
















Content ITV PRO
This is Itvedant Content department
Learning Outcome
5
Explore its key features
4
Understand XGBoost
3
Know its limitations
2
Learn error (residual) correction
1
Understand Gradient Boosting basics
But problem:
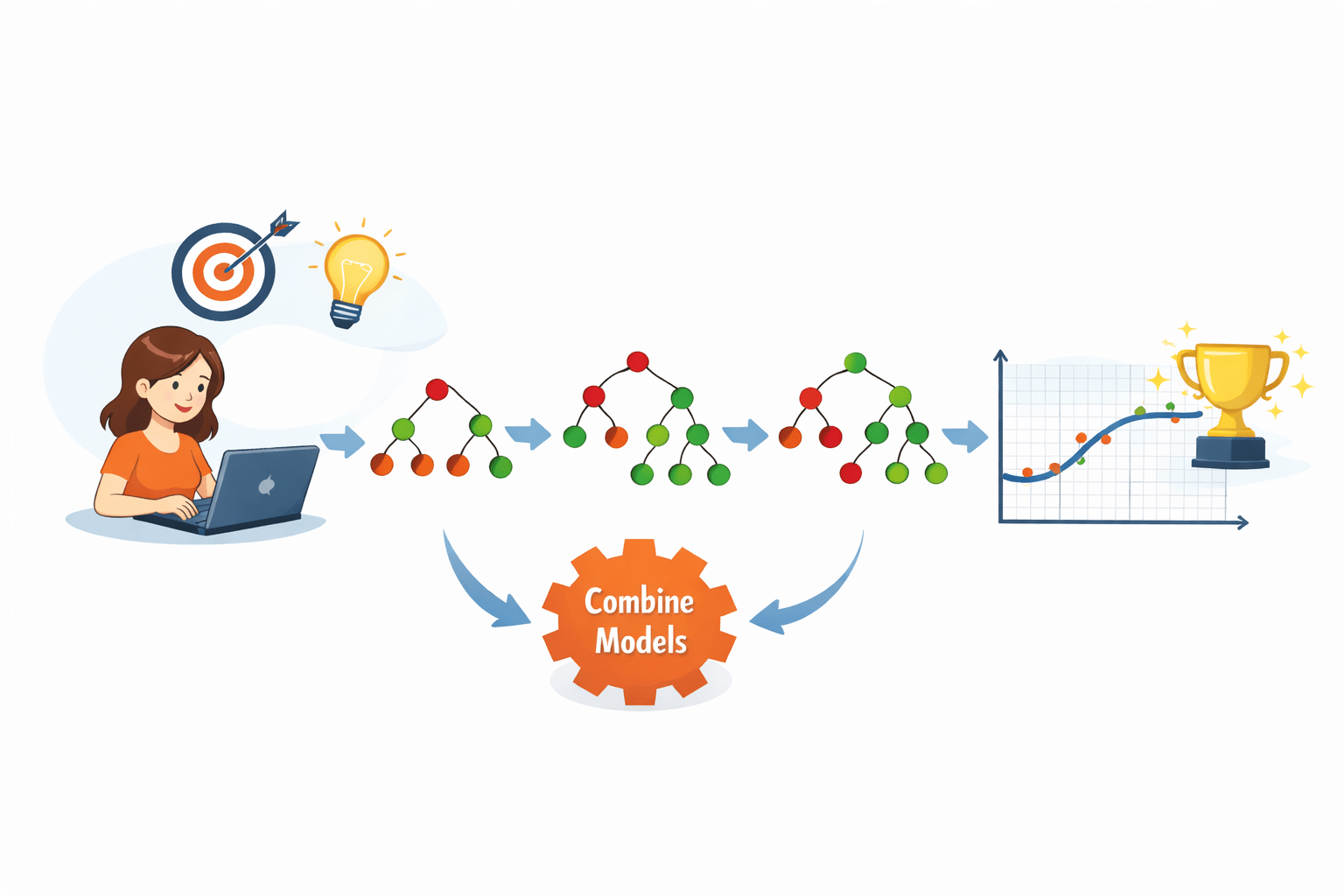
Gradient Boosting (Next Level)
Instead of just increasing weight, Model 1 sends exact error (residual)
Model 2 learns how much mistake happened and how to correct it
Imagine A king wanted a perfect human face statue, so he hired a team of artists.
Artist 1 (Base Model)
The first artist used a big tool and made a rough face.
It looked similar, but had big mistakes.
Artist 2
The second artist didn’t start from scratch.
He only looked at the extra stone (errors) left behind.
He carefully removed those mistakes.
Artist 3
The third artist focused only on the tiny scratches left.
He polished them to make the statue smoother.
What the Machine Does
Just like the artists:
Each new model = fixes previous mistakes → perfect result step by step
The Math of the Sculptor
Step 1 :
Tree 1 predicts house price: $200k
Actual Price: $250k
The Residual (Error): $250k - $200k = +$50k
Step 2 :
Tree 2 does NOT predict $250k.
It explicitly targets the Residual (+$50k)
This is the key to Gradient Boosting!
The Combination:
Final_Prediction = Model_1(Base) + Model_2(Error)
To get our final prediction, we simply add the outputs together
The Problem: Standard Gradient Boosting is Fragile
Overfitting (Too Much Learning)
Problem 1:
Slow Speed
Problem 2:
The Evolution: Enter XGBoost
What is it?
Extreme Gradient Boosting
Takes the math of Gradient Boosting and injects hardware optimization, mathematical safety nets, and extreme speed.
The King of ML :
Behind almost every winning Kaggle competition for tabular data
Why "Extreme"? :
It enhances Gradient Boosting with speed, optimization, and better accuracy.
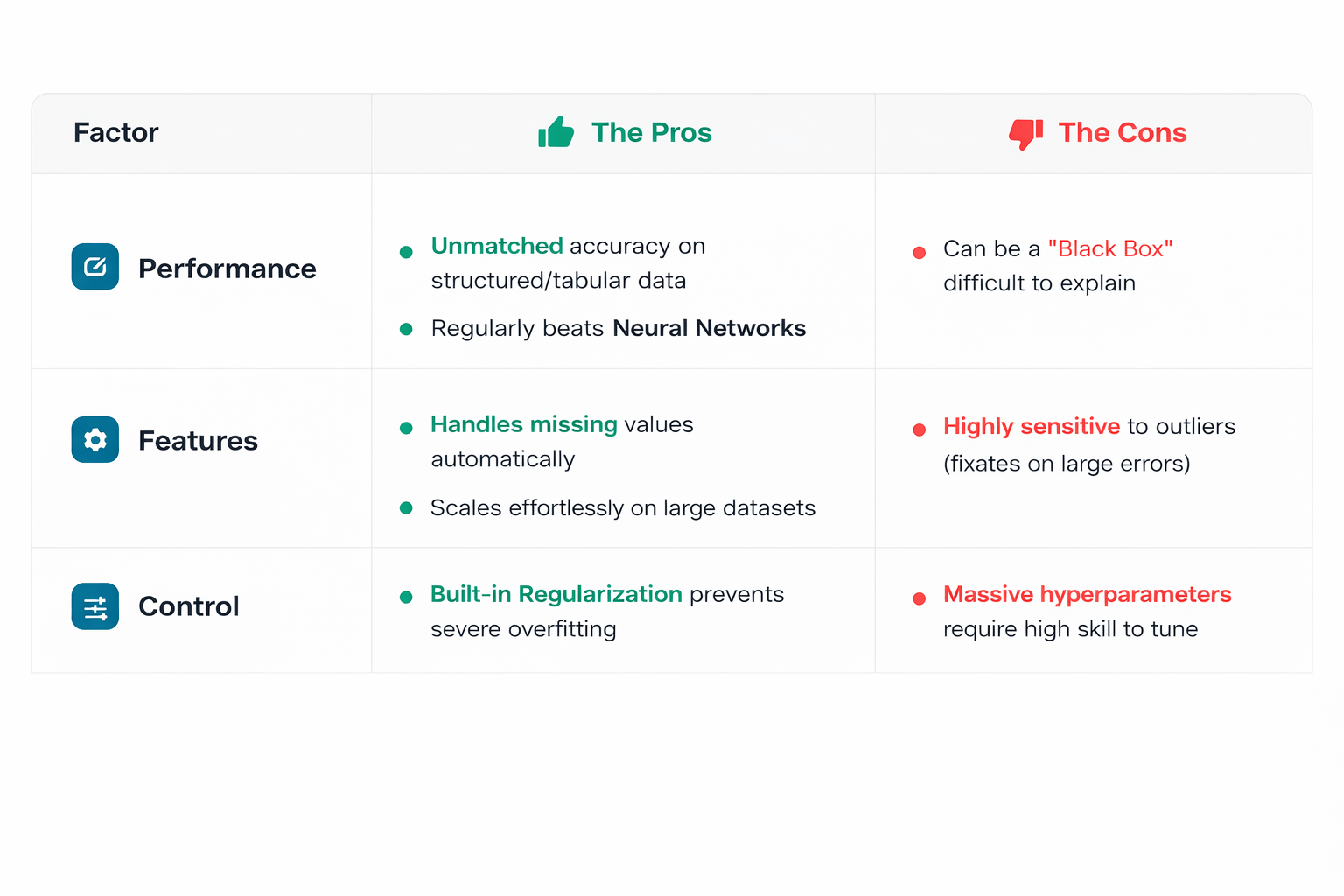
Why XGBoost is Best
Built-in Regularization
L1 & L2 Penalties
XGBoost controls model complexity and prevents overfitting by penalizing complex trees.
Acts as a strict manager
Sparsity Awareness
Handles Missing Data
XGBoost handles missing data automatically by learning the best path
No imputation required!
Does magic under the hood
XGBoost speeds up training by using parallel processing on multi-core systems.
Hardware Parallelization
Extreme Speed
Pros & Cons Cheat Sheet
Summary
5
XGBoost handles missing data, regularization, and fast computation
4
XGBoost improves performance and efficiency
3
It can suffer from overfitting and slow speed
2
Each model predicts the error (residual) of the previous one
1
Gradient Boosting builds models sequentially
Quiz
What does the second tree predict in Gradient Boosting?
A. Same target
B. Average values
C. Residual (error)
D. Missing values
Quiz-Answer
What does the second tree predict in Gradient Boosting?
A. Same target
B. Average values
C. Residual (error)
D. Missing values
By Content ITV



