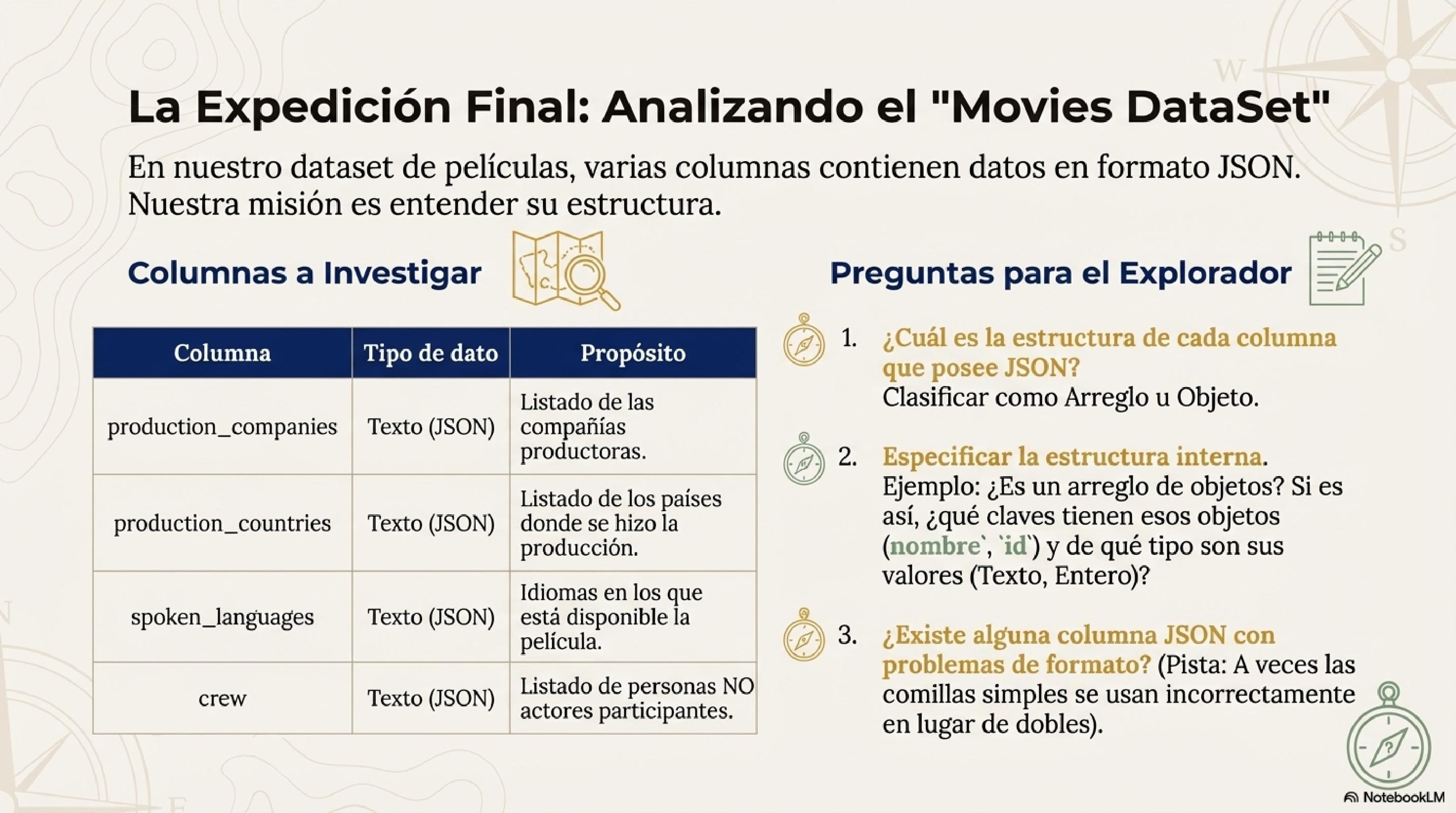
Movies DataSet
JSON
Scala
• Existen varias librerías para trabajar con JSON y Scala
• Una de ellas se denomina Play-JSON, CIRCE
• Información: https://circe.github.io/circe/
ThisBuild / version := "0.1.0-SNAPSHOT"
ThisBuild / scalaVersion := "3.3.7"
val circeVersion = "0.14.10"
lazy val root = (project in file("."))
.settings(
name := "RepasoO25F26",
libraryDependencies ++= Seq(
"io.reactivex" % "rxscala_2.13" % "0.27.0",
"de.tu-darmstadt.stg" %% "rescala" % "0.35.0",
"org.gnieh" %% "fs2-data-csv" % "1.11.1",
"org.gnieh" %% "fs2-data-csv-generic" % "1.11.1", // Para derivación automática
"co.fs2" %% "fs2-core" % "3.12.2",
"co.fs2" %% "fs2-io" % "3.12.2",
"io.circe" %% "circe-core" % circeVersion,
"io.circe" %% "circe-generic" % circeVersion,
"io.circe" %% "circe-parser" % circeVersion
)
)JSON
Ejemplo base
import io.circe._
import io.circe.parser._
import io.circe.generic.auto._ // Importante para la derivación automática
case class Persona(nombre: String, edad: Int, email: Option[String])
object CirceSimple extends App {
// JSON de ejemplo
val jsonString = """
{
"nombre": "Ana García",
"edad": 28,
"email": "ana@email.com"
}
"""
// En Circe, el parseo devuelve un Either[Error, Json]
// Luego usamos .as[Persona] para decodificarlo al case class
val decodeResult = decode[Persona](jsonString)
decodeResult match {
case Right(persona) =>
println(s"Nombre: ${persona.nombre}")
println(s"Edad: ${persona.edad}")
println(s"Email: ${persona.email.getOrElse("No disponible")}")
case Left(error) =>
println(s"Error al parsear el JSON: ${error.getMessage}")
}
}
JSON
JSON con dos registros
import io.circe._
import io.circe.parser._
import io.circe.generic.auto._ // Permite derivar decoders para Listas y Case Classes
case class Persona2(nombre: String, edad: Int, email: Option[String])
// Definimos una clase que represente la estructura raíz del JSON
case class RespuestaPersonas(personas: List[Persona2])
object CirceDosPersonas extends App {
val jsonString = """
{
"personas": [
{
"nombre": "Ana García",
"edad": 28,
"email": "ana@email.com"
},
{
"nombre": "Carlos López",
"edad": 35,
"email": null
}
]
}
"""
// Decodificamos directamente la estructura completa
val decodeResult = decode[RespuestaPersonas](jsonString)
decodeResult match {
case Right(respuesta) =>
respuesta.personas.foreach { persona =>
println(s"\nDatos de persona:")
println(s"Nombre: ${persona.nombre}")
println(s"Edad: ${persona.edad}")
println(s"Email: ${persona.email.getOrElse("No disponible")}")
}
case Left(error) =>
println(s"Error: ${error.getMessage}")
}
}JSON
JSON con problemas
package b2s12.limpieza
import play.api.libs.json._
case class Crew(
name: String,
department: String,
job: String,
profile_path: Option[String]
)
object json_mal_formado extends App {
// JSON mal estructurado como String
val jsonSucio = """
{
'crews': [
{
'name': 'John Smith',
'department': 'Directing',
'job': 'Director',
'profile_path': None
},
{
'name': 'Mary Johnson\\',
'department': 'Production',
'job': 'Producer',
'profile_path': '\\path\\to\\profile'
},
{
'name': 'Peter Parker',
'department': 'Camera',
'job': 'Cinematographer',
'profile_path': None,
'active': True
}
]
}
"""
// Función para limpiar el JSON
def cleanCrewJson(crewJson: String): String = {
crewJson
.trim
.replaceAll("'", "\"") // Reemplazar comillas simples por dobles
.replaceAll("None", "null") // Reemplazar None por null
.replaceAll("True", "true") // Normalizar booleanos
.replaceAll("False", "false")
.replaceAll("""\\""", "") // Eliminar escapes innecesarios
}
implicit val crewFormat = Json.format[Crew]
// Limpiamos y parseamos el JSON
val jsonLimpio = cleanCrewJson(jsonSucio)
val json = Json.parse(jsonLimpio)
// Extraemos la lista de crews
val crews = (json \ "crews").as[List[Crew]]
// Mostramos los resultados
println("Crews procesados:")
crews.foreach { crew =>
println("\nMiembro del equipo:")
println(s"Nombre: ${crew.name}")
println(s"Departamento: ${crew.department}")
println(s"Trabajo: ${crew.job}")
println(s"Perfil: ${crew.profile_path.getOrElse("No disponible")}")
}
// Mostramos el JSON limpio
println("\nJSON limpio generado:")
println(Json.prettyPrint(Json.toJson(Map("crews" -> crews))))
}By Santiago Quiñones Cuenca
Introducción al Análisis exploratorio de datos (EDA) a través de estadísticas básicas.




