








Santiago Quiñones Cuenca
Software Developer and Educator, Master in Software Engineering, Research UTPL {Loja, Ecuador} Repositories: http://github.com/lsantiago
Programación funcional y reactiva - Computación
Archivos CSV
Archivos CSV
"Ejemplo de texto", 123, 456Descripción
Archivos CSV y Scala
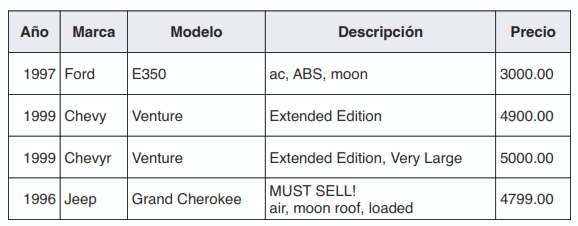
Ejemplo
Año,Marca,Modelo,Descripción,Precio
1997,Ford,E350,"ac, abs, moon",3000.00
1999,Chevyr,Venture,Extended Edition,4900.00
1999,Chevy,Venture,"Extended Edition, Very Large",5000.00
1996,Jeep,Grand Cherokee,"MUST SELL! air, moon roof, loaded",4799.00Archivos CSV y Scala
Paradigma: Procesamiento de flujos (Streams), eficiente en memoria y puramente funcional.
Dependencias (build.sbt):
libraryDependencies ++= Seq(
"org.gnieh" %% "fs2-data-csv" % "1.11.1",
"org.gnieh" %% "fs2-data-csv-generic" % "1.11.1", // Para derivación automática
"co.fs2" %% "fs2-core" % "3.12.2",
"co.fs2" %% "fs2-io" % "3.12.2"
)import cats.effect._ // El motor funcional: gestiona hilos, recursos y ejecución segura.
import fs2.io.file.{Files, Path} // El sistema de archivos: permite leer y escribir archivos en el disco.
import fs2.data.csv._ // El parseador: define las reglas para procesar filas y columnas de CSV.
import fs2.data.csv.generic.semiauto._ // El automatizador: mapea automáticamente columnas de CSV a objetos Scala.Imports:
Archivos CSV y Scala
Leer filas como colección
object LecturaTemperaturas extends IOApp.Simple:
val path = Path("TemperaturasPromedioDecadas.csv")
val run = Files[IO].readUtf8(path)
.through(decodeWithoutHeaders[List[String]](','))
.evalMap(fila => IO.println(fila))
.compile.drain1980, 23, 13, 10, 22, 27, 6, 12, 16, 15, 16, 28, 15
1990, 5, 14, 14, 24, 16, 5, 15, 4, 5, 27, 5, 25
2000, 24, 11, 20, 13, 22, 12, 5, 15, 7, 17, 5, 8
2010, 18, 16, 6, 13, 20, 18, 21, 24, 13, 17, 18, 7
2020, 7, 7, 15, 7, 11, 14, 28, 20, 13, 23, 20, 8Archivos CSV y Scala
Leer filas como colección
Archivos CSV y Scala
Leer filas como colección
import cats.effect.{IO, IOApp}
import fs2.io.file.{Files, Path}
import fs2.data.csv._
object LecturaTemperaturas extends IOApp.Simple:
// 1. Definimos la ubicación del archivo
val path = Path("TemperaturasPromedioDecadas.csv")
// 2. Definimos el flujo de ejecución (Pipeline)
val run: IO[Unit] =
Files[IO].readUtf8(path) // Lee el archivo como texto (UTF-8)
.through(
// Convierte el texto en una lista de Strings, separando por comas
// decodeWithoutHeaders evita que la primera fila se trate como datos
decodeWithoutHeaders[List[String]](',')
)
.evalMap(fila =>
// Por cada fila procesada, realiza la acción de imprimirla
IO.println(s"Procesando fila: $fila")
)
.compile // Junta todos los pasos anteriores en un solo paquete
.drain // Ejecuta el flujo y limpia los recursos al terminarArchivos CSV y Scala
Leer filas como colección
import cats.effect.{IO, IOApp}
import fs2.io.file.{Files, Path}
import fs2.data.csv._
object LecturaTemperaturasALista extends IOApp.Simple:
val path = Path("TemperaturasPromedioDecadas.csv")
val run: IO[Unit] =
val programa: IO[List[List[String]]] =
Files[IO].readUtf8(path)
.through(decodeWithoutHeaders[List[String]](','))
// .evalMap(fila => IO.println(fila)) // Opcional: podrías seguir imprimiendo
.compile
.toList
// Ahora 'programa' devuelve una lista, así que podemos usarla
programa.flatMap { listaCompleta =>
IO.println(s"¡He guardado ${listaCompleta.size} filas en memoria!") >>
IO.println(s"La primera fila es: ${listaCompleta.headOption}")
}Archivos CSV y Scala
Leer filas como colección
import cats.effect.{IO, IOApp}
import fs2.io.file.{Files, Path}
import fs2.data.csv._
object LecturaTemperaturasListaEnteros extends IOApp.Simple:
// 1. Definimos la ubicación del archivo
val path = Path("src/main/resources/data/TemperaturasPromedioDecadas.csv")
// 2. Definimos el flujo de ejecución (Pipeline)
val run: IO[Unit] =
Files[IO].readUtf8(path) // Paso 1: Leer bytes y convertir a texto
.through(
// Paso 2: Decodificar el texto en filas (Listas de Strings)
decodeWithoutHeaders[List[String]](',')
)
.map { fila =>
// Paso 3: Transformación y Limpieza
// .trim elimina espacios accidentales alrededor del número
// .toIntOption devuelve Some(numero) o None si no es un número válido
// .flatMap desempaqueta los Some y descarta los None (filas corruptas)
fila.flatMap(celda => celda.trim.toIntOption)
}
.filter(_.nonEmpty) // Opcional: descarta filas que quedaron vacías tras la limpieza
.evalMap { filaEnteros =>
// Paso 4: Efecto (Imprimir el resultado transformado)
IO.println(s"Fila limpia de enteros: $filaEnteros")
}
.compile // Paso 5: Unificar el pipeline
.drain // Paso 6: Ejecutar y liberar recursosArchivos CSV y Scala
Leer filas como colección
package bim2.semana11
import cats.effect.{IO, IOApp}
import fs2.text
import fs2.io.file.{Files, Path}
import fs2.data.csv.lowlevel.*
object LeerComoLista extends IOApp.Simple:
val filePath = Path("src/main/resources/data/TemperaturasPromedioDecadas.csv")
val run: IO[Unit] =
Files[IO]
.readAll(filePath)
.through(text.utf8.decode)
.through(rows())
.map(row => row.values.toList.map(_.trim.toInt))
.evalMap(row => IO.println(row))
.compile
.drainCase class
Clases y objetos
Breve revisión
Necesitamos escribir mucho código
¿Scala tiene algo parecido?
Clase class
Descripción
Representación simple e inmutable de datos
Compilador crea varios métodos
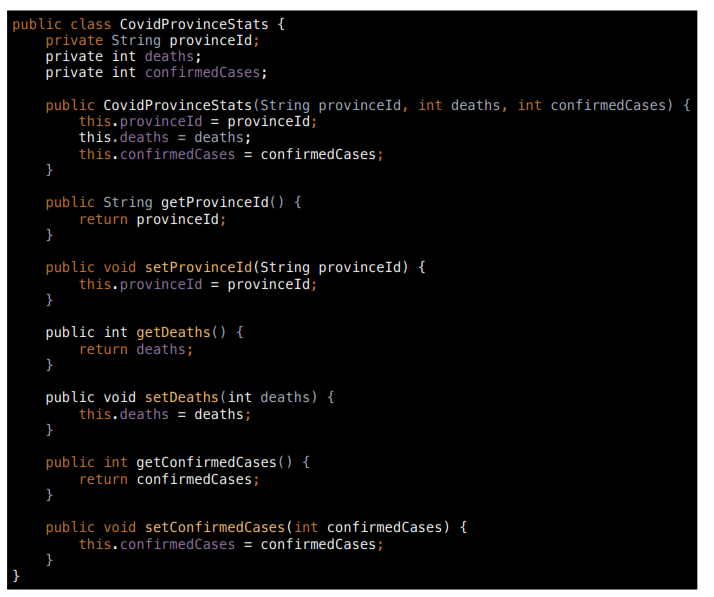
case class CovidProvinceStats(provinceId: String, deaths: Int, confirmedCases: Int)Clase class
Instancias
No se usa el operador new.
No se necesitan métodos de acceso
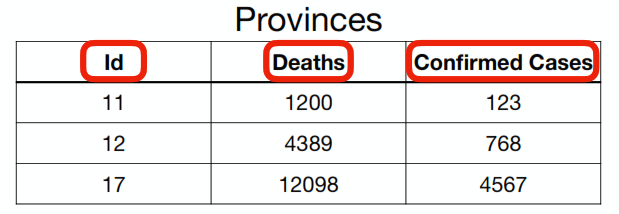
val lojaStats = CovidProvinceStats("11", 1400, 2909)case class CovidProviceStats(provinceId: String, deaths: Int, confirmedCases: Int)lojaStats.provinceIdval lojaStats = CovidProvinceStats("11", 1400, 2909)Clase class
Representación
case Class CovidProvinceStats(pronviceId: String, deaths: Int, confirmedCases: Int)Clase class
Representación
case Class CovidProvinceStats(pronviceId: String, deaths: Int, confirmedCases: Int)Case class y Katan
CSV a case class
val deathsAvg = provincesCovidStat.map(_._2).sum / provincesCovidStat.length.toDoublePara tener un acceso más específico a las filas se puede usar case class
val deathsAvg = provincesCovidStat.map(_.deaths).sum / provincesCovidStat.length.toDouble
Además las tuplas tienen un límite de 22 elementos Tuple22
Case class
Práctica
Usando los datos de los goleadores del copa ecuador 2019 crear una case clase que represente los datos y genera una lista de objetos (case class)
Realice operaciones con la colección de datos (sumas, promedios, valor máximo)
JUGADOR;CLUB;NACIONALIDAD;GOLES;AUTOGOL
AGUIRRE SOTO RODRIGO SEBASTIAN;L.D.U.QUITO;URUGUAYA;12;No
ALEMAN ALEGRIA CHRISTIAN FERNANDO;BARCELONA S.C.;ECUATORIANA;6;No
ALVARADO CARRIEL ALEXANDER ANTONIO;S.D.AUCAS;ECUATORIANA;1;No
ALVEZ SAGAR JONATAN DANIEL;BARCELONA S.C.;URUGUAYA;2;No
AMARILLA LENCINA LUIS ANTONIO;U.CATOLICA;PARAGUAYA;16;No
AMIEVA JUAN MARTIN;MUSHUC RUNA S.C.;ARGENTINA;4;No
ANANGONO LEON JUAN LUIS;L.D.U.QUITO;ECUATORIANA;3;No
ANGULO ARROYO DANIEL PATRICIO;C.S.EMELEC;ECUATORIANA;5;No
ANGULO MEDINA JULIO EDUARDO;L.D.U.QUITO;ECUATORIANA;1;No
ANGULO TENORIO BRYAN DENNIS;C.S.EMELEC;ECUATORIANA;5;No
Lectura CSV con Case Clase
Clave: Los nombres de los campos deben coincidir exactamente con los headers del CSV
package bim2.semana11
import cats.effect.{IO, IOApp}
import fs2.text
import fs2.io.file.{Files, Path}
import fs2.data.csv.*
import fs2.data.csv.generic.semiauto.*
// Case class con nombres iguales a los headers del CSV
case class Goleador(
JUGADOR: String,
CLUB: String,
NACIONALIDAD: String,
GOLES: Int,
AUTOGOL: String
)
// Derivación automática del decoder
// Aprende cómo convertir una fila de texto a un objeto de tipo Goleador
given CsvRowDecoder[Goleador, String] = deriveCsvRowDecoder[Goleador]
object LeerGoleadores extends IOApp.Simple:
val filePath = Path("src/main/resources/data/goleadores.csv")
val run: IO[Unit] =
Files[IO]
.readAll(filePath)
.through(text.utf8.decode)
.through(decodeUsingHeaders[Goleador](';'))
.compile
.toList
.flatMap { goleadores =>
// Estadísticas
val totalGoleadores = goleadores.length
val goles = goleadores.map(_.GOLES)
val promedioGoles = goles.sum / totalGoleadores.toDouble
val maxGoles = goles.max
val goleadorMax = goleadores.find(_.GOLES == maxGoles).get
// Imprimir resultados
IO.println(s"Total de goleadores: $totalGoleadores") >>
IO.println(s"Promedio de goles: $promedioGoles") >>
IO.println(s"Máximo goleador: ${goleadorMax.JUGADOR} con $maxGoles goles")
}
Lectura CSV con Case Clase
Dataset: Goleadores
Clave: Los nombres de los campos deben coincidir exactamente con los headers del CSV
case class Movies(
adult: Boolean,
belongs_to_collection: String,
budget: Int,
....
)
Lectura CSV con Case Clase
Dataset Movies
Lectura CSV con Case Clase
Dataset Movies
import cats.effect.{IO, IOApp}
import fs2.text
import fs2.data.csv.*
import fs2.data.csv.generic.semiauto.*
import fs2.io.file.{Files, Path}
// Case class con solo las columnas que quieres leer
case class Movie(id: String, original_title: String)
// Derivación automática del decoder
given CsvRowDecoder[Movie, String] = deriveCsvRowDecoder[Movie]
object CsvReaderApp extends IOApp.Simple:
val filePath = Path("src/main/resources/data/pi_movies_small.csv")
val run: IO[Unit] =
Files[IO]
.readAll(filePath)
.through(text.utf8.decode)
.through(decodeUsingHeaders[Movie](';'))
.evalMap(movie => IO.println(s"ID: ${movie.id.trim}, Título: ${movie.original_title.trim}"))
.compile
.drainReto
Realizar la lectura del dataset de población.
¿Qué nota de especial en el dataset?
Solución
Utilice herramientas generativas para leer el dataset de población.
Solución
package bim2.semana11.presentacion
package bim2.semana11.presentacion
import cats.effect.{IO, IOApp}
import fs2.text
import fs2.io.file.{Files, Path}
import fs2.data.csv.*
import fs2.data.csv.generic.semiauto.*
// 1. Definimos la Case Class con los nombres exactos de las columnas del CSV.
// Usamos comillas invertidas (backticks) para nombres con espacios o guiones.
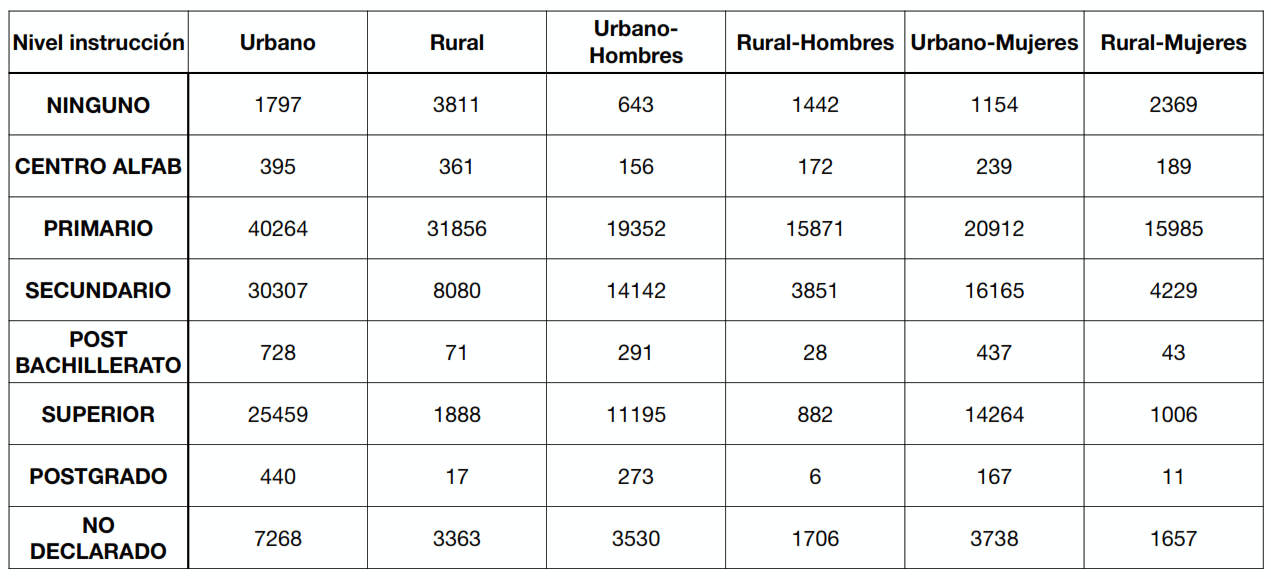
case class PoblacionLoja(
`Nivel instrucción`: String,
Urbano: Int,
Rural: Int,
`Urbano-Hombres`: Int,
`Rural-Hombres`: Int,
`Urbano-Mujeres`: Int,
`Rural-Mujeres`: Int
)
...............Estadísticos - Goleadores
package bim2.semana11.presentacion
import cats.effect.{IO, IOApp}
import fs2.text
import fs2.io.file.{Files, Path}
import fs2.data.csv.*
import fs2.data.csv.generic.semiauto.*
// Case class con nombres iguales a los headers del CSV
case class Goleador(
JUGADOR: String,
CLUB: String,
NACIONALIDAD: String,
GOLES: Int,
AUTOGOL: String
)
// Derivación automática del decoder
given CsvRowDecoder[Goleador, String] = deriveCsvRowDecoder[Goleador]
// ============================================
// Objeto con funciones estadísticas genéricas
// ============================================
object Estadisticos:
def suma(datos: List[Int]): Int = datos.sum
def promedio(datos: List[Int]): Double =
if datos.isEmpty then 0.0
else datos.sum.toDouble / datos.length
def maximo(datos: List[Int]): Int =
if datos.isEmpty then 0
else datos.max
def minimo(datos: List[Int]): Int =
if datos.isEmpty then 0
else datos.min
def conteo[A](datos: List[A]): Int = datos.length
def conteoUnicos[A](datos: List[A]): Int = datos.distinct.length
def frecuencias[A](datos: List[A]): Map[A, Int] =
datos.groupBy(identity).map((k, v) => k -> v.length)
// ============================================
// Objeto principal - Lectura y procesamiento
// ============================================
object EstadisticasGoleador extends IOApp.Simple:
val filePath = Path("src/main/resources/data/Goleadores_LigaPro_2019.csv")
val run: IO[Unit] =
val lecturaCSV: IO[List[Goleador]] = Files[IO]
.readAll(filePath)
.through(text.utf8.decode)
.through(decodeUsingHeaders[Goleador](';'))
.compile
.toList
lecturaCSV.flatMap { goleadores =>
val colGoles: List[Int] = goleadores.map(_.GOLES)
val colClubes: List[String] = goleadores.map(_.CLUB)
val colNacionalidades: List[String] = goleadores.map(_.NACIONALIDAD)
(
IO.println("=" * 55) >>
IO.println(" ESTADÍSTICAS - COLUMNA GOLES") >>
IO.println("=" * 55) >>
IO.println(s" Total registros: ${Estadisticos.conteo(colGoles)}") >>
IO.println(s" Suma total: ${Estadisticos.suma(colGoles)}") >>
IO.println(s" Promedio: %.2f".format(Estadisticos.promedio(colGoles))) >>
IO.println(s" Máximo: ${Estadisticos.maximo(colGoles)}") >>
IO.println(s" Mínimo: ${Estadisticos.minimo(colGoles)}") >>
IO.println("") >>
IO.println("=" * 55) >>
IO.println(" ESTADÍSTICAS - COLUMNA CLUB") >>
IO.println("=" * 55) >>
IO.println(s" Total registros: ${Estadisticos.conteo(colClubes)}") >>
IO.println(s" Clubes únicos: ${Estadisticos.conteoUnicos(colClubes)}") >>
IO.println("") >>
IO.println("=" * 55) >>
IO.println(" ESTADÍSTICAS - COLUMNA NACIONALIDAD") >>
IO.println("=" * 55) >>
IO.println(s" Total registros: ${Estadisticos.conteo(colNacionalidades)}") >>
IO.println(s" Nacionalidades únicas: ${Estadisticos.conteoUnicos(colNacionalidades)}") >>
IO.println("=" * 55)
)
}Uso de Option
¿Por qué usar Option?
Algunos archivos CSV tienen valores vacíos o inválidos en campos numéricos.
Problema sin Option:
case class Goleador(JUGADOR: String, GOLES: Int)
// Si GOLES está vacío → Error: unable to decode '' as an integerSolución con Option:
case class Goleador(JUGADOR: String, GOLES: Option[Int])
// Si GOLES está vacío → None
// Si GOLES tiene valor → Some(10)CellDecoder personalizado:
given CellDecoder[Option[Int]] = CellDecoder.stringDecoder.map { s =>
s.trim.toIntOption // Retorna None si falla, Some(valor) si es válido
}Uso de Option
Operaciones
Uso de Option
Ejemplo
package bim2.semana11.presentacion
package bim2.semana11
import cats.effect.{IO, IOApp}
import cats.syntax.all.* // <-- Agregar este import
import fs2.text
import fs2.io.file.{Files, Path}
import fs2.data.csv.*
import fs2.data.csv.generic.semiauto.*
// Case class con GOLES como Option[Int]
case class Goleador(
JUGADOR: String,
CLUB: String,
NACIONALIDAD: String,
GOLES: Option[Int],
AUTOGOL: String
)
// CellDecoder personalizado para Option[Int]
given CellDecoder[Option[Int]] = CellDecoder.stringDecoder.map { s =>
s.trim.toIntOption
}
// Derivación automática del decoder
given CsvRowDecoder[Goleador, String] = deriveCsvRowDecoder[Goleador]
object LeerGoleadoresOption extends IOApp.Simple:
val filePath = Path("src/main/resources/data/goleadores.csv")
val run: IO[Unit] =
Files[IO]
.readAll(filePath)
.through(text.utf8.decode)
.through(decodeUsingHeaders[Goleador](';'))
.compile
.toList
.flatMap { goleadores =>
val golesValidos = goleadores.flatMap(_.GOLES)
val goleadoresConDatos = goleadores.filter(_.GOLES.isDefined)
val goleadoresSinDatos = goleadores.filter(_.GOLES.isEmpty)
val totalGoleadores = goleadores.length
val promedioGoles = if (golesValidos.nonEmpty)
golesValidos.sum / golesValidos.length.toDouble
else 0.0
val maxGoles = golesValidos.maxOption.getOrElse(0)
val goleadorMax = goleadores.find(_.GOLES.contains(maxGoles))
IO.println(s"Total de goleadores: $totalGoleadores") >>
IO.println(s"Goleadores con datos válidos: ${goleadoresConDatos.length}") >>
IO.println(s"Goleadores con datos inválidos: ${goleadoresSinDatos.length}") >>
IO.println(s"Promedio de goles: $promedioGoles") >>
goleadorMax.fold(
IO.println("No se encontró máximo goleador")
)(g => IO.println(s"Máximo goleador: ${g.JUGADOR} con $maxGoles goles")) >>
IO.println("\nRegistros con datos inválidos:") >>
goleadoresSinDatos.traverse_(g =>
IO.println(s" - ${g.JUGADOR} (${g.CLUB})")
)
}Proyecto Integrador o Bimestral
Proyecto Integrador o bimestral
Entrega 1 - 19 de diciembre de 2025
By Santiago Quiñones Cuenca
Persistencia de datos a través de archivos.




