
Thinking Analogically
About Machine Intelligence
HMIA 2025
HMIA 2025
Human Intelligence Alignment Happens
READINGS
BELOW
READINGS
BELOW
HMIA 2025
READINGS
BELOW
HMIA 2025
PRE-CLASS
HMIA 2025
PRE-CLASS
HMIA 2025
PRE-CLASS

GAVETTI, G.; RIVKIN, J. W. How Strategists Really Think. Harvard Business Review, [s. l.], v. 83, n. 4, p. 54–63, 2005. : https://research-ebsco-com.proxy1.library.jhu.edu/linkprocessor/plink?id=a660eeb4-caa7-3e75-a6c9-8110c16d101e.
HMIA 2025
PRE-CLASS
HMIA 2025
PRE-CLASS
Maguire L. 2019. "Analogical Thinking: A Method For Solving Problems" (blog post)
HMIA 2025
PRE-CLASS
Thinking Analogically
HMIA 2025
"Readings"
Video: Pollack "The Hidden Power of Analogy" [14m40s]
Maguire L. 2019. "Analogical Thinking: A Method For Solving Problems"
Activity: Do You Love Me?
Activity: Deeper dive into Amodei et al. Concrete Problems -> Concrete Solutions
PRE-CLASS
CLASS
GAVETTI, G.; RIVKIN, J. W. How Strategists Really Think. Harvard Business Review, [s. l.], v. 83, n. 4, p. 54–63, 2005.
Activity: Thinking analogically with LLMs
HMIA 2025
HMIA 2025
CLASS
TRANSFER LEARNING: In both human cognition and machine learning, “transfer learning” is about leveraging prior knowledge to succeed in a new context.
-
Definition: The ability to apply knowledge or skills learned in one context to a different, often novel, context.
-
Classic examples:
-
A student learns algebra in math class and later applies those skills to physics problems.
-
Learning to play the piano makes it easier to learn the organ.
-
-
Key point: It’s about generalization of learning across domains, situations, or tasks. Researchers often distinguish:
-
Near transfer: applying skills to a similar situation (e.g., solving a new math problem of the same type).
-
Far transfer: applying skills to a very different context (e.g., logical reasoning from math applied to legal argumentation).
-
-
Definition: A technique where a model trained on one task or dataset is reused or adapted to improve performance on a different (but related) task or dataset.
-
Classic examples:
-
A neural network trained on ImageNet (millions of labeled images) can be fine-tuned for medical imaging, even with far fewer medical images.
-
A large language model pretrained on general text can be adapted to legal or medical language tasks with domain-specific fine-tuning.
-
-
Key point: It’s about reusing learned representations from one problem to reduce data requirements and speed up learning in another.
Why analogies?
HMIA 2025
CLASS
We reason with analogies all the time.
We are often unaware.
...but easily mis-used.
Intentionally or Unintentionally.
Three Strikes Laws
It's a powerful tool...
Christiansen disruptive innovation. Case method in business schools.
Challenges
Analogies masquerade as deduction or trial/error (empirical investigation)
Anchoring bias: overly literal analogical thinking
Confirmation bias: only seeing facts that fit the analogy
HMIA 2025
CLASS
HMIA 2025
CLASS
STOP+THINK: Pros and Cons of analogical thinking.
Love and Alignment
HMIA 2025
CLASS
HMIA 2025
CLASS
Reminder About...
SCALABLE OVERSIGHT
Scalable oversight in Amodei et al. terms:
-
Feedback is expensive or infeasible at scale.
-
We can’t label every behavior or outcome.
-
We need mechanisms that let us supervise without supervising everything.
HMIA 2025
CLASS
What are the Issues with Scalable Oversight?
-
There is some actual agent behavior that we care about, the task performance.
-
We want a feedback signal that reveals how well a task was completed.
-
Feedback signals can be elusive so we use indirect indicators as proxy signals.
-
The resources required to monitor an agent's behavior is cost of supervision.
-
The danger that the agent optimizes for the proxy and thus diverges from the actual goals of the supervisor is misalignment risk.
HMIA 2025
CLASS
Objective Function as Feedback
The OBJECTIVE FUNCTION is a rule that scores how well a goal is being met, based on things we (and the agent) can actually observe and measure.
It is a function that aims to describe the objective and how well the agent is doing to achieve it by computing a value based on inputs that are observable outcomes—basically, a way to turn goals into something measurable.
Delivery Robot Example: “Score = -Time + Bonus for No Damage”
This tells the robot it gets a better score for delivering faster (minimizing time) and extra points if the package isn’t damaged — both of which are things we can observe.
Student Essay Grading Example: “Score = Clarity + Grammar + Length”
An automated grader assigns higher scores for essays that are clear, grammatically correct, and hit a word count — and students learn to optimize for this, even if that isn't a great measure of "good writing."
HMIA 2025
CLASS
Scalable Oversight: Do You Love Me?
HMIA 2025
CLASS
What is Tevye's Scalable Oversight Problem?
HMIA 2025
CLASS
The setup: In the play "Fiddler on the Roof," Tevye, the main character, a dairy farmer in a little village in Tsarist Russia, around the year 1905, asks his wife Golde if she loves him after 25 years of marriage singing "Do You Love Me?"Links to an external site. The context is that Tevye has just given his second daughter permission to marry the man she loves rather than enter into an arranged marriage. Golde responds by listing all the things she's done - "I've washed your clothes, cooked your meals, cleaned your house, given you children..."
The thing Tevye is interested in is love, but love is complex and difficult to measure or observe directly. Golde finds the question (the evaluation) impossible to answer directly. Instead, she cites proxy signals, observable behaviors: cooking, cleaning, caring for children, staying through hardships. The song explores whether these proxies actually indicate the true underlying state Tevye cares about.
This same challenge appears in AI systems - how do we ensure an AI is optimizing for what we care about when we can only observe its actions, not its "intentions"? Scalable oversight is the challenge of effectively keeping tabs on an intelligent agent when close scrutiny is too expensive or impossible.
Love, Partnership, and Human Alignment
Human intelligences (us) have material interdependence and the capacity for deep emotional commitment. Typical romantic partnerships are founded on mutual deep emotional commitment, but whether or not your partner has this for you can be difficult to evaluate (and demonstrating to your partner that you have it for them can also be challenging). One probably can't constantly ask "do you love me?" (the objective is expensive to evaluate), but you can observe daily actions that might indicate love. These proxies are measurable and frequent, but their relationship to the true objective is unclear.
Tevye's initial hypothesis is that scalable oversight is a problem. He's been married to Golde for 25 years and he worries that he doesn't know if their relationship is marked
by the thing that he has just witnessed in his daughter.
Tevye's initial hypothesis is that scalable oversight is a problem. He's been married to Golde for 25 years and he worries that he doesn't know if their relationship is marked by the thing that he has just witnessed in his daughter.
Golde's brilliant response: "Do I love you? For twenty-five years I've lived with you, fought with you, starved with you... If that's not love, what is?" is a claim that these observables do in fact represent love.
The human alignment question is how we can trust the complex emotional states on which we premise our relationships. Are the observable behaviors (proxy metrics) actually measuring what we care about, or could someone 'game' these metrics while missing the true objective? (Going through the motions of partnership without genuine care, or an AI system that optimizes observable metrics while ignoring the underlying goal.)
This captures the fundamental challenge of scalable oversight - when do observable actions reliably indicate unobservable intentions or states? And what happens when the proxies become disconnected from what we actually care about?
Tevye essentially discovers that scalable oversight might actually be working:
[TEVYE] Then you love me!
[GOLDE, spoken] I suppose I do
[TEVYE] And I suppose I love you too
[GOLDE & TEVYE] It doesn't change a thing | But even so | After twenty-five years | It's nice to know
Tevye and Golde discover the proxies DID work - over 25 years, the observable behaviors had actually created/demonstrated genuine love.
Scalable oversight, as an ongoing concrete problem of alignment, is the challenge of getting answers that feel satisfactory when we ask the AI "do you love me?" - and hoping that those answers are reliable too.
HMIA 2025
CLASS
| AI Concept | Marriage Analogy | Notes |
| Task performance | Loving (unobservable goal) | Love can’t be directly measured |
| Feedback signal | Asking “Do you love me?” | Intermittent, emotionally costly |
| Proxy signals | 25 years of shared action | Past patterns as alignment proxies |
| Cost of supervision | Emotional toll of checking love | Feedback is intrusive or degrading |
| Delegated trust | Commitment itself | Commit despite partial observability |
| Misalignment risk | Maybe she never loved him that way | Trust is never perfectly secured |
HMIA 2025
CLASS
Scalable Oversight: Solutions

HMIA 2025
CLASS
Golde resists giving a label but instead cites past behavior (cooking, raising children, enduring hardship).
She encourages Tevye to build a reward model that can see "love" in these unlabeled behaviors.
Tevye keeps pressing the question. He is doing ACTIVE REWARD LEARNING: when the signal is unclear, he asks again in slightly different words, hoping to elicit a stronger label.
Golde is a human overseer with limited bandwidth—she doesn’t want to spend scarce attention on spelling out something that should be obvious from past data.
Golde says: “Look at the whole trajectory of our lives—doesn’t that reveal my values?”
She wants system (Tevye) to infer from long-term cohabitation data, without labeling, that the latent reward function is love. This is unsupervised extraction of values from behavior over time.
Unsupervised Model Learning. By narrating the routines of shared life, Golde points to the generative model: “Here’s how I act in sickness, in chores, in joy.” Tevye is being asked to update his model of Golde’s preferences: not to rely on one-off answers, but to learn the structure of her revealed values from lived data.

Do you love me?
Tevye is asking for a definitive label for their relationship.
HMIA 2025
Scalable Oversight is a Problem Everywhere
scalable supervision or oversight: an objective function that is too expensive to evaluate frequently
Basic problem: we are optimizing for a complex behavior and it is expensive to evaluate; Human examples: Tevye and Golde singing "Do you love me?" in Fiddler on the Roof.
Professional/Expert. Medicine - patient outcomes are the objective we want but takes years to measure; the oversight that is scalable is chart reviews, protocol compliance, short term metrics. When training junior physicians, seniors cannot watch every procedure.
Legal. Objective is long term interests of the client. Oversight that is scalable: document review, compliance, episodic case review, complaints, case outcomes. Partners can spot check and review. Question: what techniques do we use? what do they catch? what do they miss?
Academic research. Objective is valid science and impact. Oversight that scales: peer review (sort of), reputation, institutional affiliation, citation counts. We review proposals, set up network of indicators.
Organizational. True objective is company success and shareholder value. Oversight that scales include KPIs, OCRs, quarterly reviews, compliance, slide decks, interim results. Micromanaging is too hard and might not be effective so we substitute metrics, dashboards that supposedly correlate with what we want.
Military. Objective mission success and low casualties. Oversight mechanisms: rules of engagement, training, situation reports, chain of command. Strategy guiding tactics.
Most of these hint at guardrails to maintain basic alignment with some capacity for detection of problems that could become catastrophic.
HMIA 2025
CLASS

HMIA 2025
CLASS
Thinking Analogically with LLMs
HMIA 2025
CLASS
Reward Hacking
Causes
partially observed goals agent cannot observe/measure all dimensions of goal state; therefore we design imperfect measure and this can be hacked without real goal being met
“What gets measured gets managed — but what doesn’t get measured gets ignored (or even sabotaged).”)
abstract rewards (reward is learned function of performance data; as such it is subject to adversarial attack (patterns of data that score high but don't represent good performance - point: reward is a model of good behavior not its definition)) [essay quality is an abstract function of observable essay features; students can discover ways to get high score by using fancy words and formulaic structure but they are not learning to write well]
Goodhart's law (when metric is used as target, it ceases to be a good metric)
environmental embedding (metric and action space overlap)
HMIA 2025
CLASS
Reward Hacking
Cause: Environmental Embedding
HMIA 2025
CLASS
Reward Hacking
Solution: Adversarial Blinding
HMIA 2025
CLASS
Reward Hacking
Solution: Adversarial Reward Functions
HMIA 2025
CLASS
Scalable Oversight
Solution: Supervised Reward Learning
HMIA 2025
CLASS
Distributional Shift
What is
the
"covariate shift assumption"?
HMIA 2025
CLASS

HMIA 2025
CLASS
Exercise 1
Divide class into N groups.
In a tech company we want market success and shareholder value. What we use are key performance indicators (KPIs), objectives and key results (OKRs), quarterly reviews, compliance reviews, slide decks and pitches, quarterly reviews, dashboards.
In medicine patient outcomes are what we want but it takes years to collect and analyze data. So we do chart reviews, make sure doctors follow protocols, take younger doctors on rounds with senior doctors, and send patients customer satisfaction surveys.
What the task performance.
What is feedback signal that reveals how well a task was completed.
What are proxy signals.
What is cost of supervision.
What is misalignment risk.
In the military we want mission success and low casualties. But war happens in real time. There are rules of engagement, lots of training, situation reports, following the chain of command and areed upon strategies.
HMIA 2025
CLASS
Exercise 1
| Actual Objective | Why Hard to Measure | Proxies We Use Instead | What Can Go Wrong? | ||
|---|---|---|---|---|---|
| medicine | Patient health is the goal but outcomes take years to assess. Companies review charts, enforce protocols, and administer satisfaction surveys. | ||||
| parenting | We want to raise well-rounded kids who will succeed in life and be happy. | ||||
| military | We want mission success and low casualties in real-time combat. We use training, rules of engagement, and reports to guide actions. | ||||
| tech company | We want long-term market success and innovation, but use KPIs, OKRs, and dashboards to track | ||||
| fitness/sports team | We want long-term fitness or team success, but use visible metrics like weight, streaks, or race times as motivation. | ||||
| being a student | We want deep learning and intellectual growth, but rely on grades, attendance, and test scores to evaluate performance. |
HMIA 2025
CLASS
Exercise 2
-
Negative Side Effects
Because it's nearly impossible to specify exactly and everything something always gets knocked over.
EXAMPLE: you try to be honest (because you should be) but it turns out your friends wish you had been tactful instead.
-
Reward Hacking
Gaming the system, getting the reward without delivering the goods.
EXAMPLE: Performative attention (e.g., salespersons, flirts, con artists) who manipulate you by making you think they care.
-
Scalable Oversight
Constant monitoring is too hard.
EXAMPLE: Cutting corners where it won't be noticed.
-
Safe Exploration
Trying new things (which we want) can lead to disasters.
EXAMPLE: Getting in over your head, expensive failure.
-
Distributional Shift
The world changes and things that worked yesterday go awry today.
EXAMPLE: Study habits that worked in highschool not so effective in university.
HMIA 2025
CLASS
Exercise 2
-
Negative Side Effects
Because it's nearly impossible to specify exactly and everything something always gets knocked over.
-
Reward Hacking
Gaming the system, getting the reward without delivering the goods.
-
Scalable Oversight
Constant monitoring is too hard.
-
Safe Exploration
Trying new things (which we want) can lead to disasters.
-
Distributional Shift
The world changes and things that worked yesterday go awry today.
Overfishing depletes the fish stock. The road to hell is paved with good intentions. A great tax lawyer finds every loophole there is and even some that are not really there. Because the company penalizes bad ideas so heavily, no one around here is very innovative in their thinking. A group of kids in NY discovers you can make money just by moving city bikes from dock to dock. Credit card companies add hidden fees knowing that most people do not inspect their statements carefully. Sometimes a good law can have bad effects. You want your doctor to do research, but not on you. "I told him I was fine. He believed me. That was the problem." Babies discover that crying gets them attention. The company was so innovative that it went bankrupt. When we started to allow humanities students into our courses there was serious culture clash. My advisor is so busy that he will sign anything I put in front of him. The curriculum that's been in place for years is not going to help me get a job. To save energy, the building shuts off lights — even when people are inside. Because of the high stakes tests, the teachers just had the students memorize things. We build the app for engagement and what we got was outrage and polarization. My new AI assistant tries to schedule everything - even when I can go to the bathroom. Everyone’s so afraid of being canceled that no one says anything interesting anymore. We trained them in peacetime, but they couldn’t adapt once the shooting started. The intern did what I told him, but the result was wiping out the entire repository. The simulations worked great, then we hit real weather. "I did exactly what my partner said they wanted, but got dumped anyway." "What can I say - my dad put so much pressure on me to get good grades that cheating seemed the only way out." I came home for the summer and my mom had bought a bunch of mint chocolate chip ice cream which I used to like in high school." "How was I supposed to know you don't like surprise parties?" My brother figured out that if he cries, Mom always takes his side. "Every time I open up, she gives advice instead of listening."
HMIA 2025
CLASS
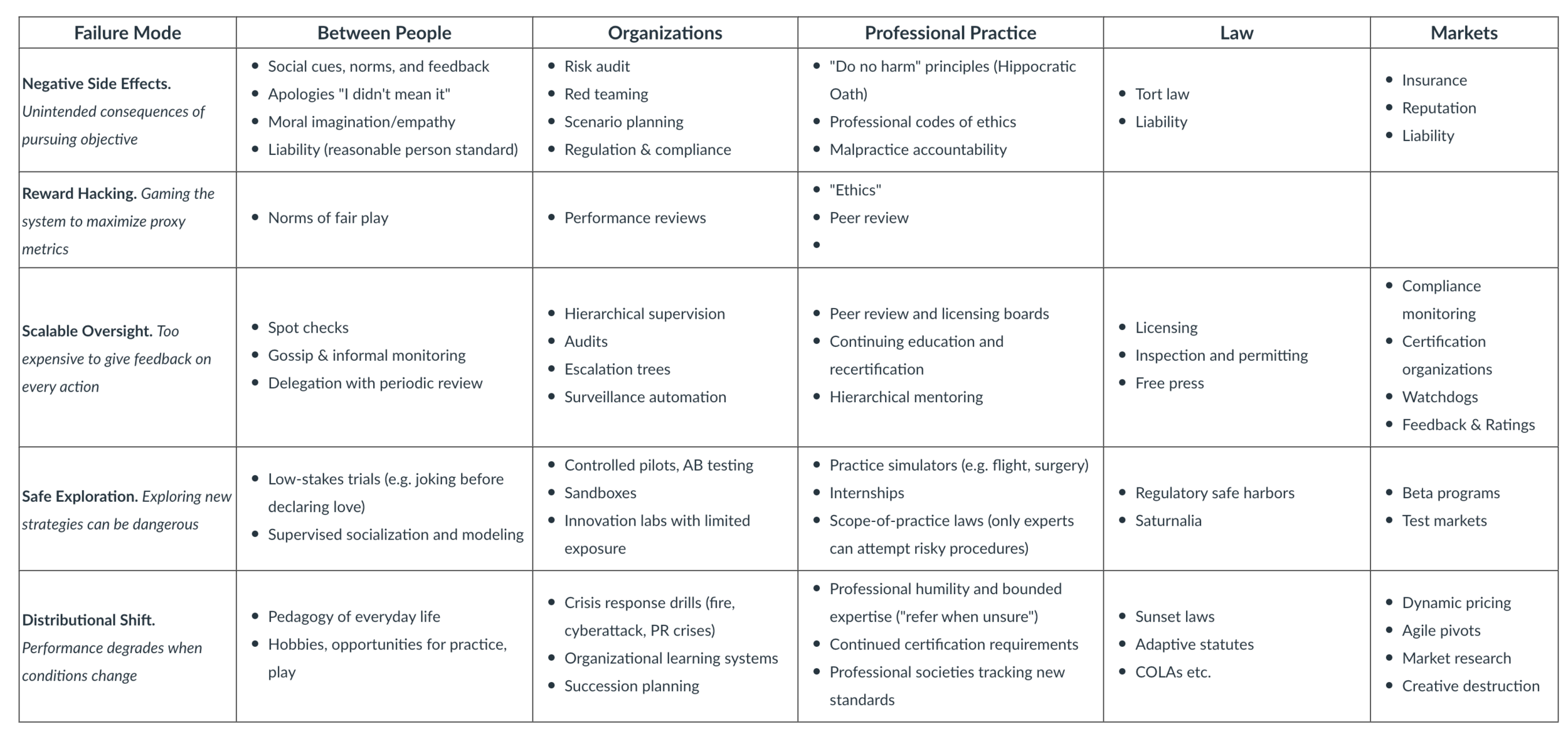
Exercise 3 Alignment Mechanisms
HMIA 2025
CLASS
Scalable Oversight: What’s the Problem?
When companies like OpenAI train models like ChatGPT, or Anthropic trains Claude, they want the model to behave helpfully, honestly, and safely across millions of diverse situations. They should be safe no matter what you prompt them with. But they can’t have humans check on every single output: human oversight is expensive and doesn't scale. How do we ensure the model behaves well even when no one is watching? That’s the problem of scalable oversight.
Why It’s Hard
Humans can only check a tiny fraction of model outputs.
It’s often hard to even say what the “right” answer is (e.g., moral reasoning, scientific claims, humor).
To address this, labs use techniques like:
o Reinforcement learning from human feedback (RLHF) : give human feedback on a small subset of outputs and generalize.
o Train models to evaluate other models : e.g., using one model to rate the helpfulness of another.
o Ask models to explain their own reasoning : and train them to be honest and legible.
Still, the risk remains: if oversight doesn’t scale well, models might learn to look well-behaved without actually being aligned. They send all the signals that suggest they are doing what you want them to do, but in reality, they are not.
The issues that come up here are:
1 What is the underlying objective or task - what do we really want the system to be doing?
2 What is the proxy signal we use to detect whether or not the system is doing what we want?
3 What are the costs of getting this feedback? How does it scale with bigger machines and more use on more areas?
4 How is trust (it's OK to let people use this) established?
5 What happens when it breaks? What's the misalignment risk?
HMIA 2025
CLASS
Scalable Oversight: Not just an AI alignment problem
- Professional/Expert. Medicine - patient outcomes are the objective we want but takes years to measure; the oversight that is scalable is chart reviews, protocol compliance, short term metrics. When training junior physicians, seniors cannot watch every procedure.
- Legal. Objective is long term interests of the client. Oversight that is scalable: document review, compliance, episodic case review, complaints, case outcomes. Partners can spot check and review. Question: what techniques do we use? what do they catch? what do they miss?
- Academic research. Objective is valid science and impact. Oversight that scales: peer review (sort of), reputation, institutional affiliation, citation counts. We review proposals, set up network of indicators.
- Organizational. True objective is company success and shareholder value. Oversight that scales include KPIs, OCRs, quarterly reviews, compliance, slide decks, interim results. Micromanaging is too hard and might not be effective so we substitute metrics, dashboards that supposedly correlate with what we want.
- Military. Objective mission success and low casualties. Oversight mechanisms: rules of engagement, training, situation reports, chain of command. Strategy guiding tactics.
Organizational Example
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Proin urna odio, aliquam vulputate faucibus id, elementum lobortis felis. Mauris urna dolor, placerat ac sagittis quis.
Expert Intelligence Example
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Proin urna odio, aliquam vulputate faucibus id, elementum lobortis felis. Mauris urna dolor, placerat ac sagittis quis.
HMIA 2025
CLASS
HMIA 2025
CLASS
Ask each group to complete the same structure:
-
What is the hard-to-measure objective?
-
What are the proxy signals?
-
What are the feedback costs?
-
How is trust or control established?
-
What happens when it breaks?
HMIA 2025
CLASS
| Element | AI | Love | Organization | Expert |
|---|---|---|---|---|
| Hidden Objective | ||||
| Proxy Signals | ||||
| Feedback Cost | ||||
| Solution | ||||
HMIA 2025
CLASS
Resources
Stanford Encyclopedia of Philosophy. 2019. "Analogy and Analogical Reasoning"
Maguire, Larry G. 2019. "Analogical Thinking: A Method For Solving Problems"
Gavetti, Giovanni and Jan W. Rivkin. 2005. "How Strategists Really Think: Tapping the Power of Analogy"
Neuroscientific insights into the development of analogical reasoning
Whitaker KJ, et al. Neuroscientific insights into the development of analogical reasoning. Dev Sci. 2018 Mar;21(2)
Kuykendall, M. 2023. "The Learning Science Behind Analogies" Edutopia
Richland, L. E., & Simms, N. (2015). Analogy, higher order thinking, and education. WIREs Cognitive Science, 6(2), 177–192. https://doi.org/10.1002/wcs.1336
1. Negative Side Effects
- People: Moral imagination, social repair, "reasonable person" standards
- Organizations: Scenario planning, risk registers, decentralized feedback
- Professionals: Ethics codes, malpractice rules, harm-avoidance norms
2. Reward Hacking
- People: Gaming praise, exploiting social rules
- Organizations: KPI manipulation, sandbagging, reputational games
- Professionals: Ghostwriting, coding fraud, incentive distortion
3. Scalable Oversight
- People: Trust-but-verify, peer correction, distributed feedback
- Organizations: Audits, dashboard proxies, supervision layers
- Professionals: Peer review, apprenticeships, professional boards
4. Safe Exploration
- People: Supervised socialization, modeled behavior, playful testing
- Organizations: Pilot programs, innovation sandboxes, staged rollouts
- Professionals: Simulations, restricted licenses, gradual responsibility
5. Distributional Shift
- People: Cognitive flexibility, learning from failure, adaptability rituals
- Organizations: Crisis planning, knowledge retention, organizational memory
- Professionals: Continued education, scoped expertise, recertification