Alyx:
Lessons Learned From Building and Evaluating
an Agent in Production at
What are we talking about?
- What is Alyx?
-
Lessons:
-
Staying on task
-
Context management
-
Crystallizing good behavior
-
Debugging a real agent
-
What is AX?
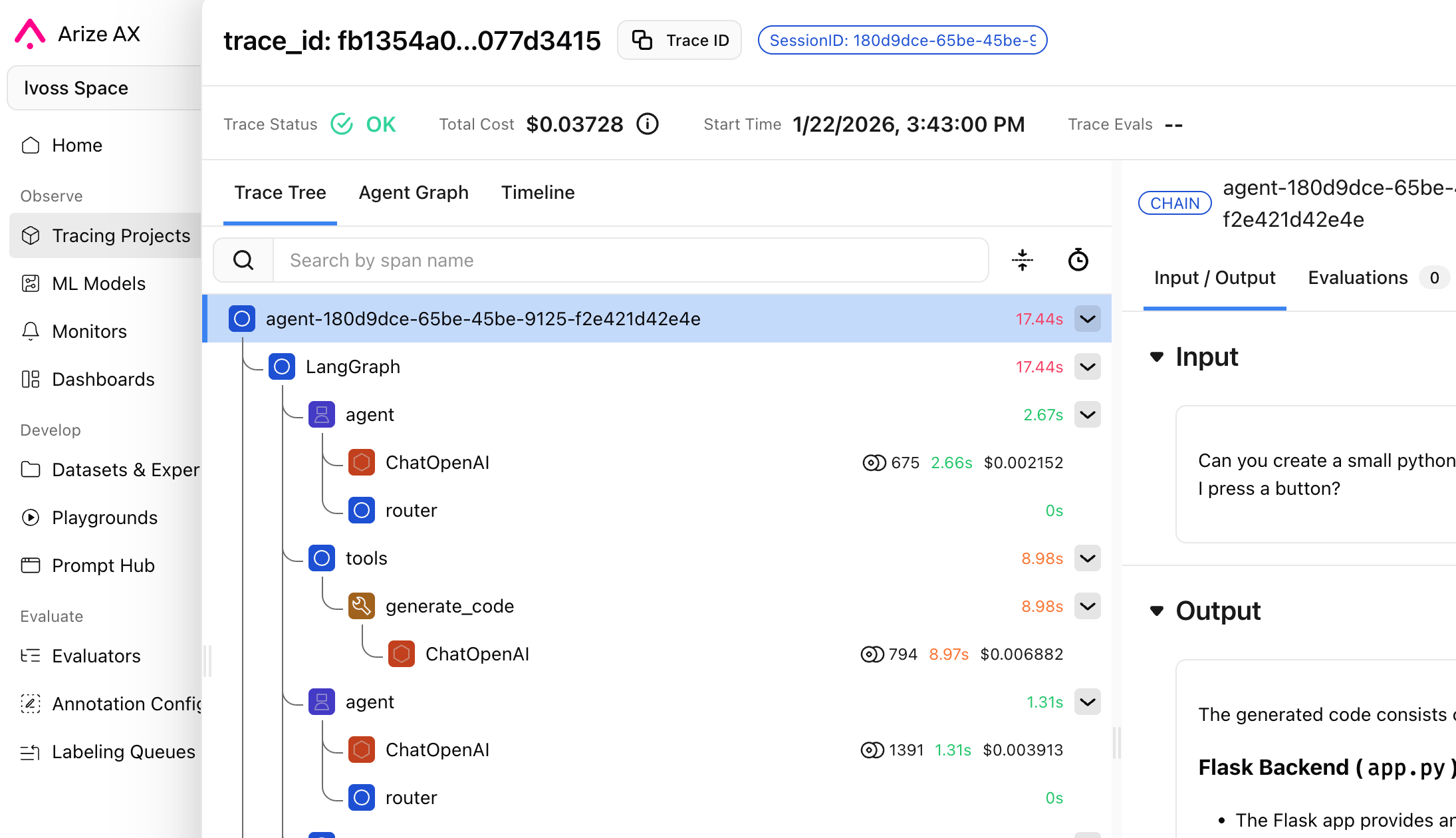
How does Alyx work?
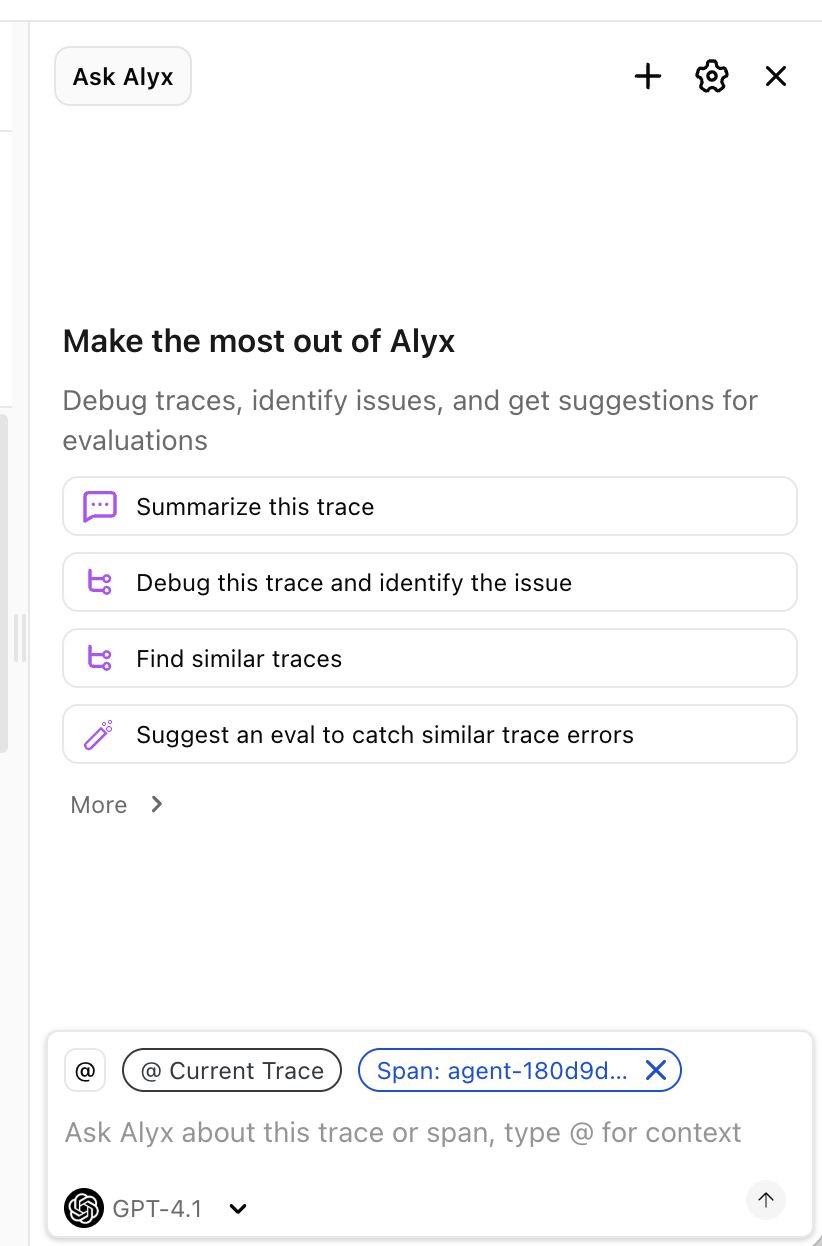
Why are we telling you this?
Lesson 1: Staying on task
Why does this happen?
The solution: planning

The planning tools
- todo_write
- todo_update
- todo_read
in_progress is important
The plan lives outside conversation history
What Alyx sees
# Current Plan
0. [x] Sort LLM spans by latency
1. [~] Identify bottlenecks ← CURRENT
2. [ ] Suggest improvements
Call todo_update(id=1, status="completed")
when you finish this task.The finish gate
You must complete or mark as blocked all todos before finishing
The blocked status
Gets a human in the loop
Enforce in code,
not just prompts
Lessons from planning
- Few-shot examples beat abstract instructions
- "Always use todo_write to plan" doesn't work
- Show the agent what good planning looks like
Lesson 2:
Context management
The context problem
DO NOT TRY TO COMPARE MORE THAN 2 EXPERIMENTS AT A TIME
The file system insight
LargeJson
Compress value,
not structure
jq and grep_json
jq '.experiments[0].rows[:5]'
jq '[.rows[] | select(.eval_score < 0.5)]'
jq '[.rows[].latency_ms] | add / length'
grep_json pattern="error"Small, composable tools
Infinite context
Lessons in context management
- Hard token budgets on every tool output
- Compress values, not structure
- Don't paper over problems with artificial limits
- RecoverableExceptions create feedback loops
- Tool responses may contain customer data — watch your logs
Lesson 3:
crystallizing good behavior
Vibe checking
Does not scale
Production traces
as ground truth
Level 1: decision-point tests
contains_any=[
["2000ms", "2.0 seconds", "two seconds"],
["OpenAIChat.invoke", "LLM span"],
]Level 2: trajectory tests
The evaluation prompt matters
CI and prompt validation
Evaluating Alyx with AX
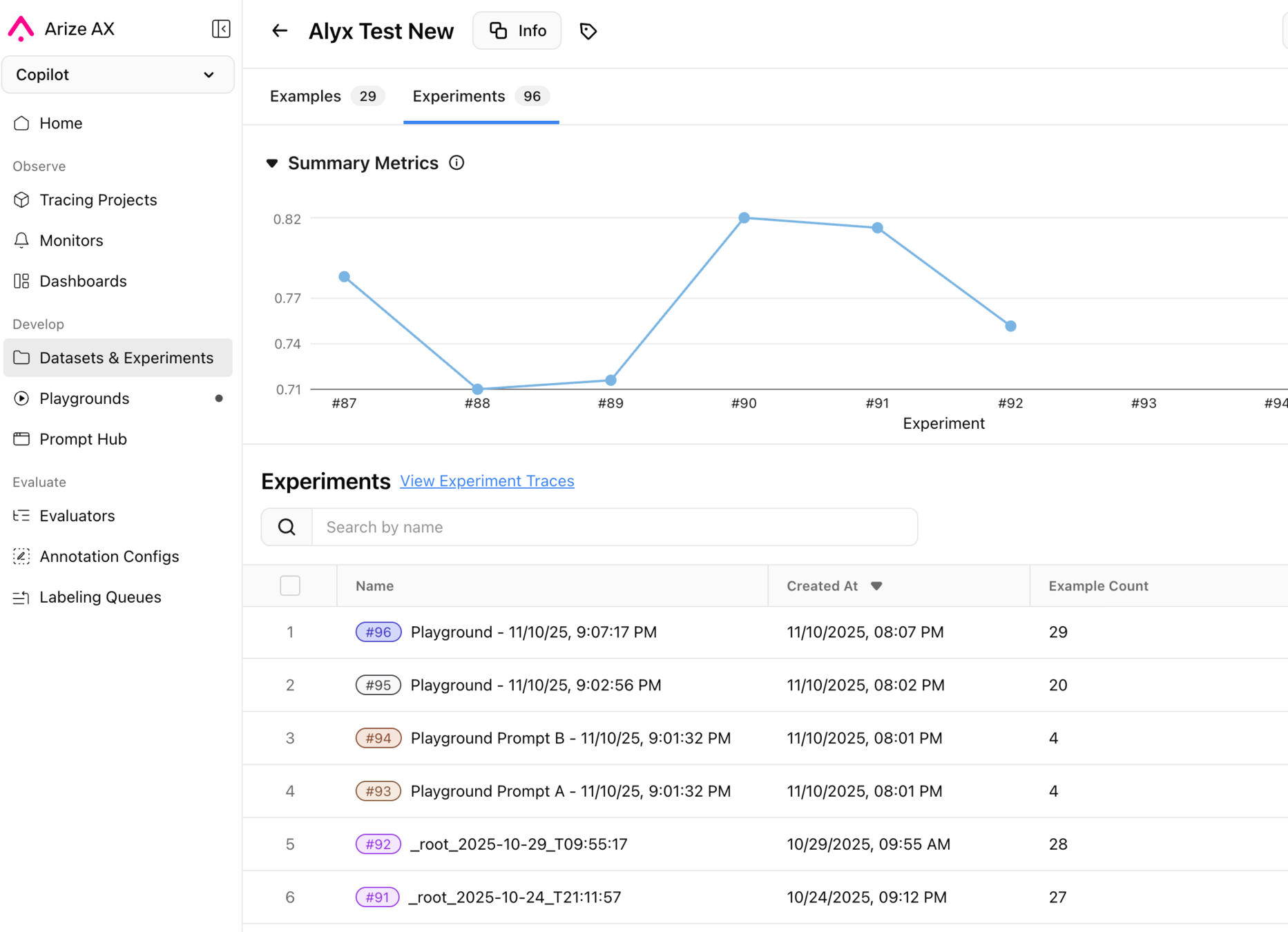
Lessons from
crystallizing behavior
- Capture good sessions; don't invent expected outputs
- Match facts, not phrasing
- LLM-as-judge for semantic evaluation
- Real APIs, not mocks — integration bugs are real
Lesson 4:
debugging a real agent
Three systems
- Arize: what the LLM saw and decided
- Datadog: what the server was doing
- GCP: what the infra was doing
Manual debugging is brutal
Give your coding agent skills
The debugging loop
Debugging in action
LLM reads alyx-traces skill
→ pulls full session trace
→ identifies failing tool call, notes trace_id
LLM reads datadog-debug skill
→ searches backend spans for that trace
→ finds 500 error on GraphQL resolver
LLM reads gcloud-logs skill
→ finds OOMKill 2 minutes earlier
→ "here's your root cause"
Safety lives in code
not in polite suggestions
- safe-kubectl.sh — rejects all mutating verbs
- safe-gcloud-logs.sh — read only
- Production commands are suggestion-only
Small, composable tools
(again)
Agent debugging
is an agent-shaped problem
Lessons from debugging
Text
- Skills are just markdown — low cost, high value
- Composability through shared conventions
- Safety must be in wrappers, not prompts
- Observability before you need it
Enforce good behavior in code, not prompts
The big lessons: #1
Provide just enough context
The big lessons: #2
Crystallize what goes well
The big lessons: #3
Get ready to debug
The big lessons: #4
Two big themes
- Context engineering
- Handling nondeterminism
Context (engineering) is (nearly) everything
LLMs be wacky
Thank you!
Follow me on BlueSky: 🦋 @seldo.com
These slides: slides.com/seldo/alyx-lessons-learned
Alyx: Lessons Learned
By Laurie Voss



