









Content ITV PRO
This is Itvedant Content department
Learning Outcome
4
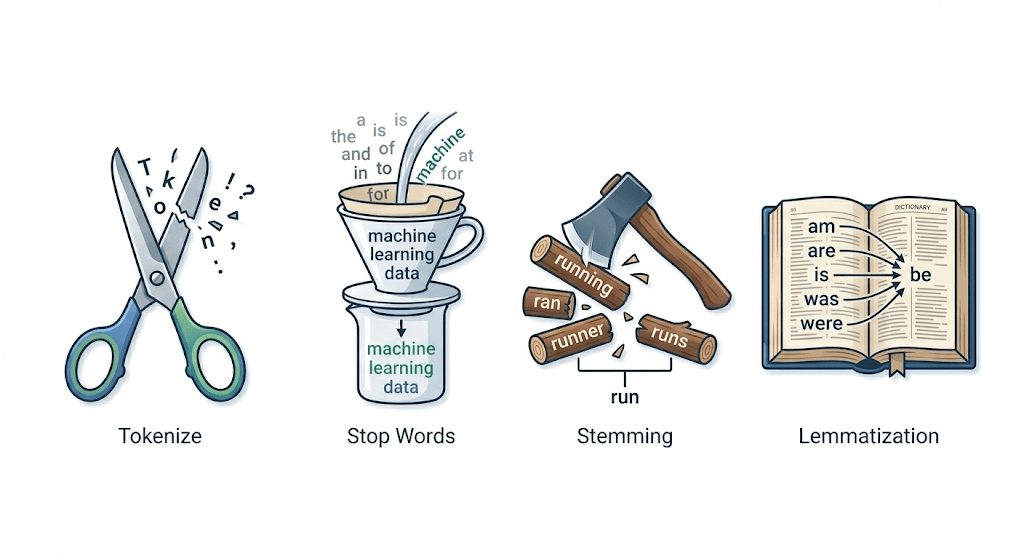
Differentiate between Stemming (chopping) and Lemmatization (contextual root-finding).
3
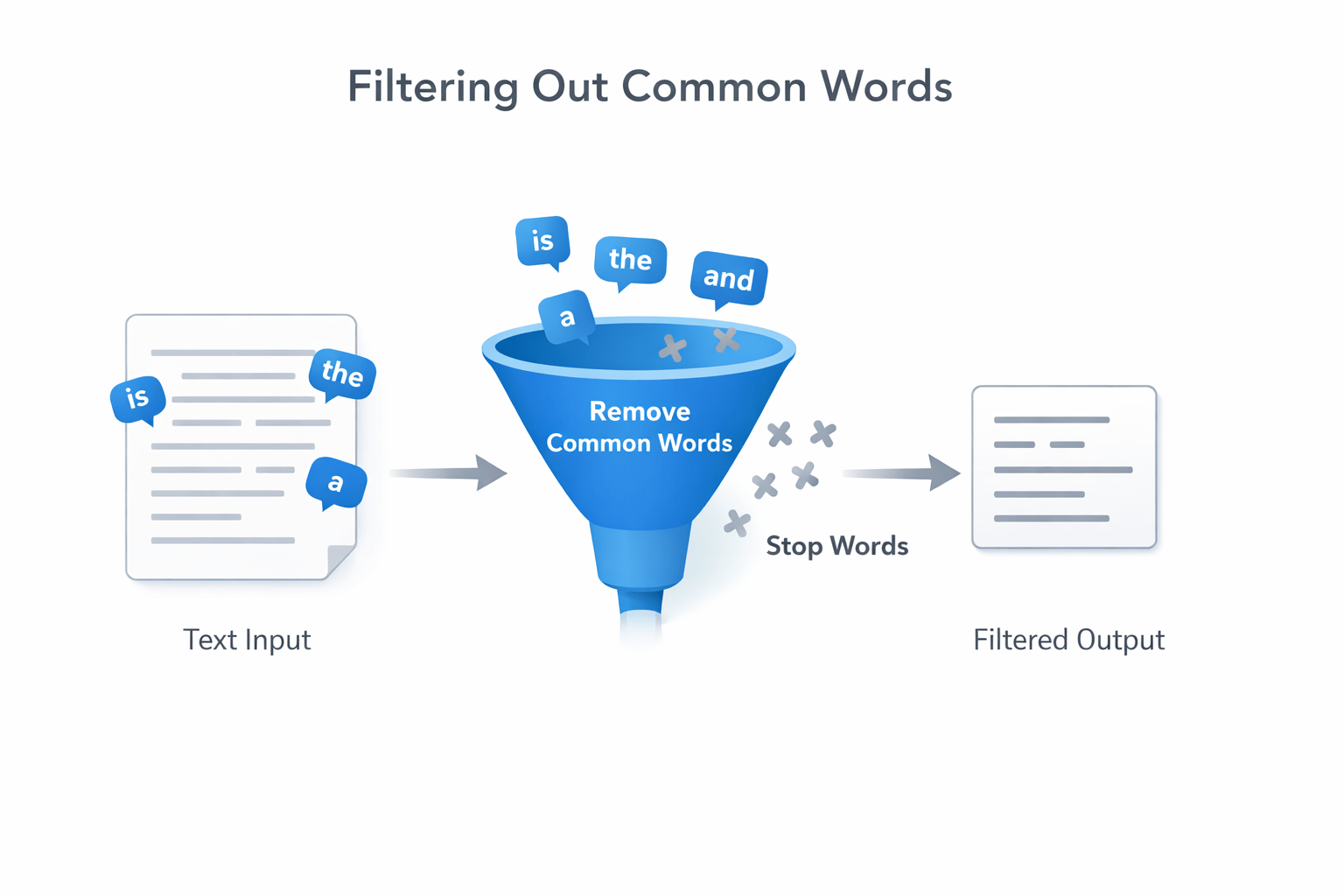
Filter out linguistic "noise" using Stop Word removal.
2
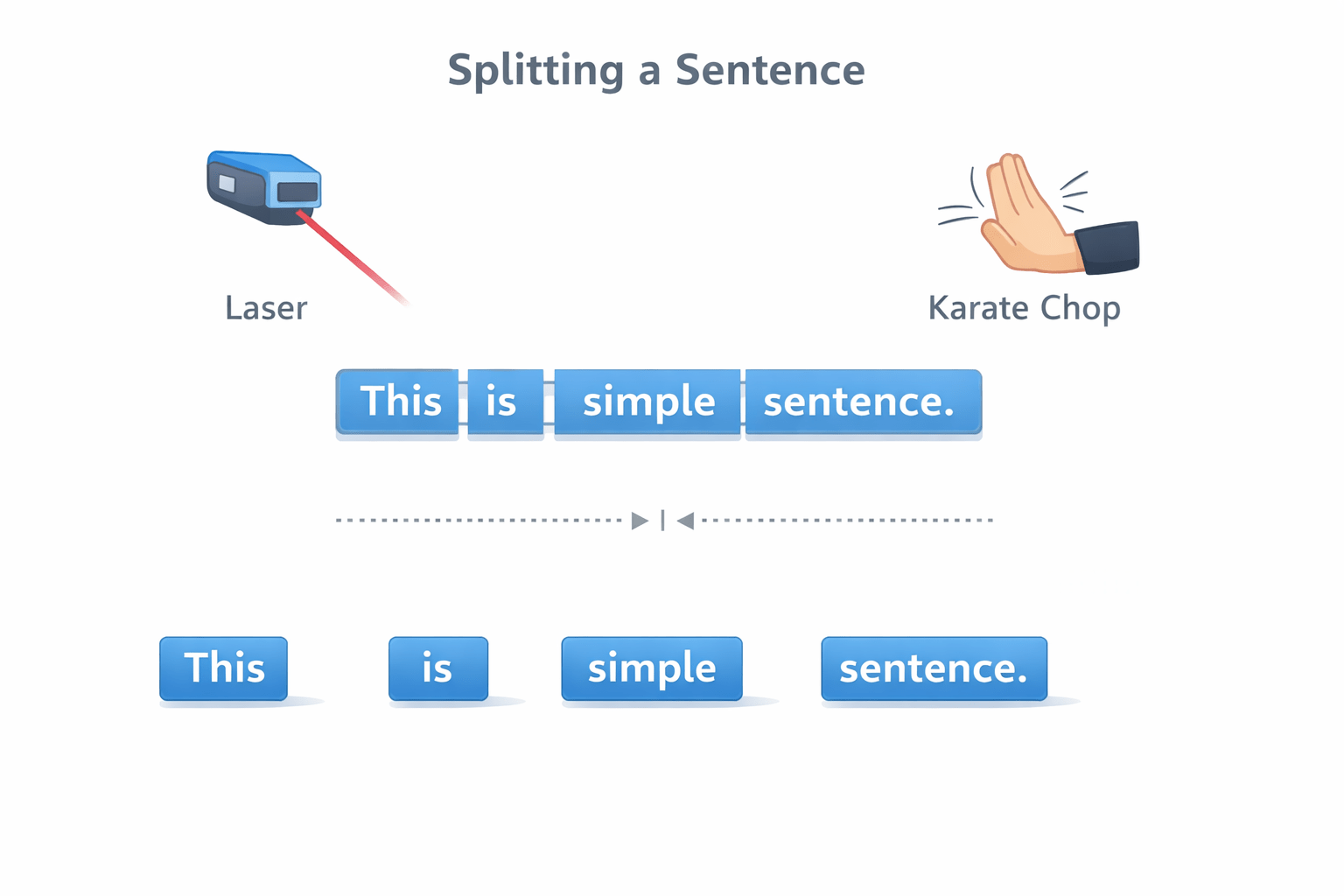
Execute Tokenization to break text into atomic units.
1
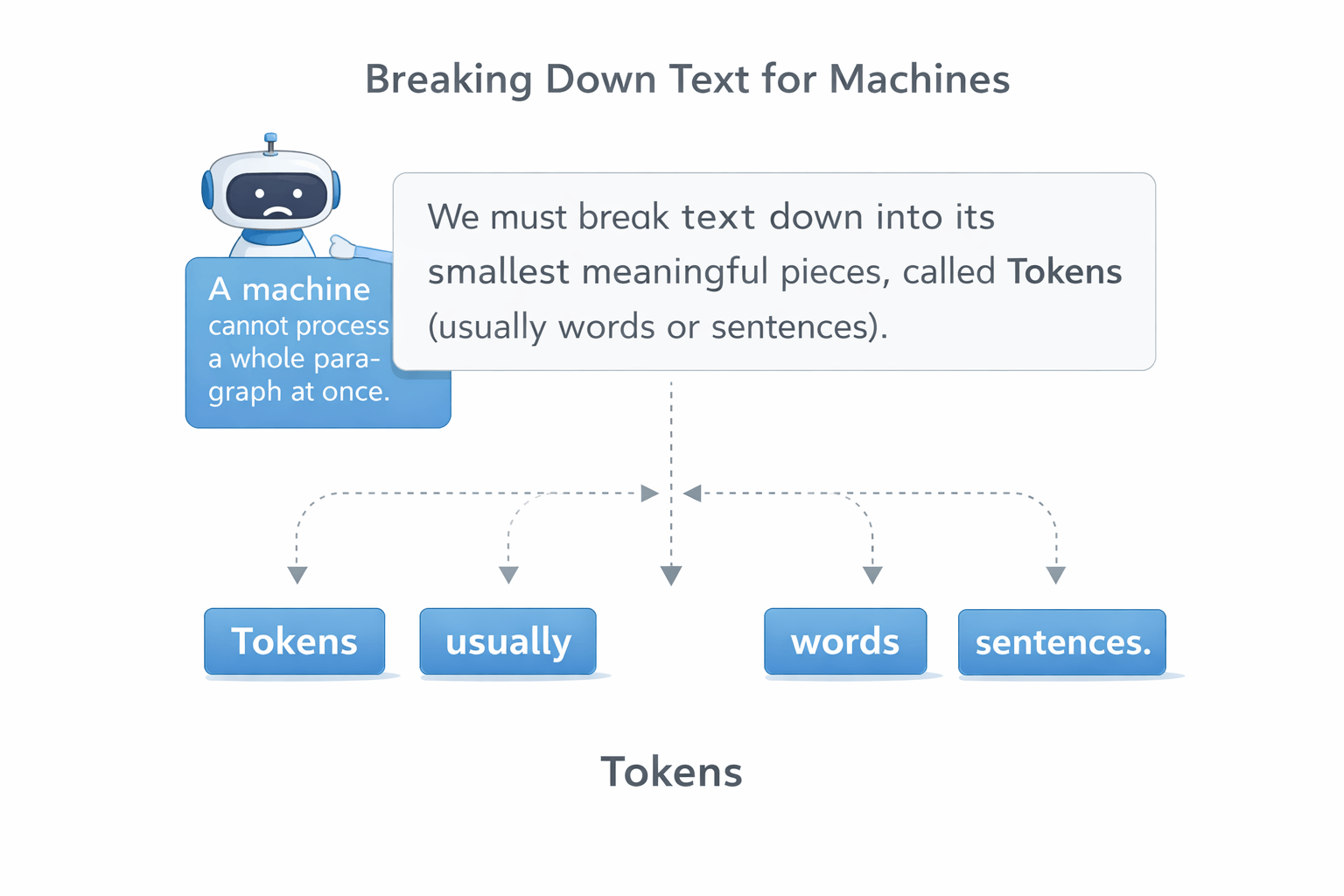
Explain why raw text must be cleaned before entering a ML model.
Recall
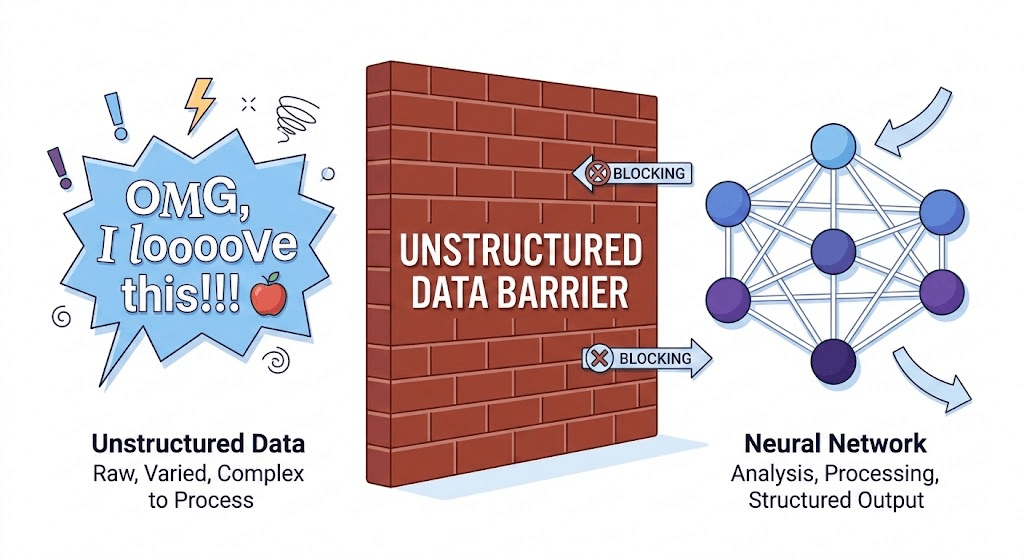
We learned that Neural Networks only speak math.
If we convert "Apple", "apple!", and "Apples" into numbers right now, the computer will think they are three completely different concepts.
We know our goal is to turn words into numbers (Vectorization).
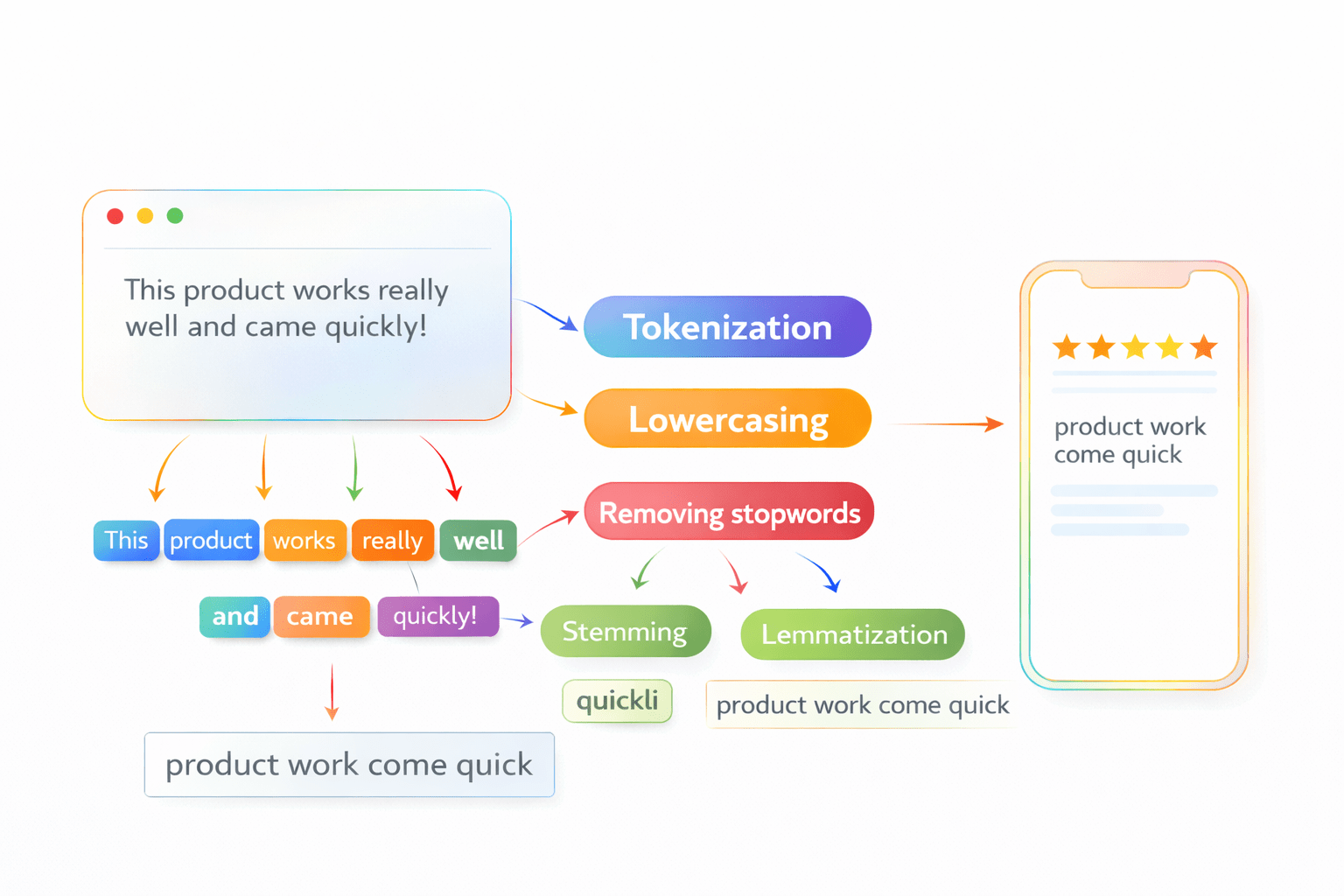
Before we can translate text into numbers, we must standardize it. We must clean the data.
Look at these two sentences:
-----------------------------------------------------
| RAW HUMAN TEXT | CLEAN MACHINE TEXT |
-----------------------------------------------------
| "The SpaceX Falcon 9 launch | the spacex falcon 9 |
| was INCREDIBLE!!! 🚀 #Space" | launch was incredible|
| | space |
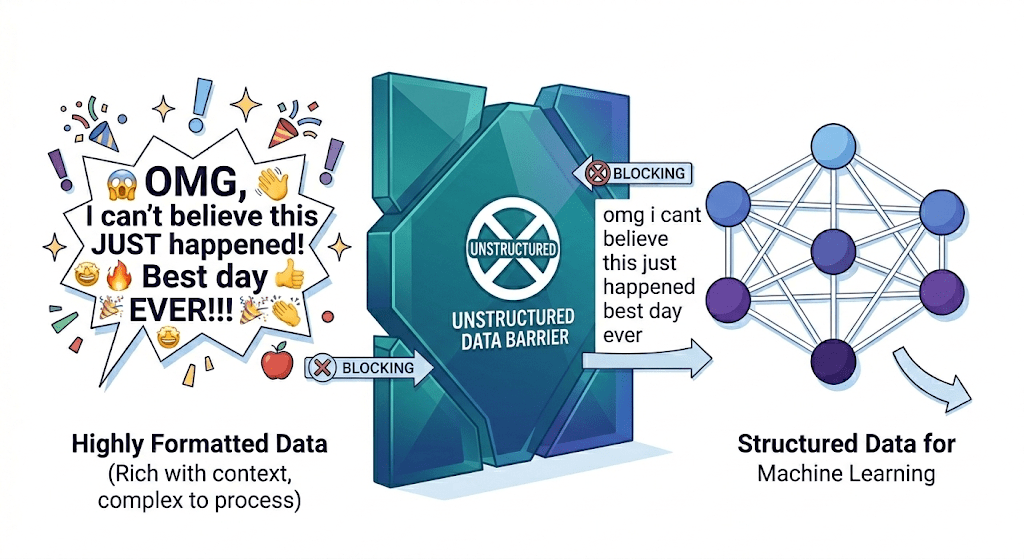
-----------------------------------------------------“Human Expression (Noisy Data)”
👤
Text Preprocessing Pipeline
🤖“Machine-Ready Data (Clean Text)”
“Human Expression (Noisy Data)”
👤
Text Preprocessing Pipeline
🤖“Machine-Ready Data (Clean Text)”
🔤 (lowercase)
❌ ! ? (remove punctuation)
🚫 😊 (remove emoji)
#❌ (remove hashtags)
Machines cannot understand emotion, tone, or emphasis — It only understand patterns and tokens.
We need a systematic way to strip away the "human emotion" and leave only the "core data."
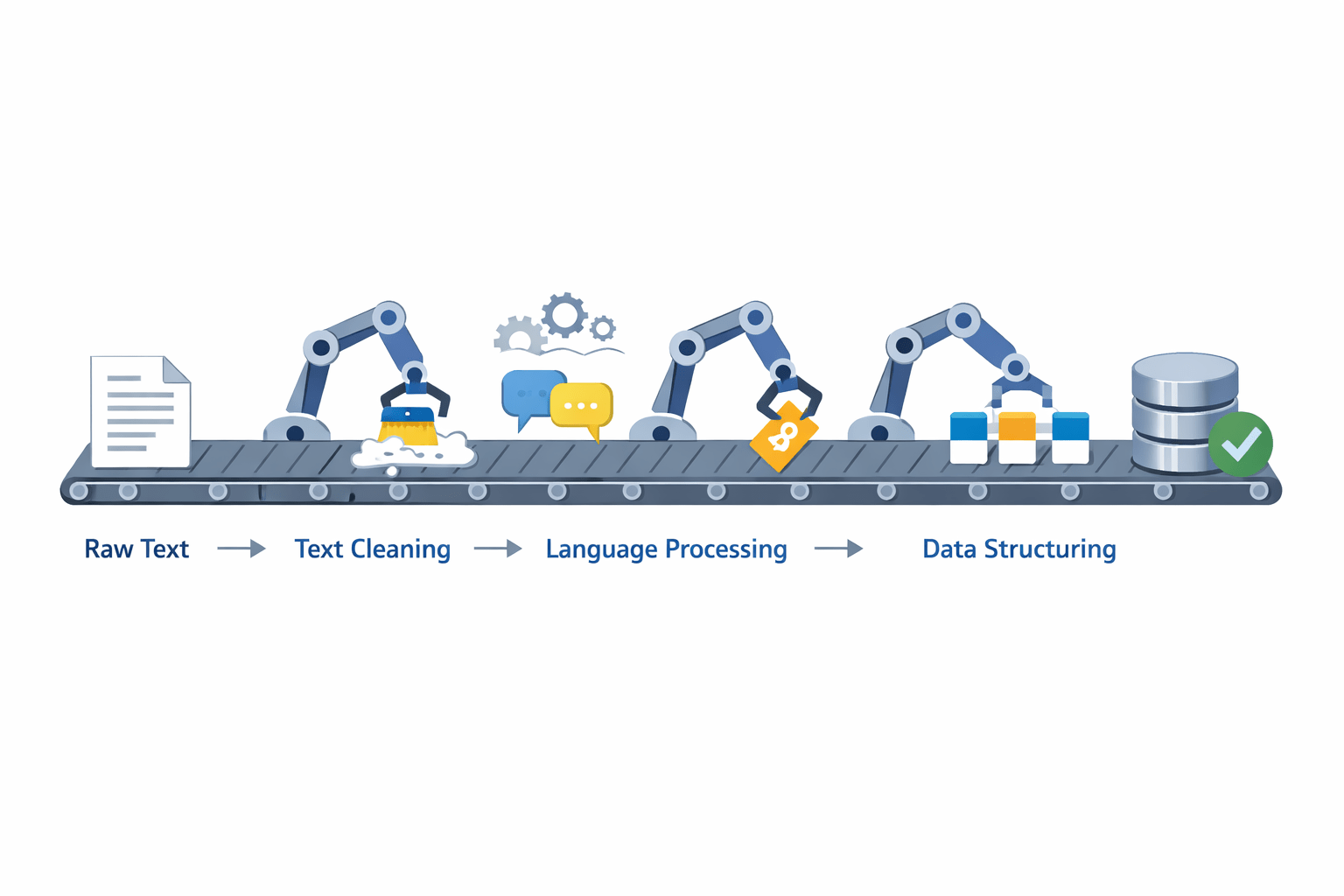
This is where preprocessing comes into the picture.
The Flow of Data:
Text preprocessing is not just one action; it is a step-by-step assembly line.
Inside the Concept
from nltk.tokenize import word_tokenize
text = "SpaceX is going to Mars!"
print(word_tokenize(text))
# Output: ['SpaceX', 'is', 'going', 'to', 'Mars', '!']
from nltk.tokenize import word_tokenize
text = "SpaceX is going to Mars!"
print(word_tokenize(text))
# Output: ['SpaceX', 'is', 'going', 'to', 'Mars', '!']
The words like “is,” “the,” “and,” “a” appear frequently but add little meaning for ML models, so we remove them to save computational power.
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
clean_tokens = [w for w in tokens if w.lower() not in stop_words]
Reducing words to their base or root form.
It uses strict, rule-based chopping. It just cuts off the end of words (like "-ing" or "-ed").
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem("running")) # Output: run
a
It reduces words to their root form (the "Lemma"), but uses a vocabulary and morphological analysis (context).
How it works: It knows that "better" is actually the root of "good", and "caring" comes from "care", not "car".
a
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
print(stemmer.stem("running")) # Output: run
Which one to choose?
| Original Word | Stemming Output (Axe) | Lemmatization Output (Brain) |
|---|---|---|
| Caring | Car ❌ | Care ✅ |
| Geese | Gees ❌ | Goose ✅ |
Summary
4
A glowing, pristine box of perfectly organized word blocks is handed to a robot representing the ML model.
3
Next stop: Vectorization — our clean text is now ready to be converted into numbers.
2
The result is a clean list of lowercase root words without punctuation or stop words.
1
The Transformation: We started with messy, emotional human text.
Quiz
You are building an NLP model and you need the word "worse" to be converted to its root form "bad". Which technique MUST you use?
A. Tokenization
B. Stop Word Removal
C. Stemming
D. Lemmatization
Quiz
You are building an NLP model and you need the word "worse" to be converted to its root form "bad". Which technique MUST you use?
A. Tokenization
B. Stop Word Removal
C. Stemming
D. Lemmatization
By Content ITV



