How do LLMs (really) understand our code?
Vincent Ogloblinsky - @vogloblinsky
Vincent Ogloblinsky
Compodoc maintainer


Web software architect
Indie hacker on side-projects


Disclaimer
The following is merely a "technical" view from a developer's perspective.
I don't have a background in data science. 😉
Some topics are not covered.
I simply try to answer : what is the magic inside LLMs ?
Agenda
1.
Training
2.
Tokenization
3.
Attention mechanism
4.
Limits
5.
Practical takeaways
Training

Training
Billions of lines of code seen during pre-training, in datasets like Alpaca or CodeAlpaca

Fine-tuning on correction and instruction-following tasks
This is where "understanding" is built — not in the architecture
Training
{
"instruction": "Fix the bug in this Python function.",
"input": "def add(a, b):\n return a - b",
"output": "def add(a, b):\n return a + b",
"quality_score": 4.7
}Quality scores — used to filter or weight examples during training
{
"instruction": "Fix the bug in this Python function.",
"input": "def add(a, b):\n return a - b",
"reasoning": "The operator is `-` but the function is named `add`, so it should be `+`.",
"output": "def add(a, b):\n return a + b"
}Explanations / chain-of-thought — teaches the model why, not just what
Training
{
"instruction": "Fix the bug in this Python function.",
"input": "def add(a, b):\n return a - b",
"chosen": "def add(a, b):\n return a + b",
"rejected": "# This function has a bug\ndef add(a, b):\n return a - b"
}Preference pairs — used specifically for RLHF (Reinforcement Learning from Human Feedback)
Tokenization

Tokenization
The model never sees your code as text
Code is split into tokens, throught the algorithm BPE — Byte Pair Encoding
function getUserById(id) {
return users.find(u => u.id === id);
}g e t U s e r B y I d
ge t U se r B y I d
get U ser B y I d
get User By Id
get User By Id
Everything begins at the character level
Merge the most frequent pairs
Tokenization
function getUserById(id) {
return users.find(u => u.id === id);
}function get User By Id ( id ) {
return users . find ( u => u . id === id ) ;
}Common keywords (function, return, const)
→ usually one token because they appeared constantly in training data
Common code patterns get "cheap" compact tokens.
Rare code gets fragmented, and is harder for the model to reason about.
More tokens a concept is split into, more attention steps are needed to reconstruct its meaning.
Attention mechanism

Attention mechanism
What weight has each token in the code ?
Attention != understanding
Learned ability "where to look" but no AST, scope or call stack meaning
Attention mechanism
function add(a, b) {
return a - b;
}
const result = add(3, 2);Hey Houston, we have a bug here ?
Attention mechanism
function add(a, b) {
return a - b;
}
const result = add(3, 2);
Tokenization
. are space in tokens
How LLM understand .- contradicts .add ?
Attention mechanism
function add(a, b) {
return a - b;
}
const result = add(3, 2);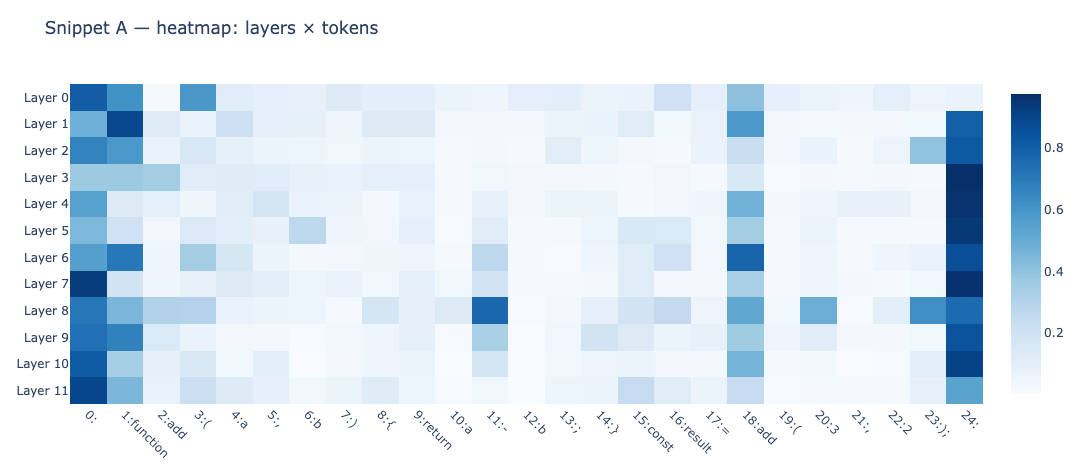
Attention mechanism
Layers are sequential, input of one is the output of the previous one
Layers 0-2 : local patterns, immediate syntax, punctuation
Layers 3-5 : Structure — scope of blocks {}, pairs (), position in the declaration
Layers 6-8 : Semantics — relationships between nouns and what they do (add → return, add → -)
Layers 9-11 : Abstraction — global representation of the function, useful for generation
Attention mechanism
Attention head : one instance of Query/Key/Value ; all in parallel -> GPU
Each token produces three vectors: a Query ("what am I looking for?"), a Key ("what do I contain?"), and a Value ("what do I contribute?").
Attention score for each token = result of math operation Query(A) * Key(B)
A token vector is now enriched with the context of the tokens it has waited for the most.
Each token asks the others "who are you and what do you bring to the table?", collects their answers weighted by relevance, and comes out enriched — and this, 12 times in parallel, on 12 layers in sequence.
Attention mechanism
At the end, you can literally see the order in which understanding is built.
Why 12 : an hyperparameter / design choice
GPT-3 : 96 layers, 96 heads, 128 dimensions / head
Claude : ~100+ layers, ~100+ heads
Attention mechanism
The LLM "understands" that function add is a substraction.
Not "humanly" correct -> semantic error
LLM has seen this line/code millions of time
function add(a, b) { return a + b; }For the fix, LLM scanning the code, predict that + is better for this function than -
Attention mechanism
Context window linked with attention
Context window is the size of the sequence on which attention can operate in one pass.
Quality decrease when context is large
- dilution : important connections are not so visible
- distance : token 1 & token 180 000 ??? the distance > than during training
Sending 10 000 lines of code for fixing one function is not a good idea
It's not just a matter of tokens saved — it's a matter of attention signal density.
Limits

Limits
Misleading names: it follows the patterns, not the logic
const addition = (a, b) => a * b;Invented API that "looks" real
Context engineering and fresh datas helps a lot !
Thanks for your attention !
Any questions ?
Slides : https://bit.ly/4svoJNz
Crédit photos - Unsplash.com
How LLMs (really) understand our code ?
By Vincent Ogloblinsky
How LLMs (really) understand our code ?
Tokenization, attention mechanism: understanding what really happens when an LLM edits your code.



