
An Introduction to Learning Through Simulation
Who's this guy
Chief Executive Officer
I'VE DONE MORE
Chief Technology Officer at Yoyo
Payment facilitator for small businesses
Video Game Development Engineer at Playful, Ensemble, Newtoy (Zynga with Friends)
AOE, Lucky's tale, Creativerse, Oculus SDK (v0 through v1)
Minor OSS contributor
DevIL, ResIL, fog, Emscripten (Web Assembly)
We've come a long way
What Are World Models?
An internal simulator that learns to predict what happens next
| Concept | Learns From | Output |
|---|---|---|
| Reinforcement Learning | Experience | Policy/Value |
| Generative AI | Data | Image, video, text |
| World Model | Env. signals | Internal simulation |
Captures state, transitions, and visual output
Reinforcement Learning
-
Q‑Learning (Watkins & Dayan, 1992) — “Q-Learning”, Machine Learning, 8(3–4):279-292. This paper proves convergence of the Q-learning algorithm under appropriate conditions.
-
Playing Atari with Deep Reinforcement Learning (Mnih et al., 2013) — Introduces the DQN algorithm (a deep neural-network variant of Q-learning) that can learn control policies directly from raw pixels.
-
Deep Reinforcement Learning with Double Q‑Learning (van Hasselt et al., 2016) — A deep RL variant addressing over-estimation in Q-learning via Double Q-learning.

VPT: Learning from Watching
Generative

Why not just teach machines by doing?
Dreaming is a safer, faster path to learning
why simulate?
❌ Real-World Learning
-
Slow (robot training)
-
Risky (self-driving)
-
Expensive (physical trials)
✅ Dreaming (Simulation)
-
Fast iterations
-
Completely safe
-
Cost-effective
Why Do We Need World Models?
Timeline & Milestones
| Year | Milestone |
|---|---|
| 1990s | Early world model concepts (Schmidhuber) |
| 2018 | Ha & Schmidhuber: 'World Models' paper |
| 2024 | DeepMind Genie v1: 2D dream worlds |
| 2025 | Genie v3: Real-time 3D environments |
Understanding the Basics
Observation
Encoder
Latent State
Decoder

Under the Hood: Architecture
Key Components

Showcase: NES Agents
Gathering the Data
NES emulator in Python
Because... why not? 😁
-
Origin & Adoption — Introduced in 1975, affordable & efficient
-
Significance in NES — Pivotal for game development in the platform
- Lasting Legacy — remains a symbol of the pioneering era of gaming
The Heart of Retro Gaming: The 6502 Chip

6502 Instruction Set
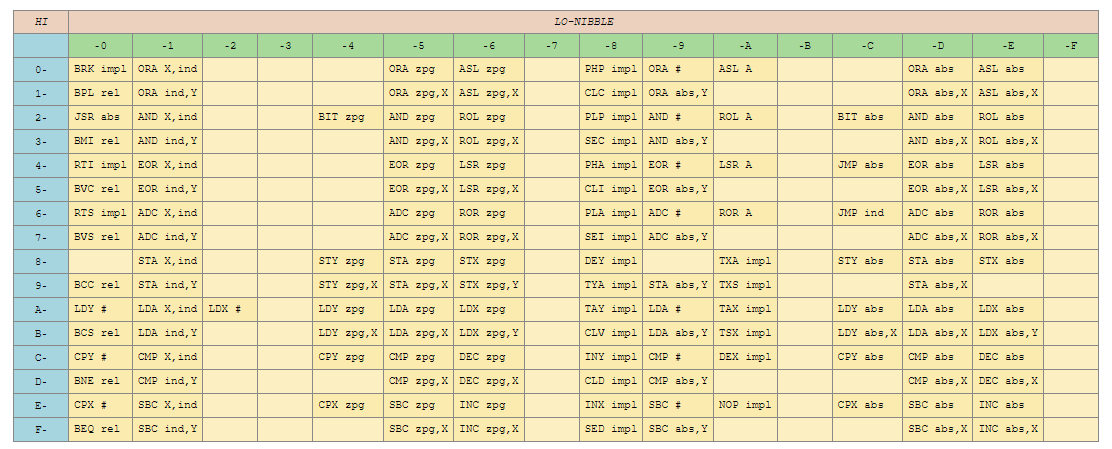
-
NES 6502 instruction set: The heart of classic gaming.
-
The PPU: a chip so mysterious even Nintendo had to guess what it was doing half the time.
- If you're writing a NES emulator and it works the first time... you didn't emulate it.
NES Emulation Basics
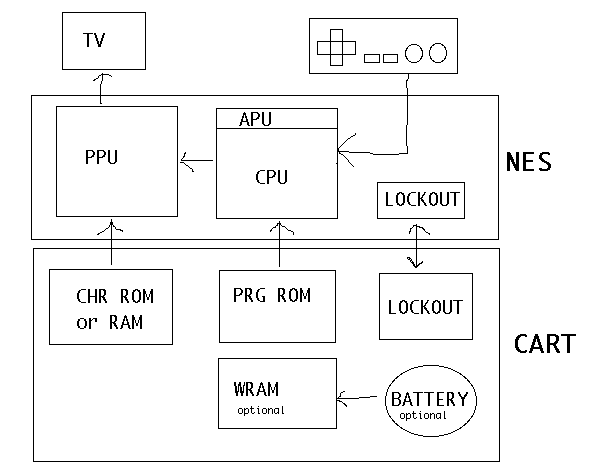
The NES Architecture

A more familiar picture
Hard awakening...
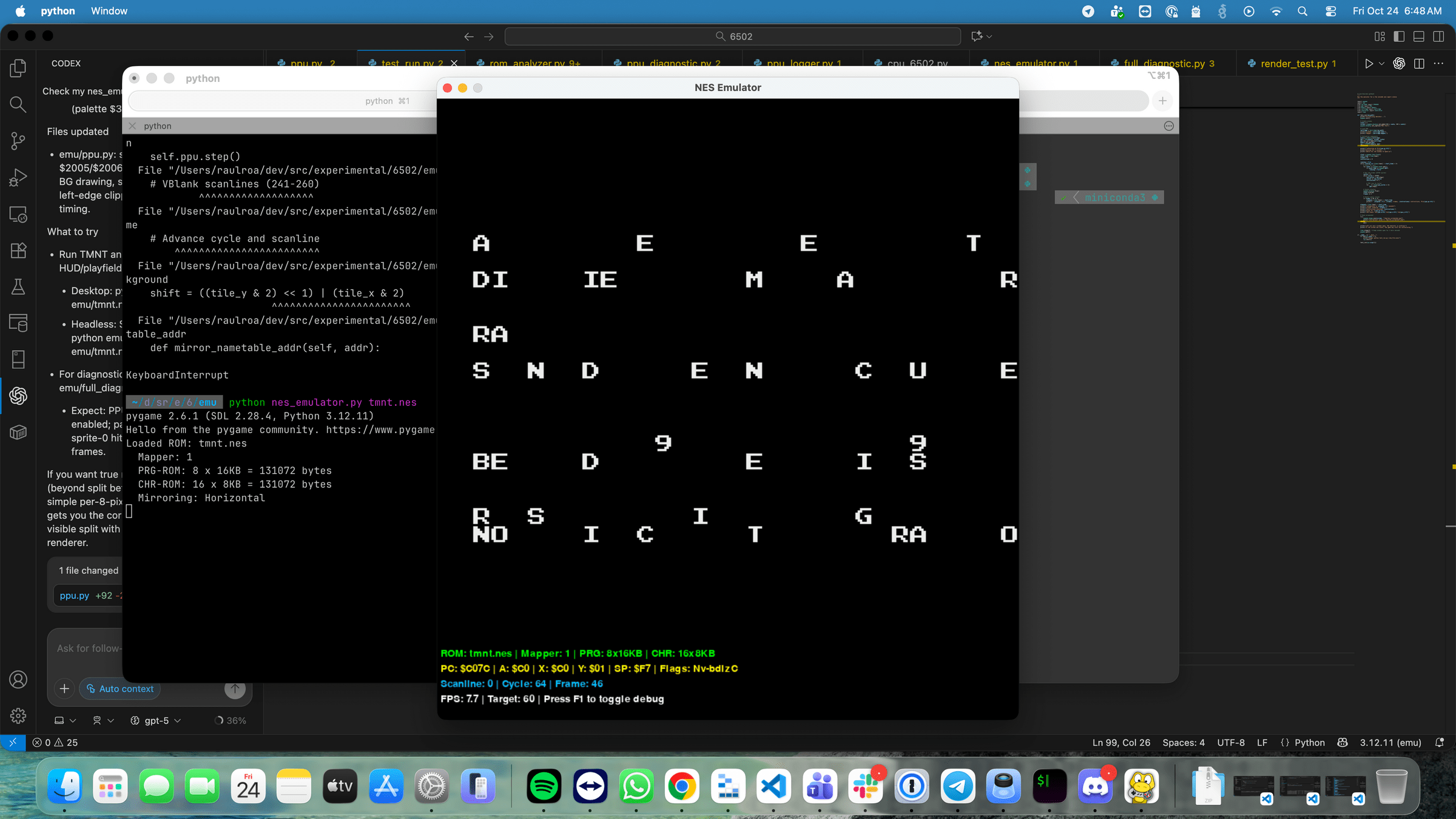
But we found our way...

Training Progress:
Dreams get better
Like RL agents, world models improve over time

Demo

Strengths & Limitations

The Road Ahead

Conclusions
Questions?

Links of Interest
- RL - https://www.youtube.com/watch?v=MXpNf0fqI6E
- VPT - https://www.youtube.com/watch?v=9axsVfOEdGQ
- RNN - https://www.youtube.com/watch?v=9HaKyGNhMvY
- https://slides.com/raulg-roagomez
