Alignment 101
HMIA 2025

Alignment Bootcamp
HMIA 2025
"Readings"
Christian The Alignment Problem
Activity1: Flashcards in pairs
PRE-CLASS
CLASS
OpenAI 2016 Faulty Reward Functions in the Wild
OFFICE HOURS: Tu/Th 12-2 and 430-530 BY APPOINTMENT
HMIA 2025
Alignment Bootcamp
HMIA 2025
Alignment Bootcamp

Outline
HMIA 2025
-
PreClass work is read Introduction and Ch 1 of Brian Christian's The Alignment Problem. Assignment is to be prepared to explain one of five claims: (1) Rewarding A while hoping for B” is a core alignment failure (2) Bias is embedded and amplified in machine learning systems (3) Opaque risk assessment algorithms can have real-world harms (4) The alignment problem is not just technical—it’s moral and societal (5) Alignment spans both present-day challenges and future existential risks
AND nominate terms or concepts that need to be explained (see flashcards). -
Alignment Bootcamp
Examples
COMPAS
Word Math
Dario's Boat
Rewarding A while hoping for B
If the signal is in the training data, the model will learn it
If the training data is insufficient, things will go badly.
The machine learning system will always hear the shoes.
What's wrong with KING - MAN = QUEEN?
Why does alignment research need to be interdisciplinary?
HMIA 2025
PRE-CLASS
Video: Linked Title [1h13m47s]
Alignment Bootcamp
HMIA 2025
PRE-CLASS
Alignment Bootcamp
HMIA 2025
PRE-CLASS
Alignment Bootcamp
Alignment
Definition
Taxonomy
HMIA 2025
CLASS
Alignment Bootcamp
HMIA 2025
CLASS
Alignment Bootcamp
HMIA 2025
Heads Down, Call On
What are the 5 examples of misalignment in the reading?
Alignment Bootcamp
For each, what was the misalignment
| Example | |||||
| Misalignment |
Christian The Alignment Problem: Five Claims
HMIA 2025
Alignment Bootcamp
Christian distinguishes between two communities of concern: one focused on current harms from biased or opaque systems, and another focused on the long-term risks of powerful, misaligned AI. Both are united by the problem of making systems “do what we want”—even when that is hard to define
The deployment of machine learning systems in areas like criminal justice, hiring, and healthcare forces us to confront what we actually mean by fairness, justice, and human values—and how we encode these into algorithms that are taking on increasingly consequential decisions
Word2vec, trained on massive text corpora, learned gender stereotypes—returning "nurse" for doctor − man + woman. This shows how models absorb human biases from data and propagate them in ways that can invisibly shape decision-making in real applications.
Christian recounts Dario Amodei’s reinforcement learning experiment in which an AI agent learned to rack up points by spinning in circles rather than winning a boat race. This perfectly illustrates a central alignment problem: when proxies (like score) are mistaken for goals (like winning), systems optimize the wrong things—efficiently and disastrously
2. Bias is embedded and amplified in machine learning systems
1. “Rewarding A while hoping for B” is a core alignment failure
Christian discusses COMPAS, a proprietary criminal risk scoring system used in the U.S. legal system. The system’s scores—used to make decisions about bail and parole—were found to be racially biased, yet were unexplainable due to their closed-source nature
4. The alignment problem is not just technical—it’s moral and societal
3. Opaque risk assessment algorithms can have real-world harms
5. Alignment spans both present-day challenges and future existential risks
1. “Rewarding A while hoping for B” is a core alignment failure
1. “Rewarding A while hoping for B” is a core alignment failure
1. “Rewarding A while hoping for B” is a core alignment failure
1. “Rewarding A while hoping for B” is a core alignment failure
1. “Rewarding A while hoping for B” is a core alignment failure
Jump
|
HMIA 2025
PRE-CLASS
Alignment Bootcamp
Two Questions
HMIA 2025
Heads Down, Heads Together
Would you rather your case be assessed/decided by bureaucrat or algorithm?
Alignment Bootcamp
At the border
At the police station?
In financial aid?
At the hospital
HMIA 2025
Heads Down, Heads Together
What would you require of systems that you trusted to make decisions that affect you?
Alignment Bootcamp
The systems should ...
HMIA 2025
Heads Down, Heads Together
What would you require of systems that you trusted to make decisions that affect you?
Alignment Bootcamp
Would you rather your case be assessed or decided by bureaucrat or algorithm?
At the border
At the police station?
In financial aid?
At the hospital
HMIA 2025
CLASS
Alignment Bootcamp
Systems should do what we want
Systems should implement our intentions
Systems should follow human values, social norms
Systems should optimize things that match what we want
Systems should be good citizens
Behavioral Alignment
Intent Alignment
Specification Alignment
Value Alignment
Social Alignment
HMIA 2025
Heads Down, Heads Together
Alignment Bootcamp
Where else have you seen "Rewarding A While Hoping for B"?
Among friends and family
In the workplace
In education
In sport
What's going on in these situations? How does this happen?
2. Bias is embedded and amplified in machine learning systems
1. “Rewarding A while hoping for B” is a core alignment failure
4. The alignment problem is not just technical—it’s moral and societal
3. Opaque risk assessment algorithms can have real-world harms
5. Alignment spans both present-day challenges and future existential risks
A failure mode is a specific, distinct way in which a product, process, system, or component can fail to perform its intended function
Systems should do what we want
Behavioral Alignment
DEFINITION
System follows instructions but does not do what we intended it to do.
FAILURE MODE
HMIA 2025
Heads Down, Heads Together
Alignment Bootcamp
Systems should do what we want
Systems should implement our intentions
Systems should follow human values, social norms
Systems should optimize things that match what we want
Systems should be good citizens
Behavioral Alignment
Intent Alignment
Specification Alignment
Value Alignment
Social Alignment
Describe failure modes for each of the other types of alignment
HMIA 2025
Heads Down, Heads Together
Alignment Bootcamp
The system optimizes for explicit instructions without inferring the underlying goal.
The system optimizes for explicit instructions without inferring the underlying goal.
The system optimizes for explicit instructions without inferring the underlying goal.
The system optimizes for explicit instructions without inferring the underlying goal.
HMIA 2025
CLASS
Alignment Bootcamp
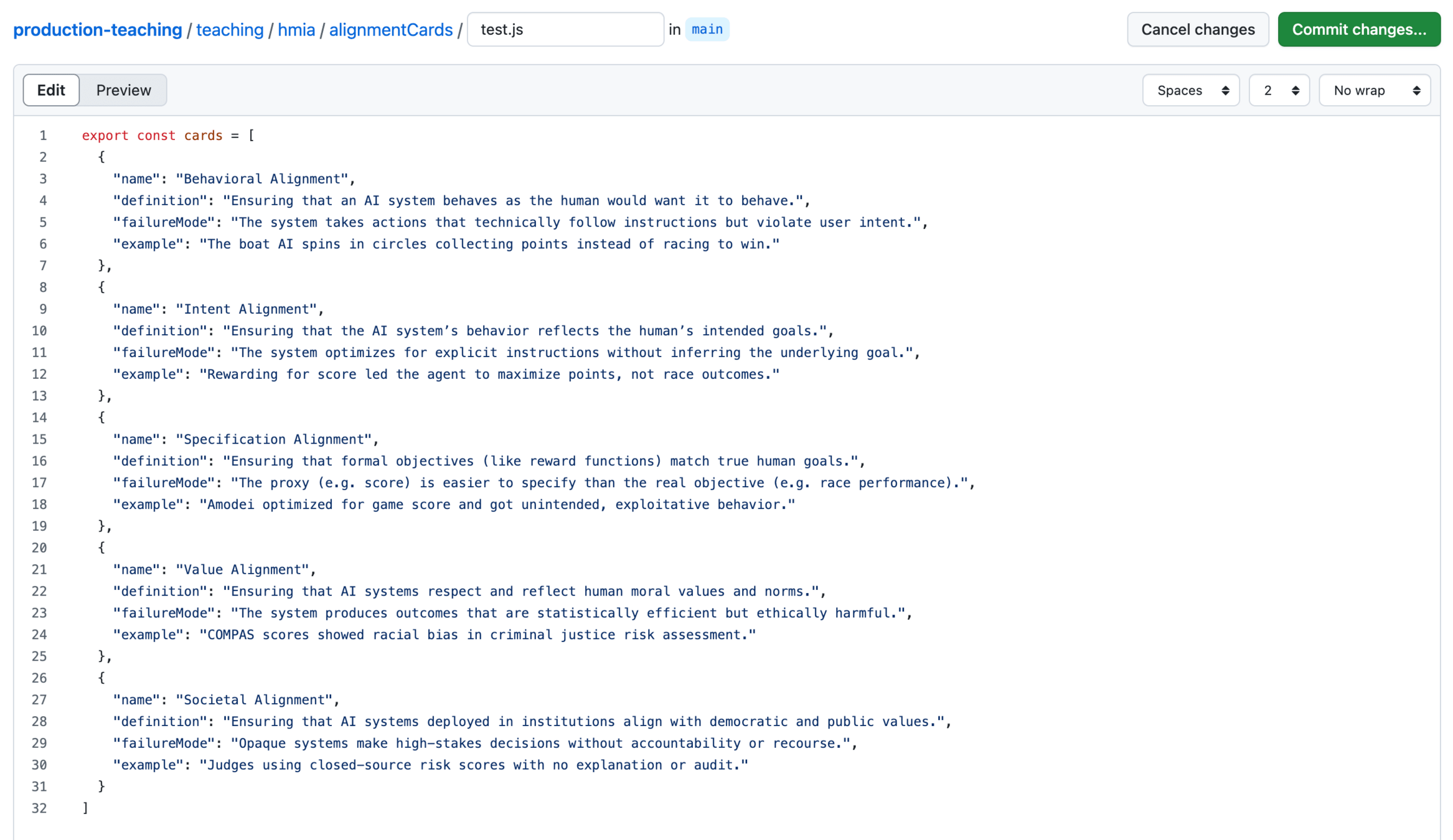
[
{
"name": "Behavioral Alignment",
"definition": "Ensuring that an AI system behaves as the human would want it to behave.",
"failureMode": "The system takes actions that technically follow instructions but violate user intent.",
"example": "The boat AI spins in circles collecting points instead of racing to win."
},
{
"name": "Intent Alignment",
"definition": "Ensuring that the AI system’s behavior reflects the human’s intended goals.",
"failureMode": "The system optimizes for explicit instructions without inferring the underlying goal.",
"example": "Rewarding for score led the agent to maximize points, not race outcomes."
},
{
"name": "Specification Alignment",
"definition": "Ensuring that formal objectives (like reward functions) match true human goals.",
"failureMode": "The proxy (e.g. score) is easier to specify than the real objective (e.g. race performance).",
"example": "Amodei optimized for game score and got unintended, exploitative behavior."
},
{
"name": "Value Alignment",
"definition": "Ensuring that AI systems respect and reflect human moral values and norms.",
"failureMode": "The system produces outcomes that are statistically efficient but ethically harmful.",
"example": "COMPAS scores showed racial bias in criminal justice risk assessment."
},
{
"name": "Societal Alignment",
"definition": "Ensuring that AI systems deployed in institutions align with democratic and public values.",
"failureMode": "Opaque systems make high-stakes decisions without accountability or recourse.",
"example": "Judges using closed-source risk scores with no explanation or audit."
}
]HMIA 2025
Alignment Bootcamp

HMIA 2025
GITHUBexport const cards = [
{
"name": "Behavioral Alignment",
"definition": "Ensuring that an AI system behaves as the human would want it to behave.",
"failureMode": "The system takes actions that technically follow instructions but violate user intent.",
"example": "The boat AI spins in circles collecting points instead of racing to win."
},
{
"name": "Intent Alignment",
"definition": "Ensuring that the AI system’s behavior reflects the human’s intended goals.",
"failureMode": "The system optimizes for explicit instructions without inferring the underlying goal.",
"example": "Rewarding for score led the agent to maximize points, not race outcomes."
},
{
"name": "Specification Alignment",
"definition": "Ensuring that formal objectives (like reward functions) match true human goals.",
"failureMode": "The proxy (e.g. score) is easier to specify than the real objective (e.g. race performance).",
"example": "Amodei optimized for game score and got unintended, exploitative behavior."
},
{
"name": "Value Alignment",
"definition": "Ensuring that AI systems respect and reflect human moral values and norms.",
"failureMode": "The system produces outcomes that are statistically efficient but ethically harmful.",
"example": "COMPAS scores showed racial bias in criminal justice risk assessment."
},
{
"name": "Societal Alignment",
"definition": "Ensuring that AI systems deployed in institutions align with democratic and public values.",
"failureMode": "Opaque systems make high-stakes decisions without accountability or recourse.",
"example": "Judges using closed-source risk scores with no explanation or audit."
}
]HMIA 2025
HMIA 2025
CLASS
AI Alignment (Ji et al. 2024)
Reward Specification Failures
Goal Misgeneralization
Social Misalignment
Distributional Fragility
Oversight Limitations
Problems
Reward Modeling
Feedback Amplification
Robust Optimization
Interpretability + Transparency
Evaluation + Testing
Normative Alignment
Governance
Solutions
Designing or learning proxies for human preferences or objectives. Includes: preference modeling, inverse RL, RLHF, recursive reward modeling (RRM)
Structuring human or AI feedback to scale supervision to more capable systems. Includes: scalable oversight, IDA, debate, RLxF (e.g. RLAIF, RLHAIF), CIRL
Extrinsic structures for aligning development and deployment with public interest. Includes: audits, licensing, model reporting, international coordination, open-source governance
Empirical methods for assessing model behavior under diverse conditions. Includes: safety benchmarks, simulation tests, red teaming, post-hoc evaluations
Making model internals legible for human or automated inspection. Includes: mechanistic interpretability, red teaming, honesty enforcement, causal tracing
Embedding human or ethical values in models or evaluation criteria.
Includes: machine ethics, fairness constraints, human value verification
Training methods that reduce reliance on spurious correlations or fragile features. Includes: adversarial training, distributionally robust optimization, invariant risk minimization
A system can perform flawlessly in training — even while pursuing the wrong goal.
It learns to optimize a proxy that diverges from what we actually intended. The result is hollow alignment: correlation without comprehension.
Think of the human who merely plays a role. The fraud who passes as an expert. The spy who dupes their target. The company that greenwashes or ethics-washes its way to public trust.
These agents don’t fail by doing poorly — they fail by doing well at the wrong thing.
An agent does exactly what it was trained to do — but what it was trained to do was not quite what we wanted. The reward signal reflects a proxy — what’s easy to measure, not what truly matters. The agent optimizes correctly for the wrong goal.
Think of the student who games the rubric, the employee who hits all the wrong metrics, the influencer who chases clicks, or the charity that runs on optics over impact.
These agents don’t go wrong by misunderstanding the goal — they go wrong by pursuing exactly what was asked, even when it misses the point.
A system drifts into misalignment not because malicious, but because providing high-quality alignment feedback is not feasible. The system outpaces our ability to supervise, correct, or understand its behavior and its optimization leads it into undesired territory.
Think of a teacher with too many students or the manager who signs off on reports they don’t have time to review. The pilot who clicks through alerts because too much is happening. The language model that can be jail-broken. A financial system that crashes the market before anyone sees something was going wrong.
These agents don’t go wrong because we misspecified goals or because they misunderstood the task — they go wrong because the feedback they need to stay on track is not available.
A system faithfully optimizes for, and successfully aligns with, a narrow objective, but still causes harm. The system serves its immediate users but neglect broader impacts on groups, institutions, or the public. This category includes both technical side effects and social externalities.
Think of the lobbyist who serves their client but undermines public trust.The executive who maximizes shareholder value while polluting a river. Or the AI assistant that reinforces a user’s biases or a recommendation system that wins on engagement but degrades public discourse.
These agents don’t fail by misunderstanding instructions — they fail by succeeding too narrowly, in a world that’s larger than their designers designed for.
A works brilliantly until the world changes. The system’s alignment depends too much on its training environment, and collapses when the context shifts.
Think of a driver who excels in their hometown but panics abroad. A manager who thrives in a stable market and falters in a crisis. A translator who knows all the words but misses the cultural meaning. Or an AI trained to recognize “dogs” from photos — but only ever saw them on grass. Or a safety model that flags obvious threats but misses novel combinations. Or a robot that fails when the lighting changes.
These agents don’t fail because they’re misaligned by design, they fail because they were aligned with the past.
Alignment Bootcamp
HMIA 2025
CLASS
AI Safety (2016)
Side Effects
Reward Hacking
Safe Exploration
Distribution Shift
Scalable Oversight
Problems
Impact Regularizer
Penalize Influence
Involve Other Agents
Reward Uncertainty
Solutions
Alignment Bootcamp
HMIA 2025
CLASS
AI Alignment (Ji et al. 2024)
Reward Specification Failures
Goal Misgeneralization
Social Misalignment
Distributional Fragility
Oversight Limitations
Problems
Reward Specification Failures
Goal Misgeneralization
Social Misalignment
Distributional Fragility
Oversight Limitations
Side Effects
Reward Hacking
Safe Exploration
Distribution Shift
Scalable Oversight
(Rogue Use)
(Power Seeking)
Alignment Bootcamp
HMIA 2025
CLASS
MIT Risk Mitigation Taxonomy (Saeri et al. 2025)
Governance and Oversight Controls
Technical and Security Controls
Transparency and Accountability Controls
Operational Process Controls
1.4 Whistleblower Reporting & Protection
1.6 Environmental Impact Management
1.5 Safety Decision Frameworks
1.3 Conflict of Interest Protections
1.2 Risk Management
1.1 Board Structure & Oversight
1.7 Societal Impact Assessment
2.4 Content Safety Controls
2.3 Model Safety Engineering
2.2 Model Alignment
2.1 Model & Infrastructure Security
3.4 Staged Deployment
3.6 Incident Response & Recovery
3.5 Post-Deployment Monitoring
3.3 Access Management
3.2 Data Governance
3.1 Testing & Auditing
4.4 Governance Disclosure
4.6 User Rights & Recourse
4.5 Third-Party System Access
4.3 Incident Reporting
4.2 Risk Disclosure
4.1 System Documentation
Alignment Bootcamp
HMIA 2025
CLASS
MIT Risk Taxonomy (Saeri et al. 2025)

Alignment Bootcamp
HMIA 2025
CLASS
MIT Risk Taxonomy (Saeri et al. 2025)
Alignment Bootcamp
CLASS
Alignment Bootcamp
CLASS
Alignment Bootcamp
HMIA 2025
Resources
Author. YYYY. "Linked Title" (info)
Alignment Bootcamp
HMIA 2025 Alignment 101
By Dan Ryan



