Making Astronomical Data AI-Ready
Across Surveys
Lessons-learned from the Multimodal Universe Project
François Lanusse
National Center for Scientific Research (CNRS)
Polymathic AI
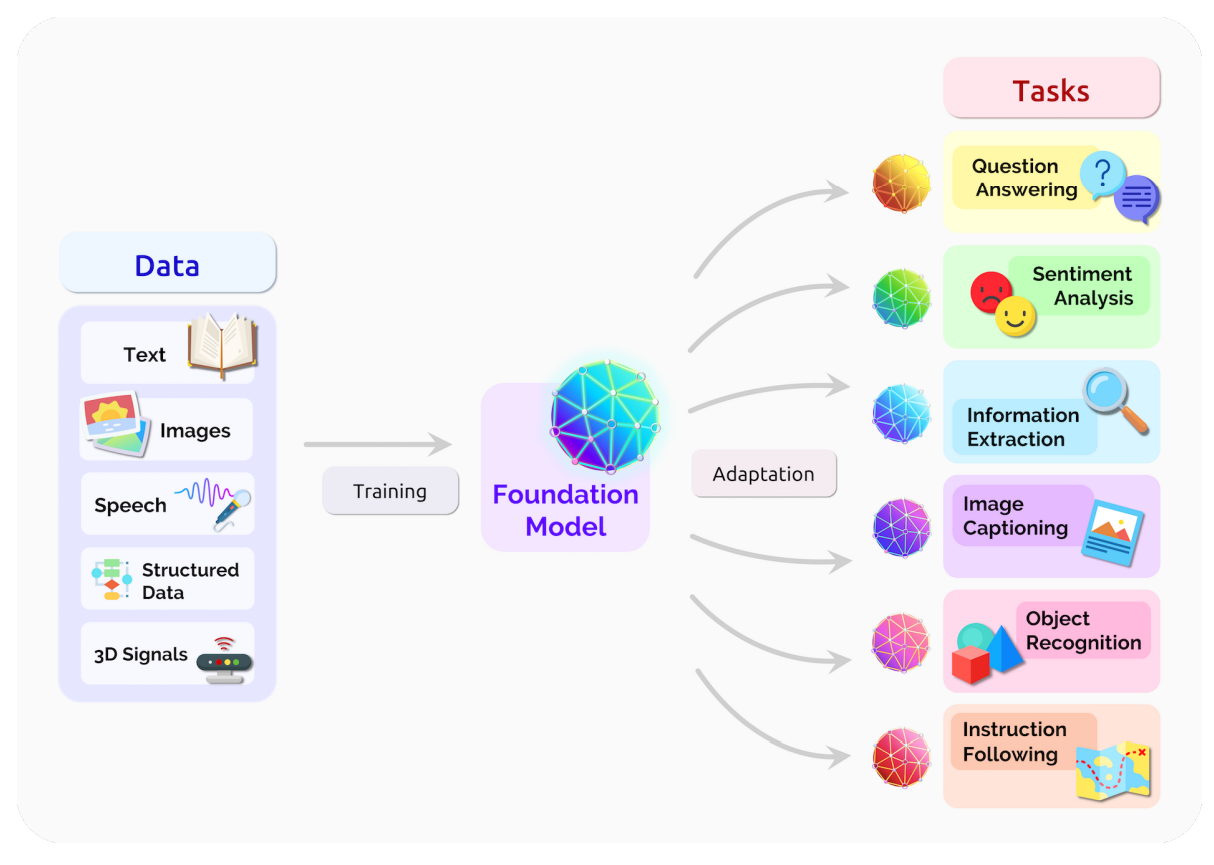
The Rise of The Foundation Model Paradigm
-
Foundation Model approach
-
Pretrain models on pretext tasks, without supervision, on very large scale datasets.
- Adapt pretrained models to downstream tasks.
-
Pretrain models on pretext tasks, without supervision, on very large scale datasets.
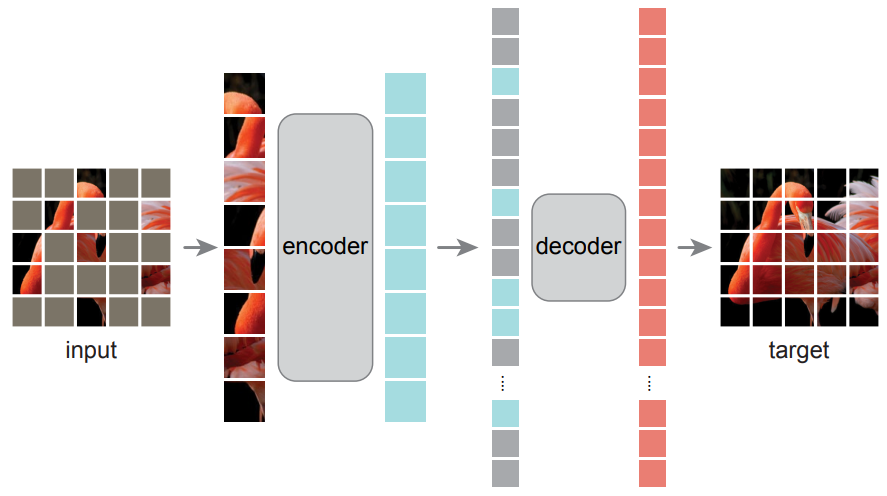
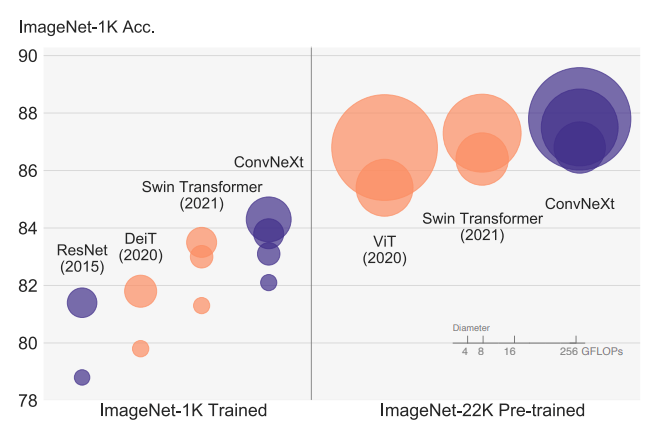
The Advantage of Scale of Data and Compute
What This New Paradigm Could Mean for Us
-
Never have to retrain my own neural networks from scratch
-
Existing pre-trained models would already be near optimal, no matter the task at hand
-
Existing pre-trained models would already be near optimal, no matter the task at hand
- Practical large scale Deep Learning even in very few example regime
-
Searching for very rare objects in large surveys like Euclid or LSST becomes possible
-
Searching for very rare objects in large surveys like Euclid or LSST becomes possible
- If the information is embedded in a space where it becomes linearly accessible, very simple analysis tools are enough for downstream analysis
- In the future, survey pipelines may add vector embedding of detected objects into catalogs, these would be enough for most tasks, without the need to go back to pixels
AstroCLIP
Cross-Modal Pre-Training for Astronomical Foundation Models

Project led by Liam Parker, Francois Lanusse, Leopoldo Sarra, Siavash Golkar, Miles Cranmer
Accepted contribution at the NeurIPS 2023 AI4Science Workshop
Published in the Monthly Notices of Royal Astronomical Society






The AstroCLIP approach
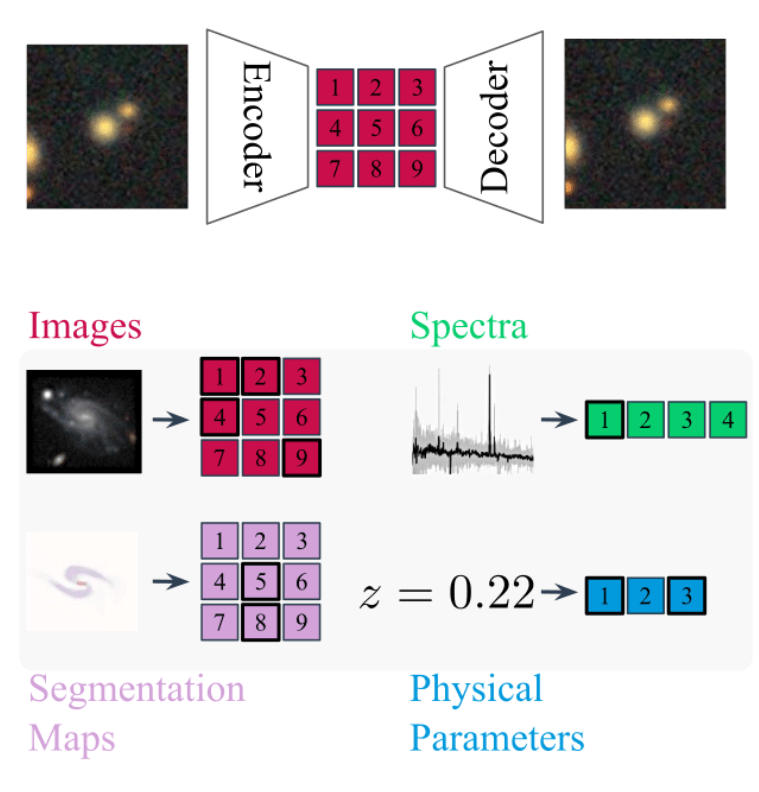
- We use spectra and multi-band images as our two different views for the same underlying object.
- DESI Legacy Surveys (g,r,z) images, and DESI EDR galaxy spectra.
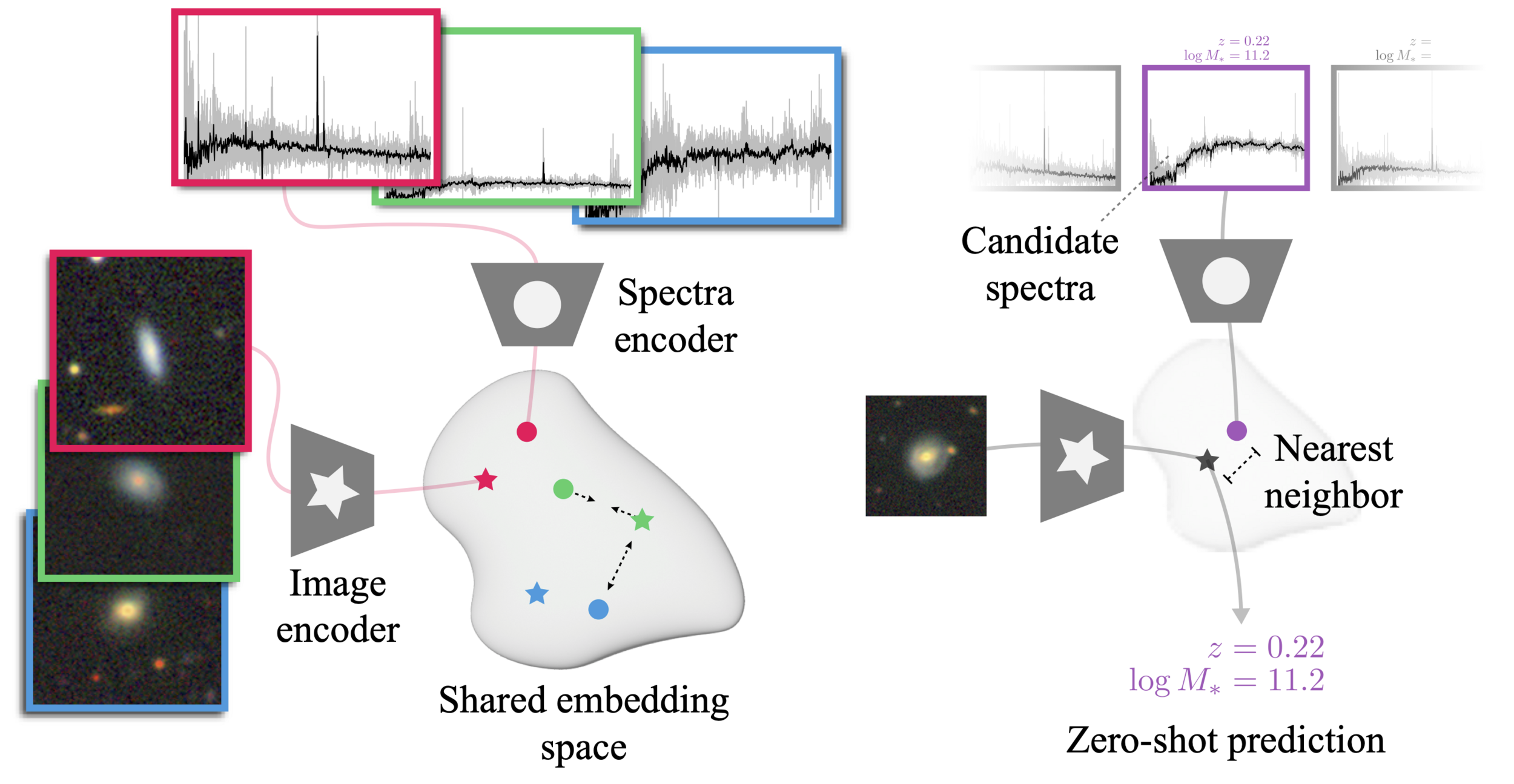
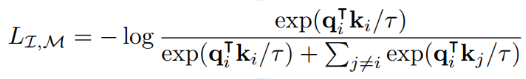

Cosine similarity search
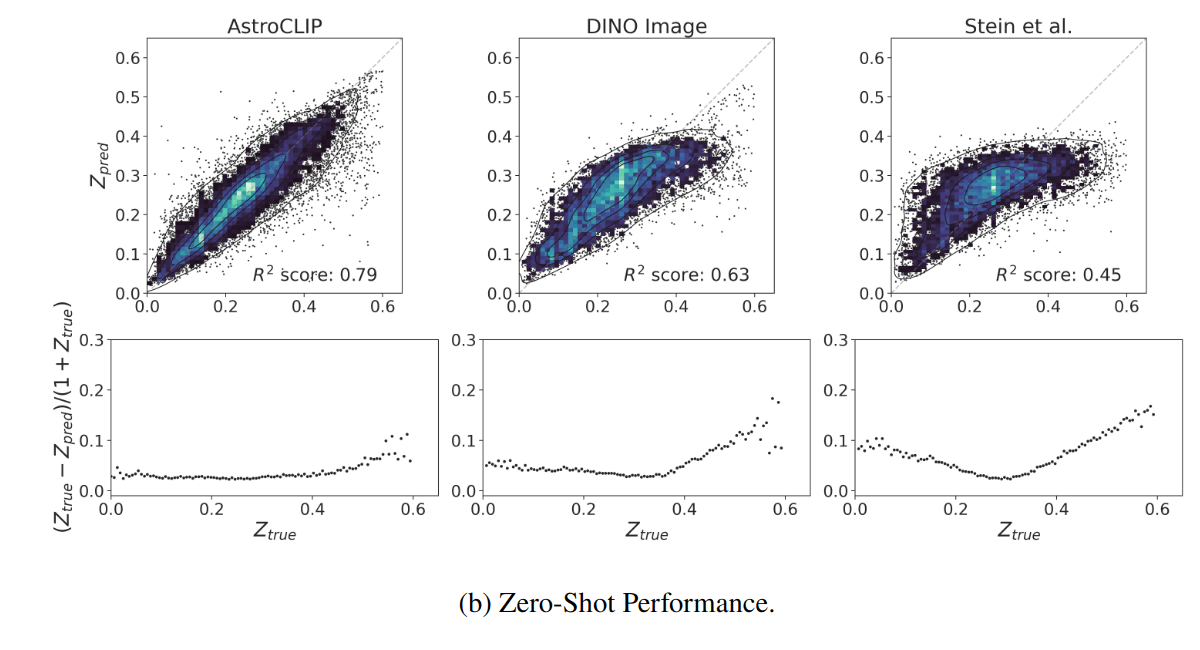
- Redshift Estimation From Images
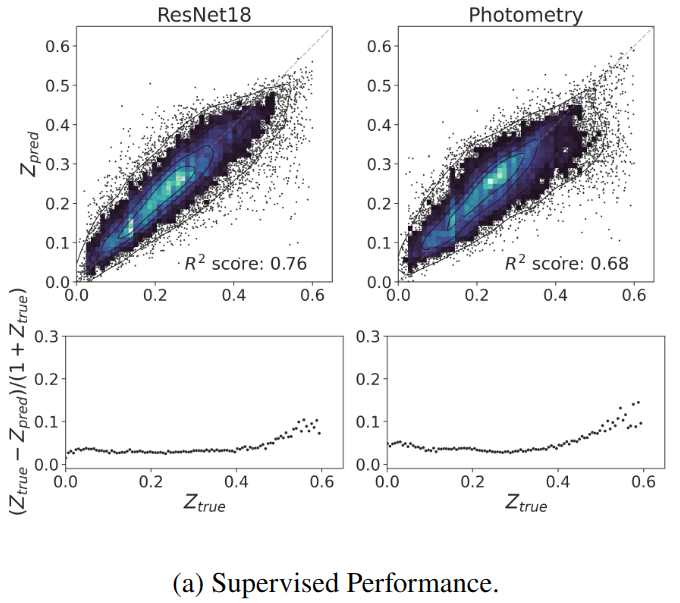
Supervised baseline
z_{true}
z_{true}
z_{true}
z_{true}
z_{true}
- Zero-shot prediction
- k-NN regression
Evaluation of the model: Parameter Inference
AION-1


Omnimodal Foundation Model for
Astronomical Surveys
Accepted at NeurIPS 2025, spotlight presentation at NeurIPS 2025 AI4Science Workshop







Project led by:
Francois
Lanusse
Liam
Parker
Jeff
Shen
Tom
Hehir
Ollie
Liu
Lucas
Meyer
Sebastian Wagner-Carena
Helen
Qu
Micah
Bowles
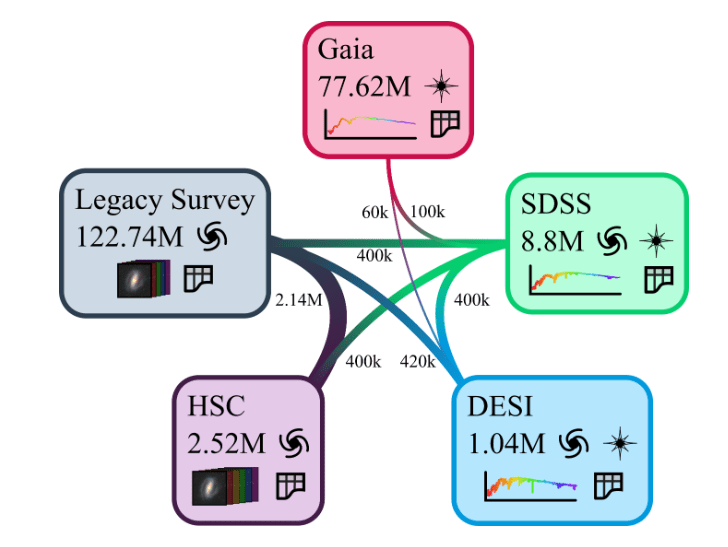
The AION-1 Data Pile

(Blanco Telescope and Dark Energy Camera.
Credit: Reidar Hahn/Fermi National Accelerator Laboratory)





(Subaru Telescope and Hyper Suprime Cam. Credit: NAOJ)



(Dark Energy Spectroscopic Instrument)


(Sloan Digital Sky Survey. Credit: SDSS)
(Gaia Satellite. Credit: ESA/ATG)
Cuts: extended, full color griz, z < 21
Cuts: extended, full color grizy, z < 21
Cuts: parallax / parallax_error > 10
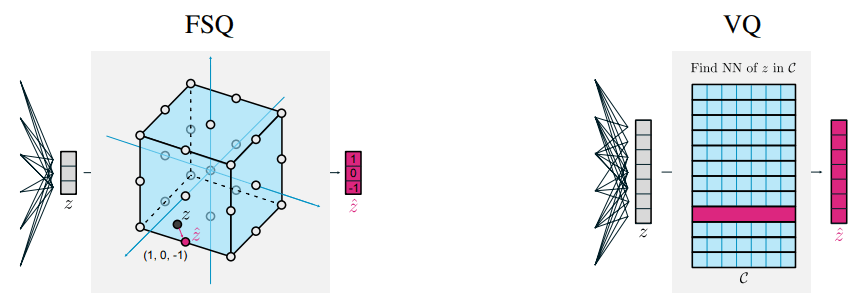
Standardizing all modalities through tokenization
- For each modality category (e.g. image, spectrum) we build dedicated tokenizers
=> Convert from any data to discrete tokens
- For Aion-1, we integrate 39 different modalities (different instruments, different measurements, etc.)
\mathcal{L} = \parallel \Sigma^{- \frac{1}{2}} \left( x - d_\theta( \lfloor e_\theta(x) \rfloor_{\text{FSQ}} \right) \parallel_2^2
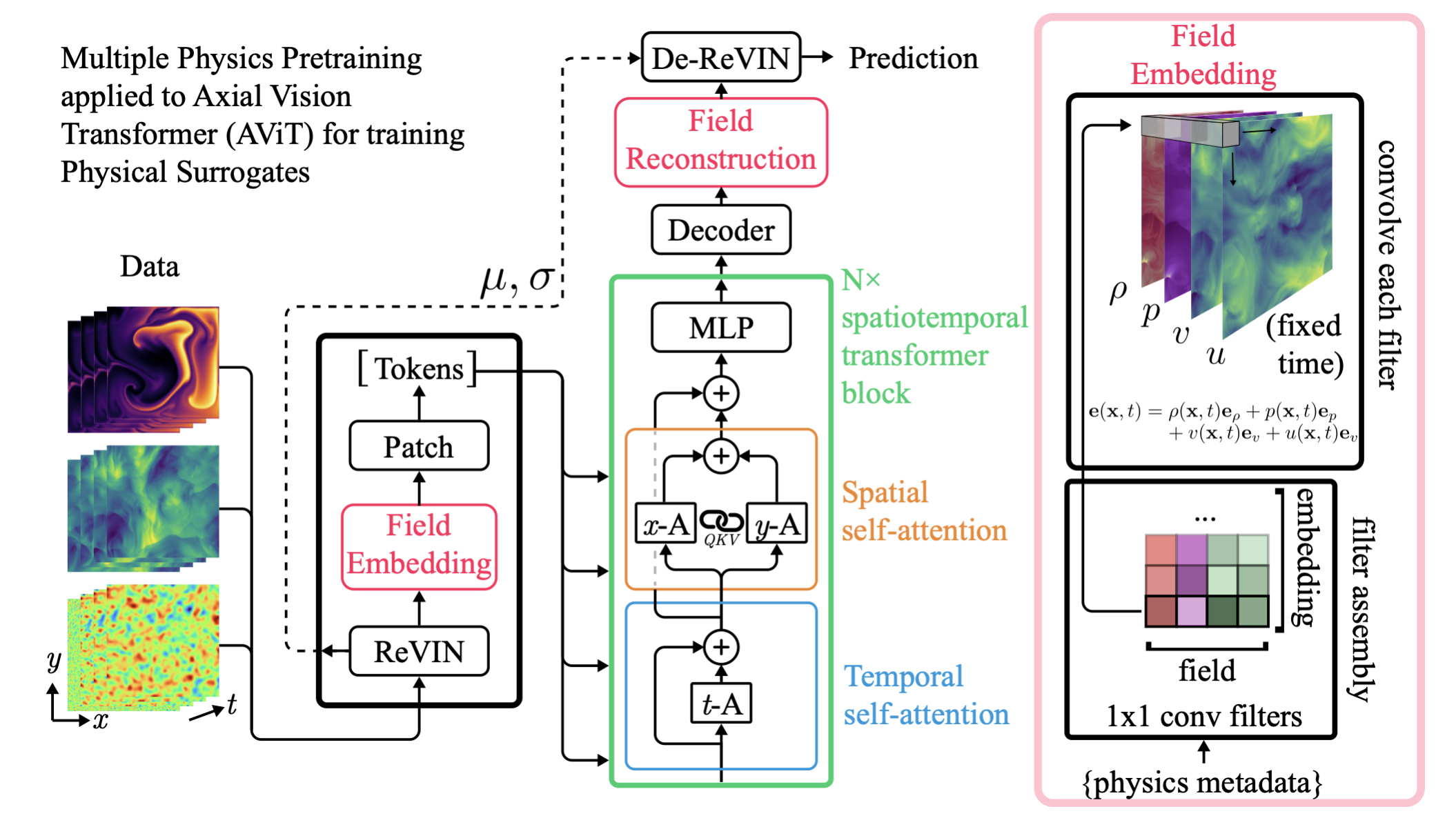
Field Embedding Strategy Developed for
Multiple Physics Pretraining (McCabe et al. 2023)

DES g
DES r
DES i
DES z
HSC g
HSC r
HSC i
HSC z
HSC y

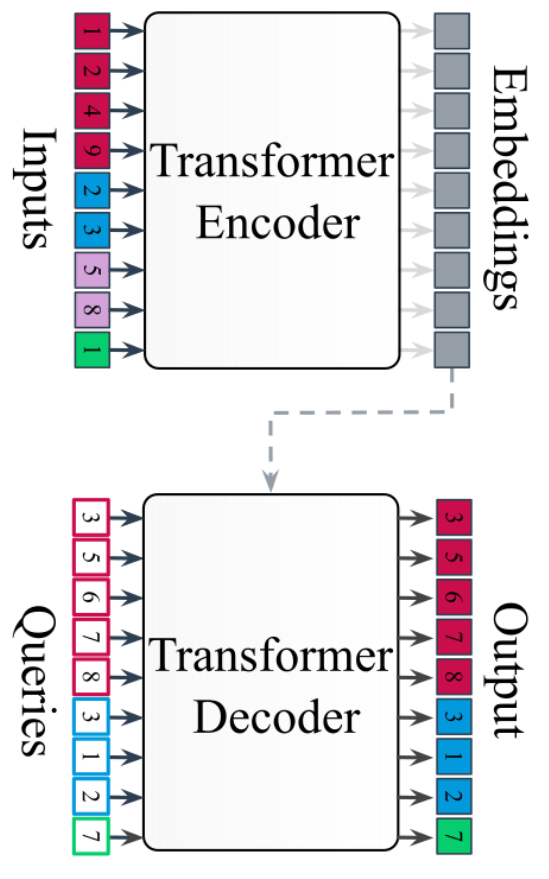
Any-to-Any Modeling with Generative Masked Modeling
- Given standardized and cross-matched dataset, we can feed the data to a large Transformer Encoder Decoder
- Flexible to any combination of input data, can be prompted to generate any output.
- Model is trained by cross-modal generative masked modeling
=> Learns the joint and all conditional distributions of provided modalities:
\forall m,n \quad p_\theta(x_m | x_n)
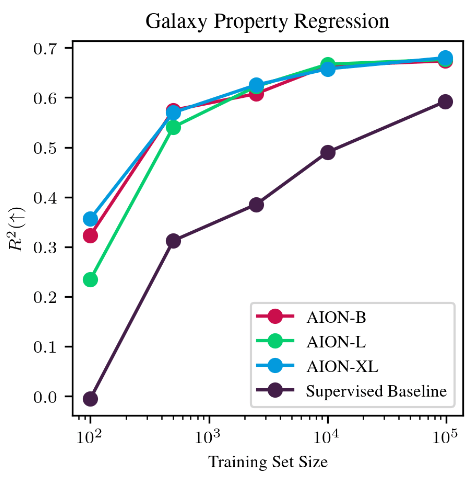
Morphology classification by Linear Probing
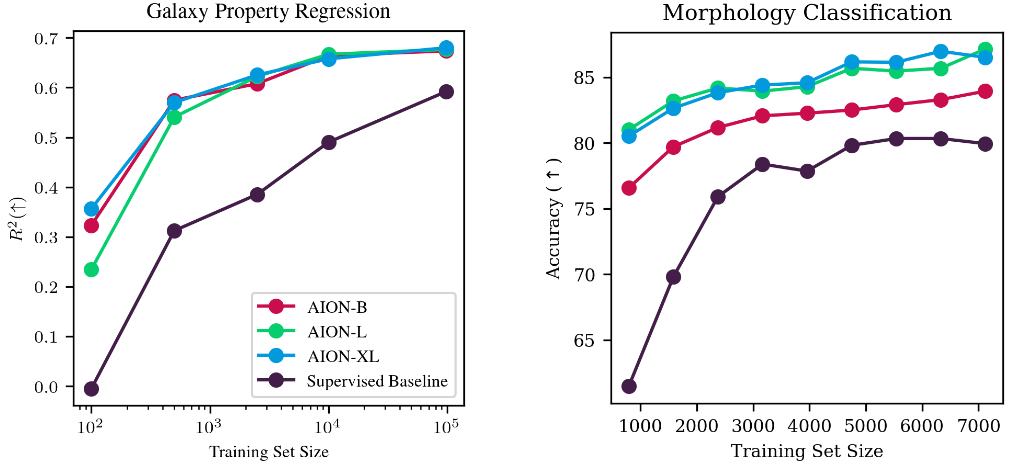


Trained on ->
Eval on ->
Physical parameter estimation and data fusion
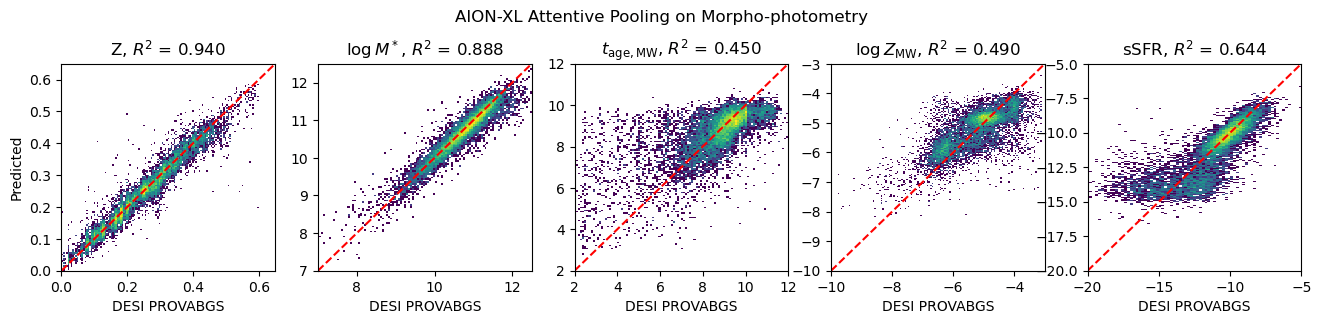
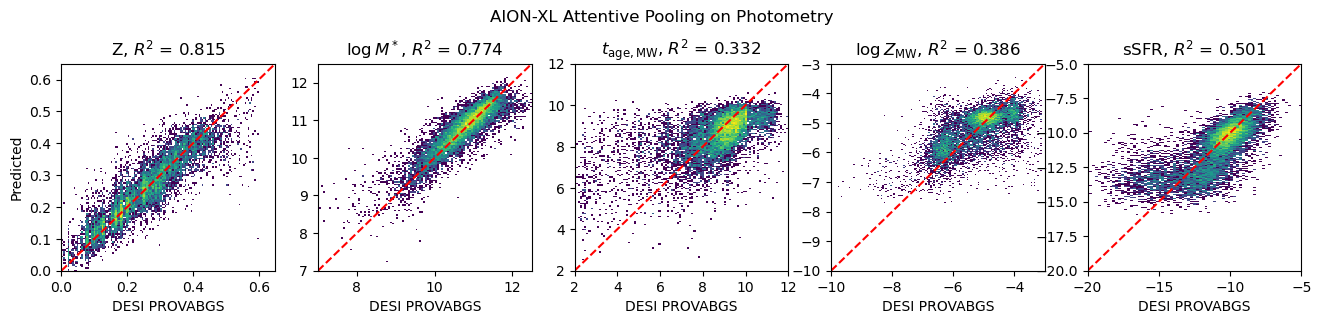
Inputs:
measured fluxes
Inputs:
measured fluxes + image
Example-based retrieval from mean pooling

AION-Search: Semantic Retrieval

Spotlight at 2025 NeurIPS AI4Science Workshop

Nolan Koblischke
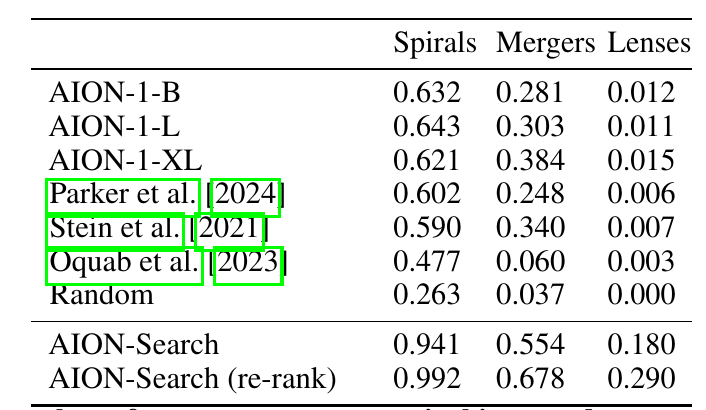
Where do we get the data to train these models?
The Scientific Data Curation Challenge
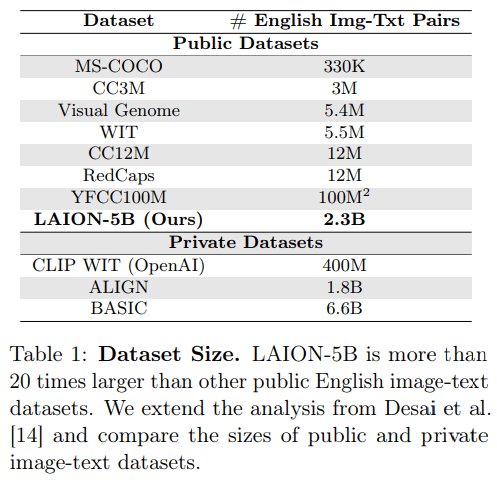
- Success of foundation models is driven by large corpora of uniform data (e.g LAION 5B).
- Scientific data comes with many additional challenges:
- Metadata matters
- Wide variety of measurements/observations

Credit: Melchior et al. 2021


Credit:DESI collaboration/DESI Legacy Imaging Surveys/LBNL/DOE & KPNO/CTIO/NOIRLab/NSF/AURA/unWISE
The Multimodal Universe
Enabling Large-Scale Machine Learning with 100TBs of Astronomical Scientific Data
Collaborative project with about 30 contributors
Presented at NeurIPS 2024 Datasets & Benchmark track


The MultiModal Universe Project
- Goal: Assemble the first large-scale multi-modal dataset for machine learning in astrophysics.
-
Main pillars:
- Engage with a broad community of AI+Astro experts.
- Adopt standardized conventions for storing and accessing data and metadata through mainstream tools (e.g. Hugging Face Datasets).
- Target large astronomical surveys, varied types of instruments, many different astrophysics sub-fields.
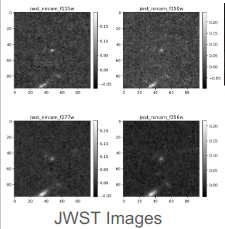



Multiband images from Legacy Survey

MMU Infrastructure

Content of v1
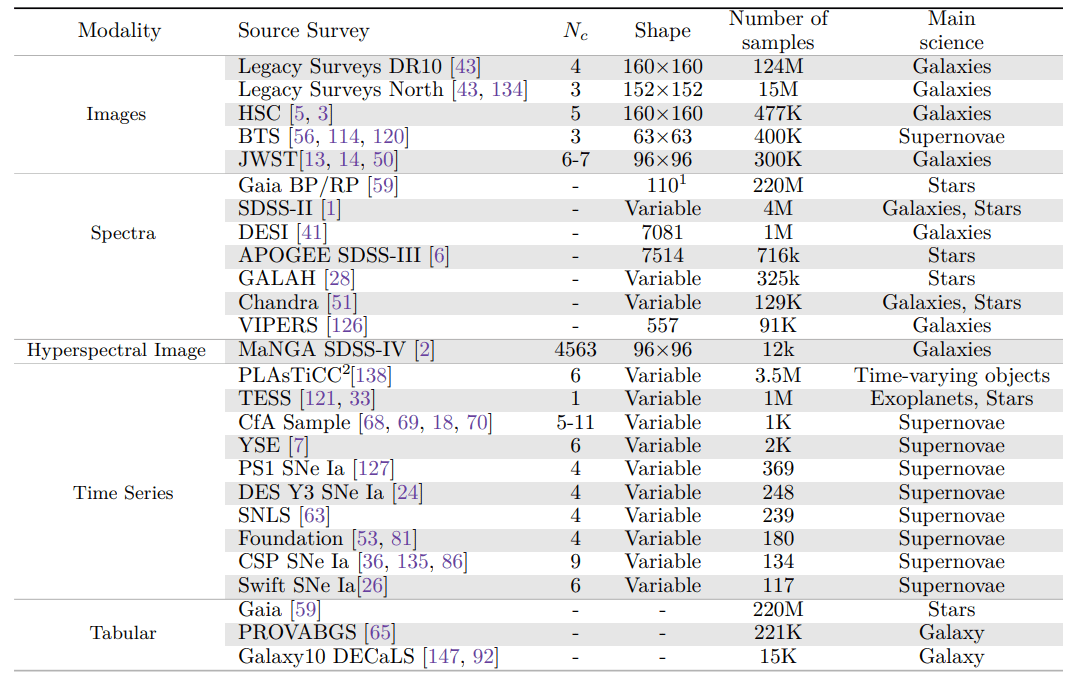
Data schema and storage
- For each example MMU expects a few mandatory fields:
- object_id, ra, dec
- object_id, ra, dec
- For each modality, MMU expects the data to be formatted according to a fixed schema which only contains strictly necessary metadata.
- Data is stored in HDF5 files, split according to HEALPix regions for efficient cross-matching and easy access

hsc
├── hsc.py
├── pdr3_dud_22.5
│ ├── healpix=1104
│ │ └── 001-of-001.hdf5
│ ├── healpix=1105
│ │ └── 001-of-001.hdf5
│ ├── healpix=1106
│ │ └── 001-of-001.hdf5
│ ├── healpix=1107
│ │ └── 001-of-001.hdf5
│ ├── healpix=1171
│ │ └── 001-of-001.hdf5
│ ├── healpix=1172
│ │ └── 001-of-001.hdf5
│ ├── healpix=1174
│ │ └── 001-of-001.hdf5
│ ├── healpix=1175
│ │ └── 001-of-001.hdf5
│ ├── healpix=1702
│ │ └── 001-of-001.hdf5
...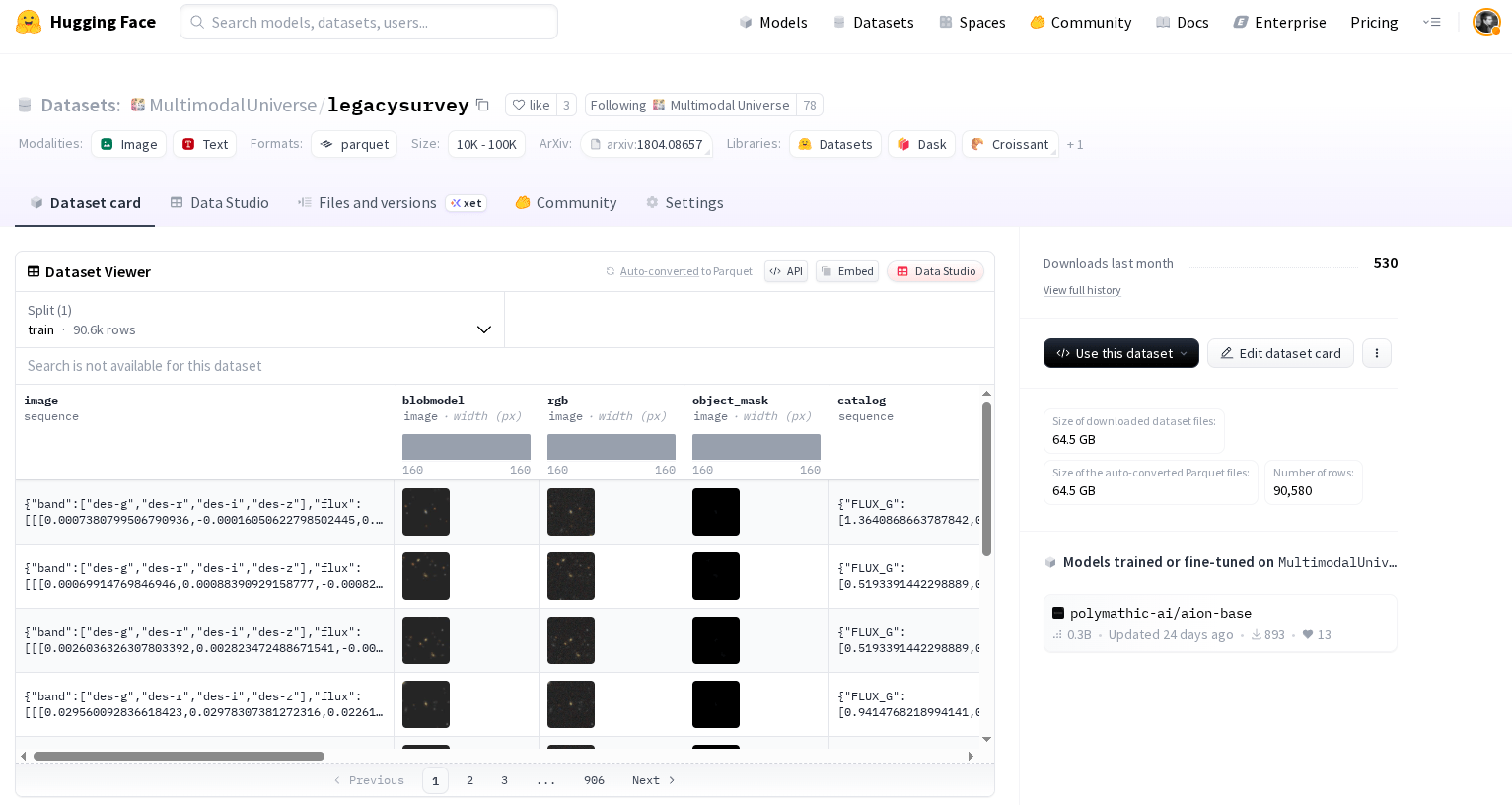
Usage example
from datasets import load_dataset
# Open Hugging Face dataset
dset_ls = load_dataset("MultimodalUniverse/legacysurvey",
streaming=True,
split='train')
dset_ls = dset_ls.with_format("numpy")
dset_iterator = iter(dset_ls)
# Draw one example from the dataset iterator
example = next(dset_iterator)
# Let's inspect what is contained in an example
print(example.keys())
figure(figsize=(12,5))
for i,b in enumerate(example['image']['band']):
subplot(1,4,i+1)
title(f'{b}')
imshow(example['image']['flux'][i], cmap='gray_r')
axis('off')

dict_keys(['image', 'blobmodel', 'rgb', 'object_mask', 'catalog', 'EBV', 'FLUX_G', 'FLUX_R', 'FLUX_I', 'FLUX_Z', 'FLUX_W1', 'FLUX_W2', 'FLUX_W3', 'FLUX_W4', 'SHAPE_R', 'SHAPE_E1', 'SHAPE_E2', 'object_id'])

Some considerations for AI pre-training
- Design should facilitate streaming tensors to GPUs in conventional frameworks (e.g. Hugging Face Datasets or similar)
- Homogeneity is good but does not have to be imposed across data sources
- i.e. images can have different pixel scale, normalizations, etc... as long as provenance is somehow captured alongside the data.
-
Neural networks will automatically learn to interpret the relative difference between datasets
-
Multimodal training requires cross-matching across surveys
- Implies a strategy to obtain O(1000) postage stamps per seconds between 2 surveys
-
With MMU and training AION-1 this cross-matching is done offline: slow, not very flexible
- Versionning and production of static curated datasets is challenging
- Requires a local copy of all datasets (postage stamps APIs of most surveys are not fast enough to support generating millions of stamps), non trivial storage, and non trivial compute.
- MMU contains 120TB of data, versionning that data and incremental additions is not trivial to manage.
Thank you for listening!
Follow us online
MultimodalUniverse
By eiffl
MultimodalUniverse
MultimodalUniverse



