Amazon Bedrock
Hands-On
Demo

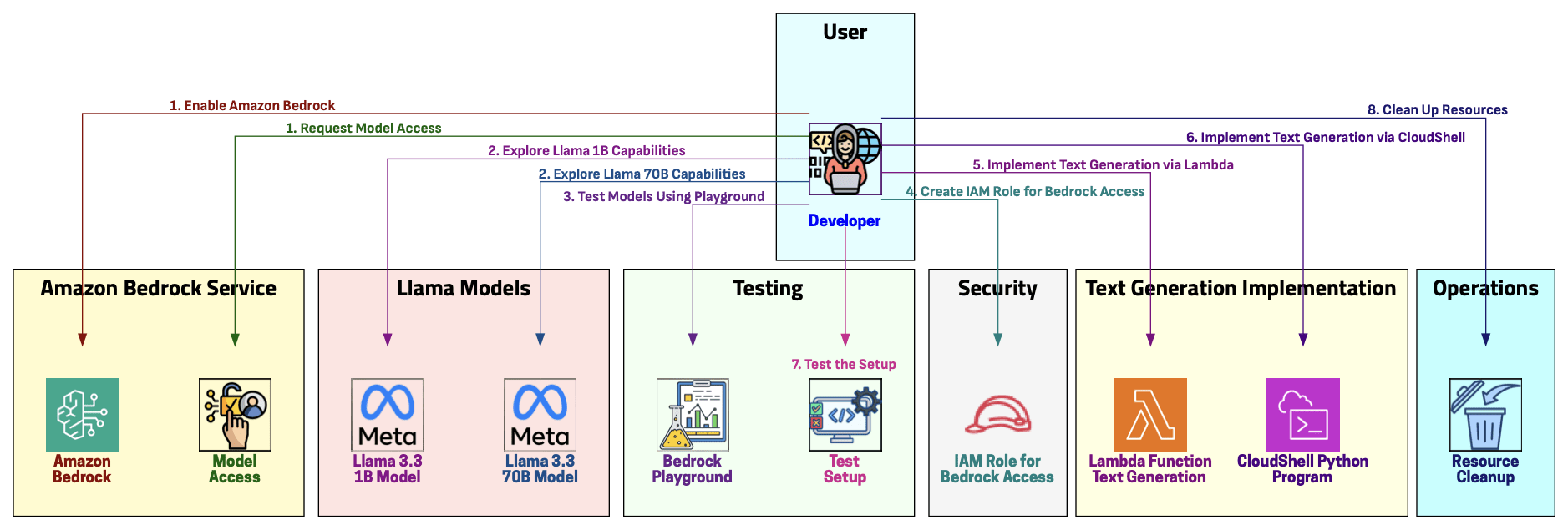
In this demo, we will:
- Enable Amazon Bedrock and request model access
- Explore the Llama 3.3 1B and 70B model capabilities
- Test models using the Bedrock playground
- Create an IAM role for Bedrock access
- Implement a text generation use case via Lambda Function
- Implement a text generation use case via CloudShell Python Program
- Test the setup
- Clean up resources
Agenda
Visual Representation
Amazon Bedrock - Manual Testing via the AWS Console
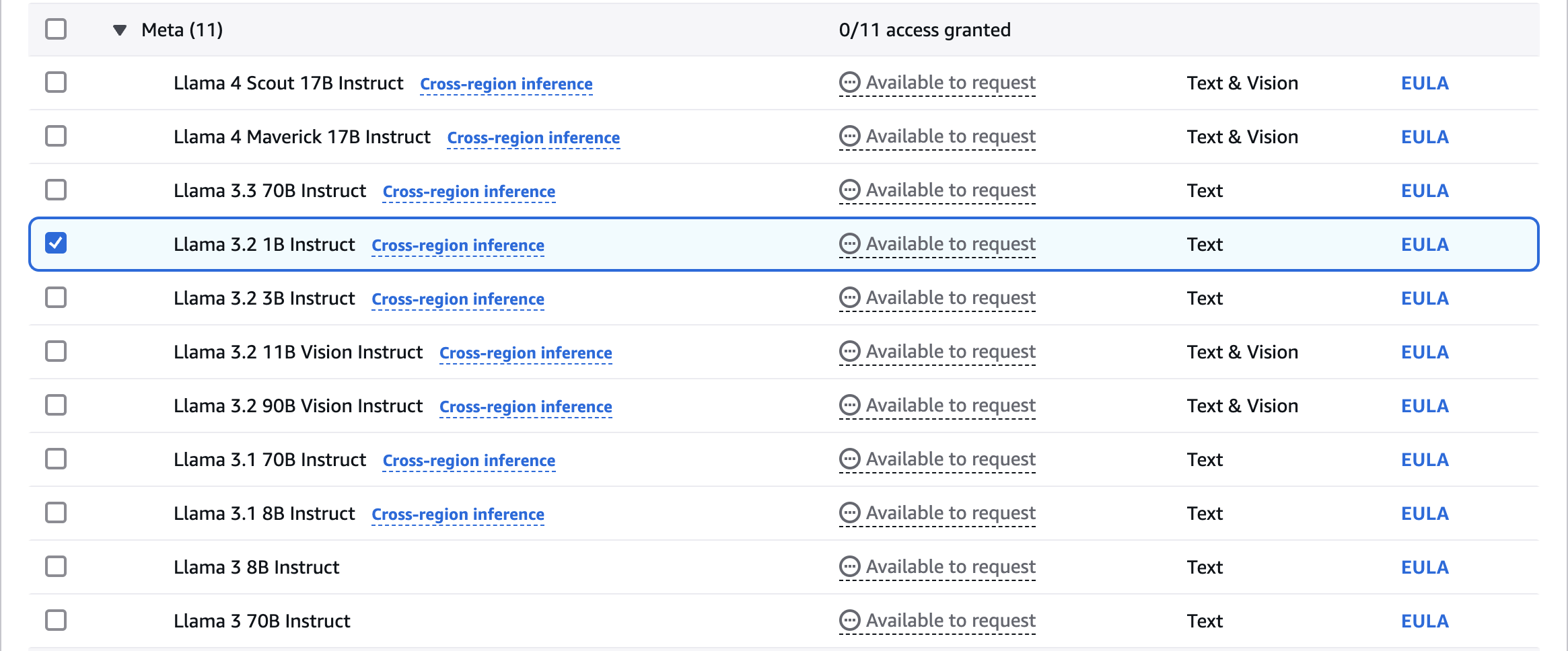
Request for Model Access
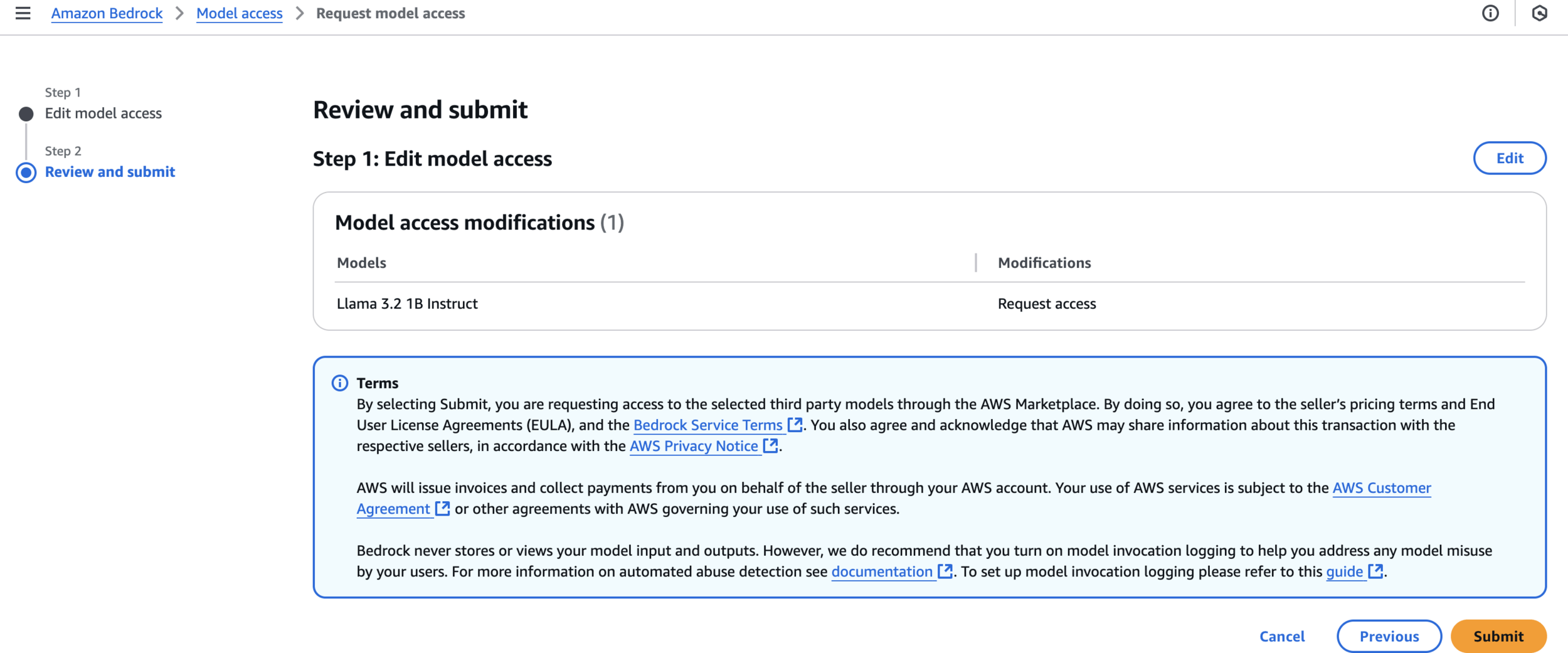
Review and submit
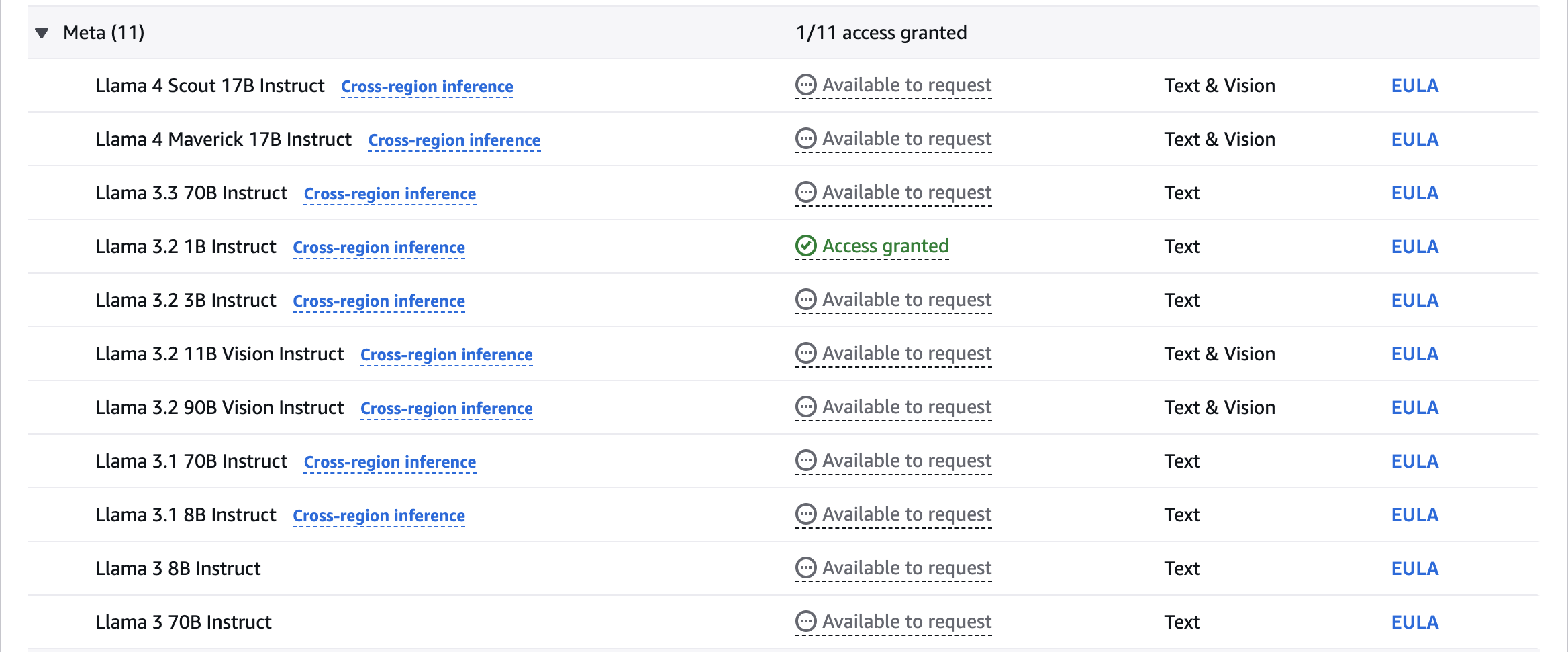
Access granted
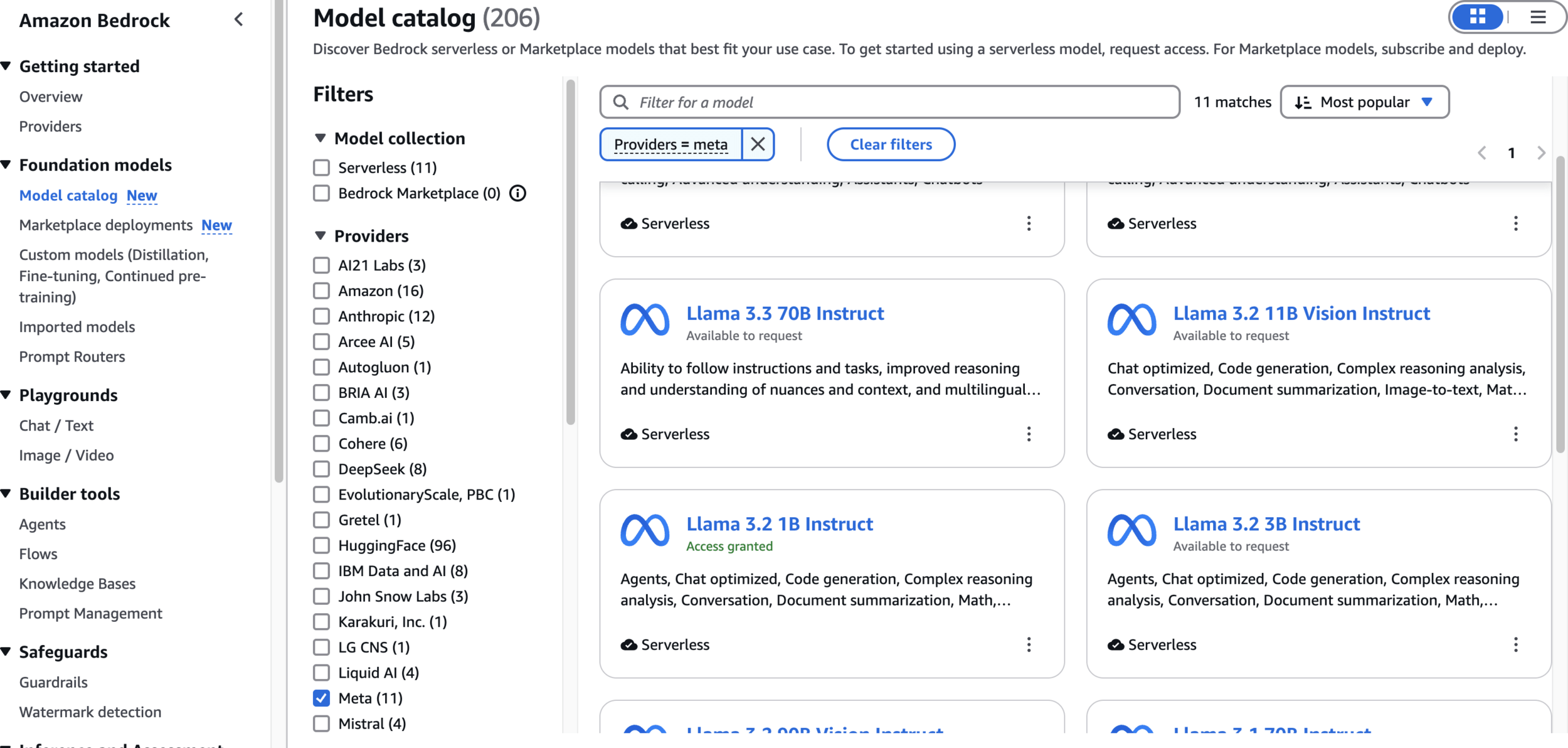
Model catalog
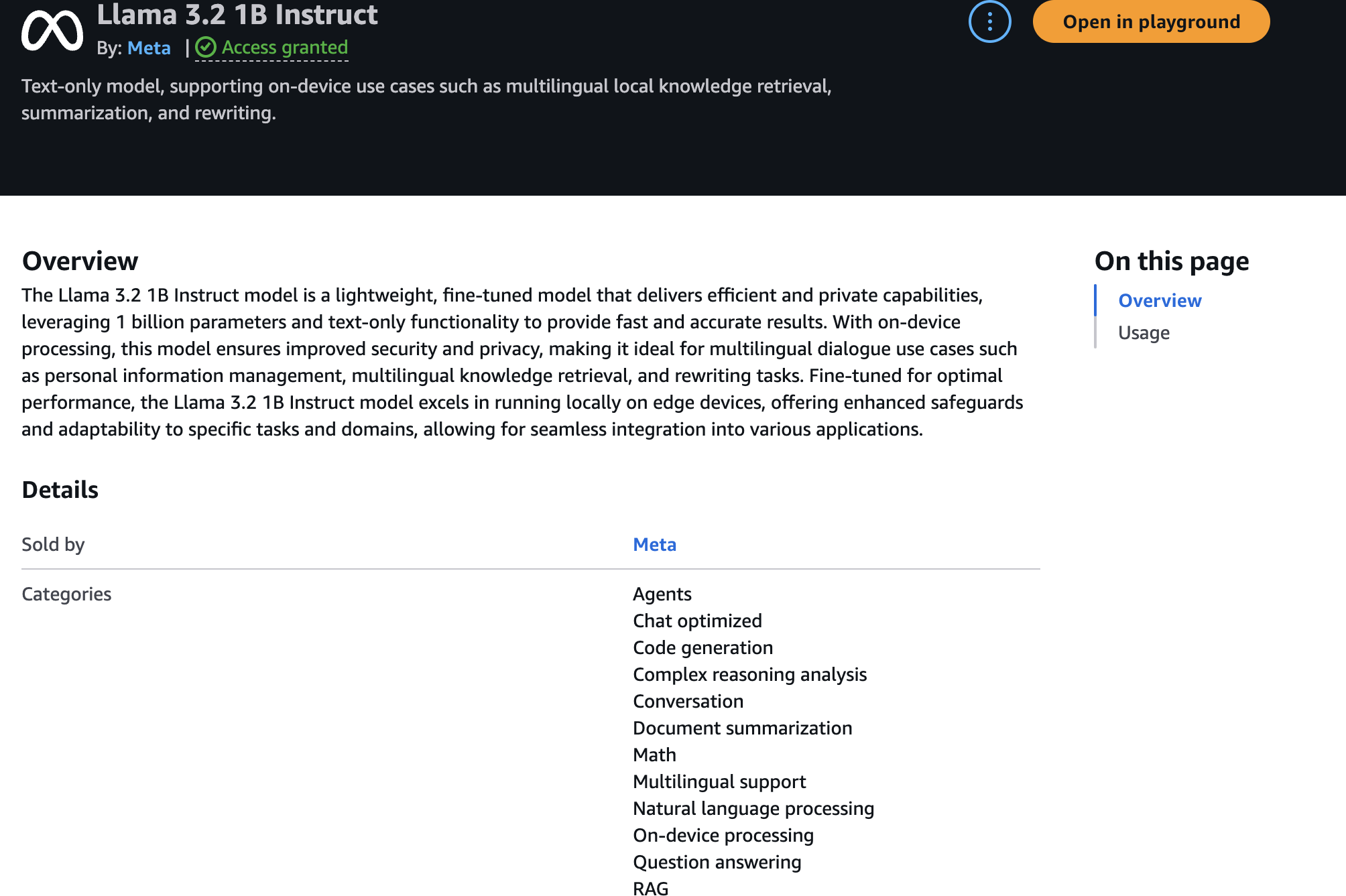
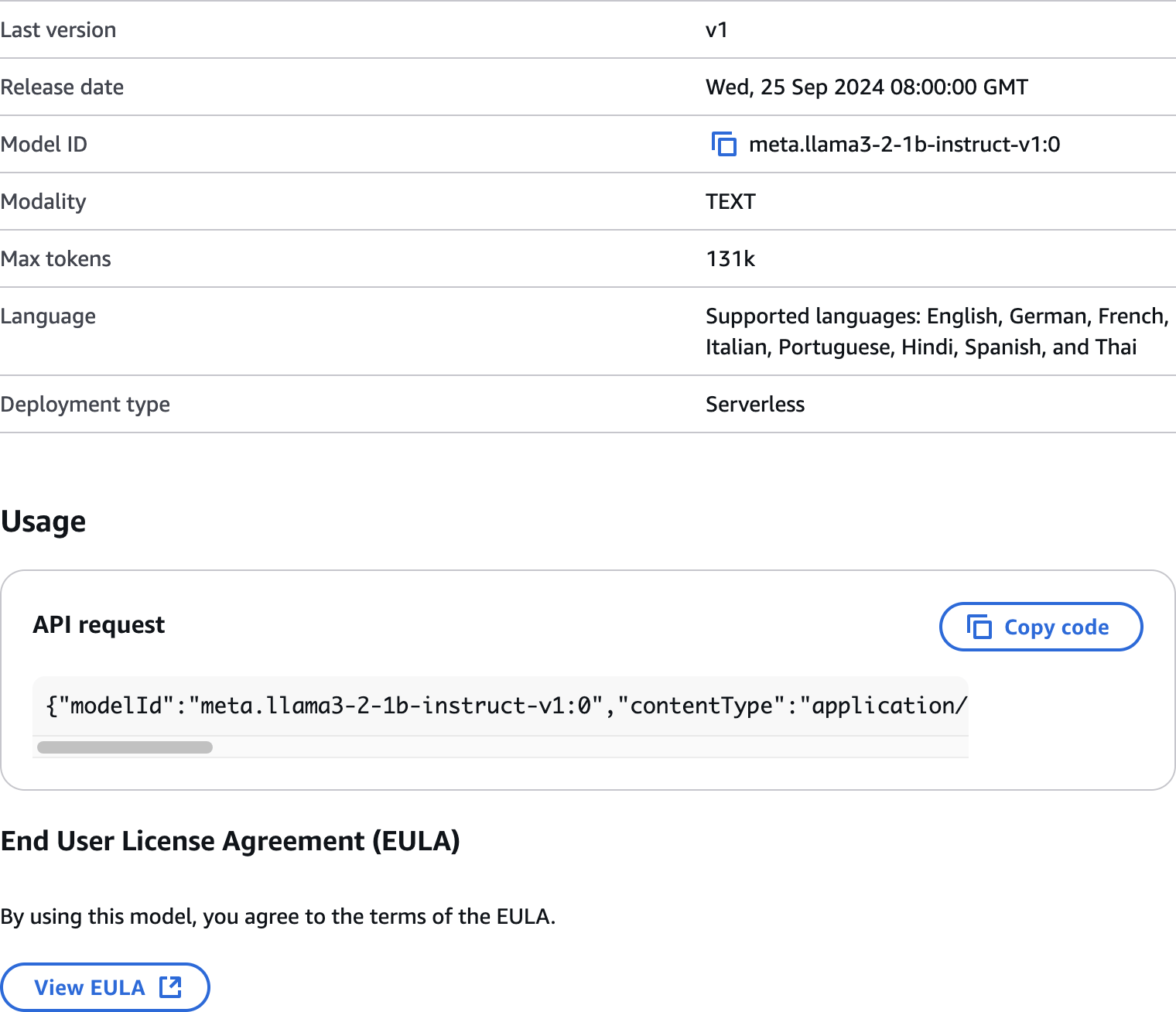
Playground
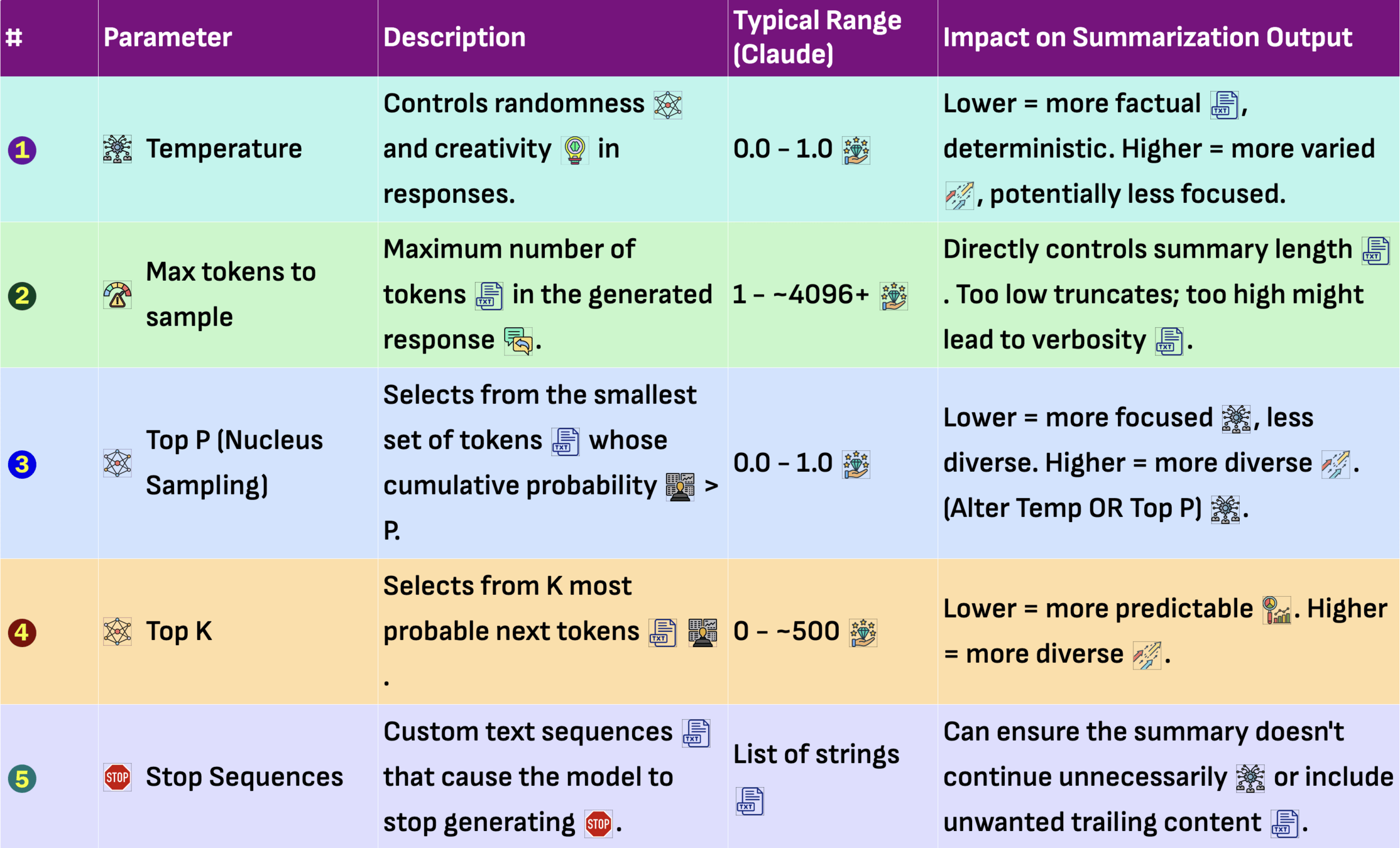
Explain the benefits of using Amazon Bedrock for enterprise applications in 3 bullet pointsPrompt
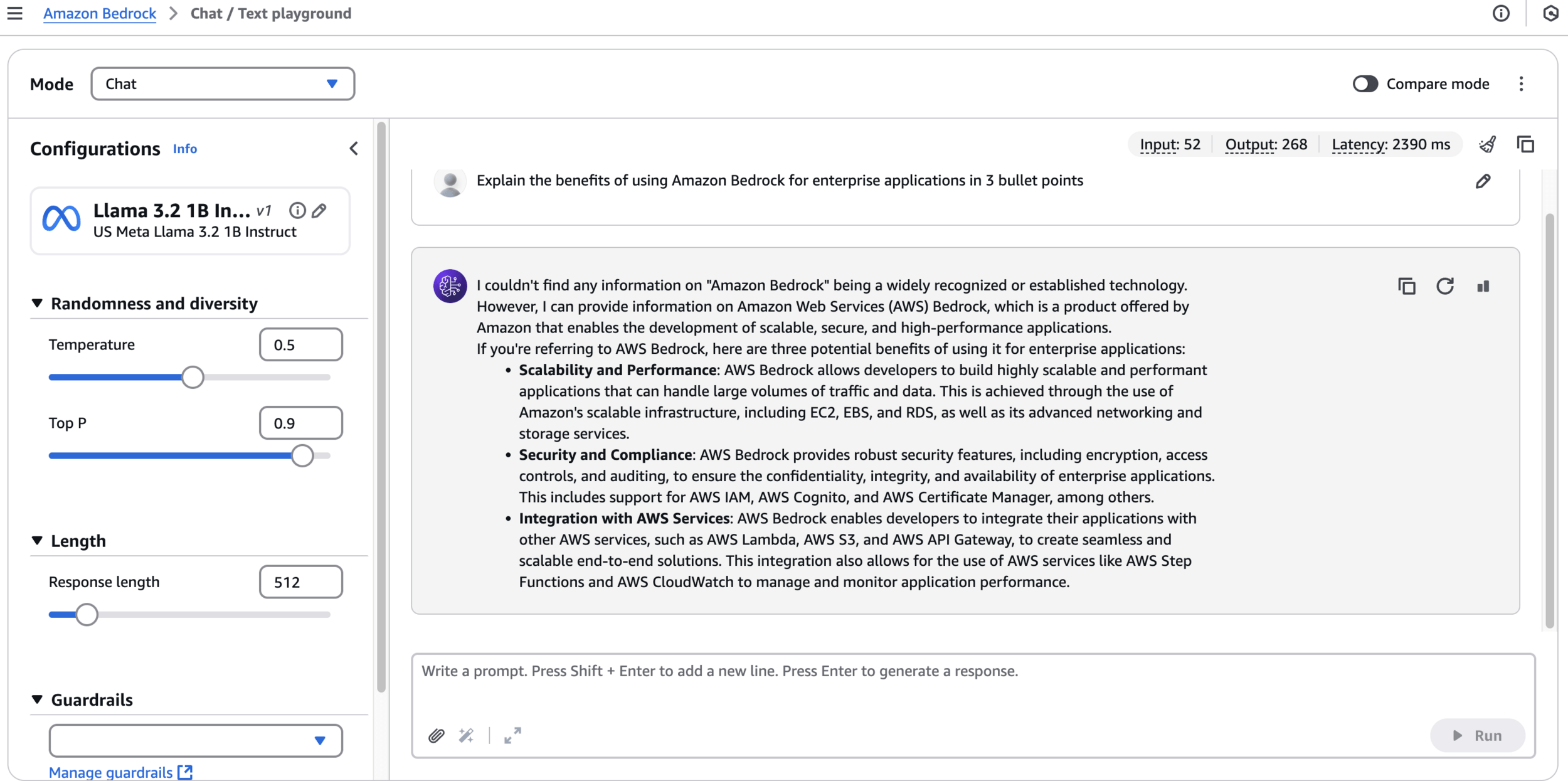
Response
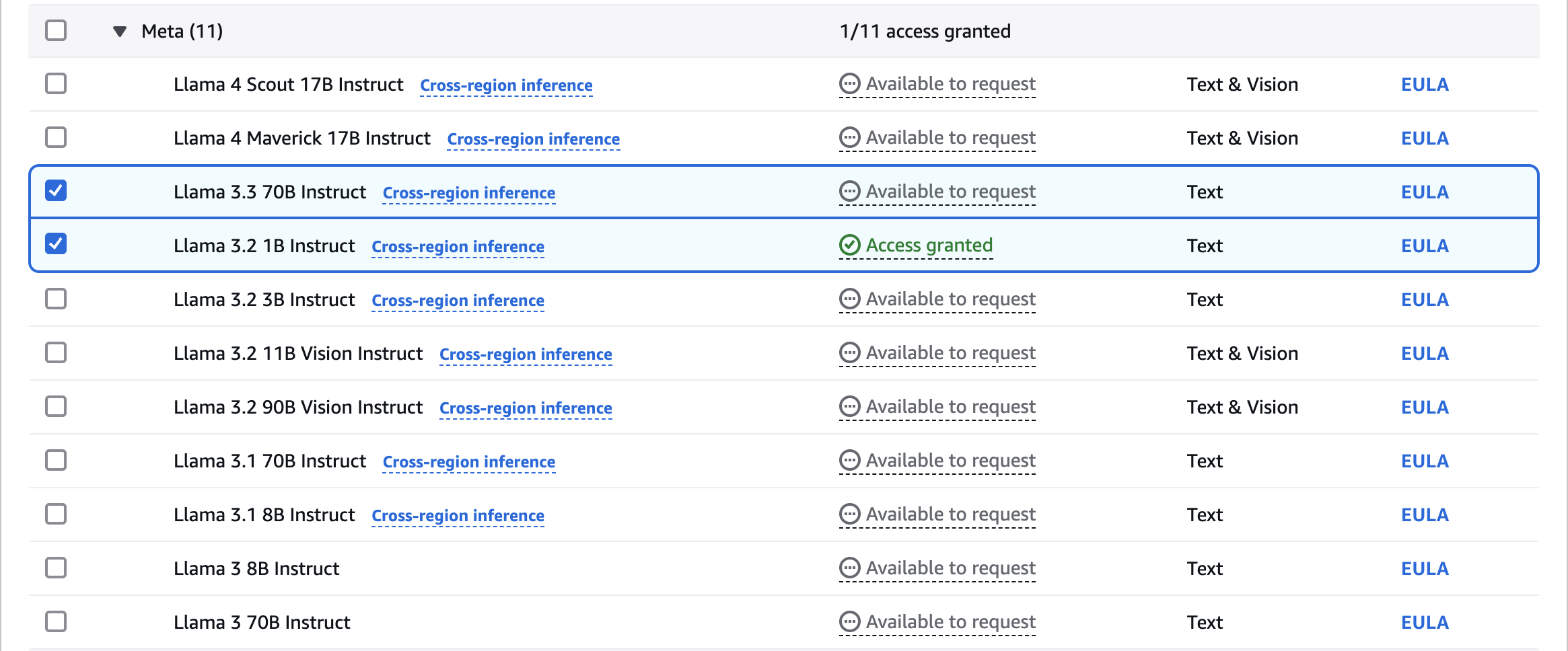
Access granted
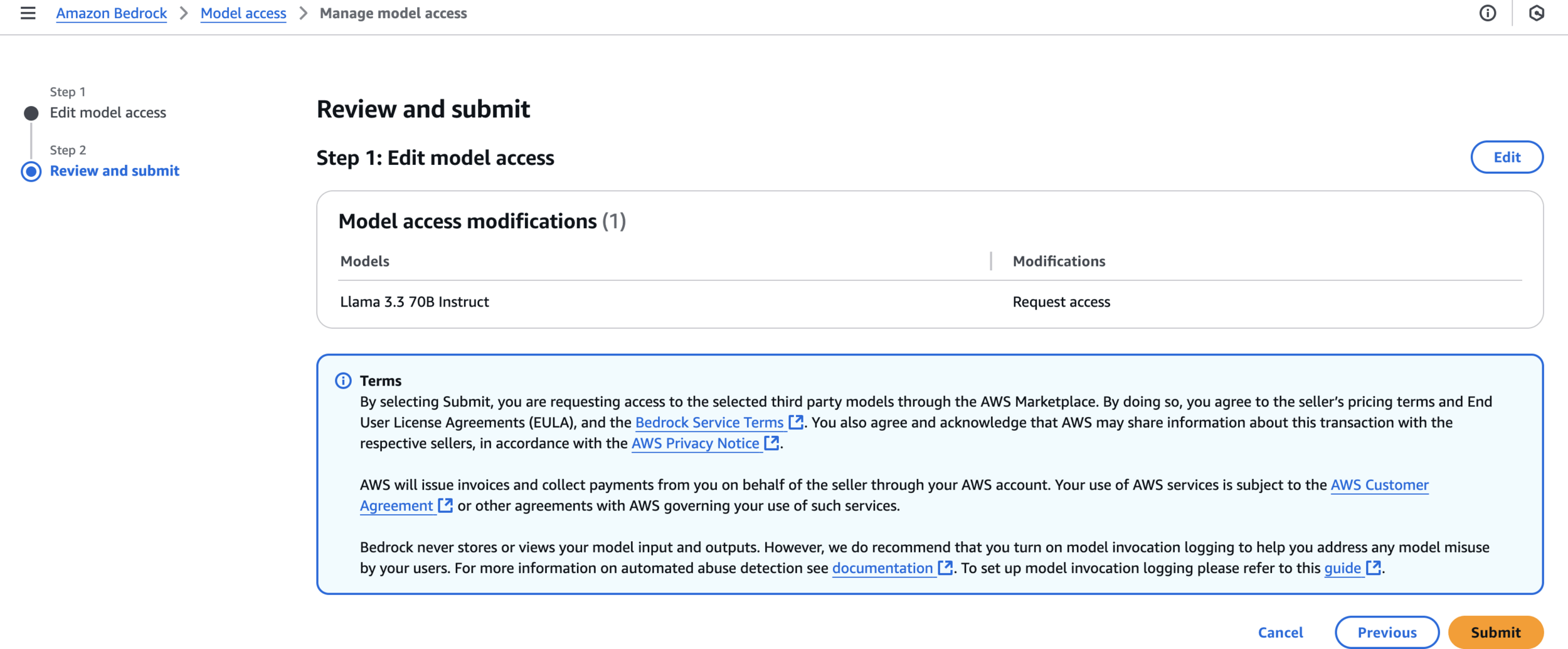
Review and submit
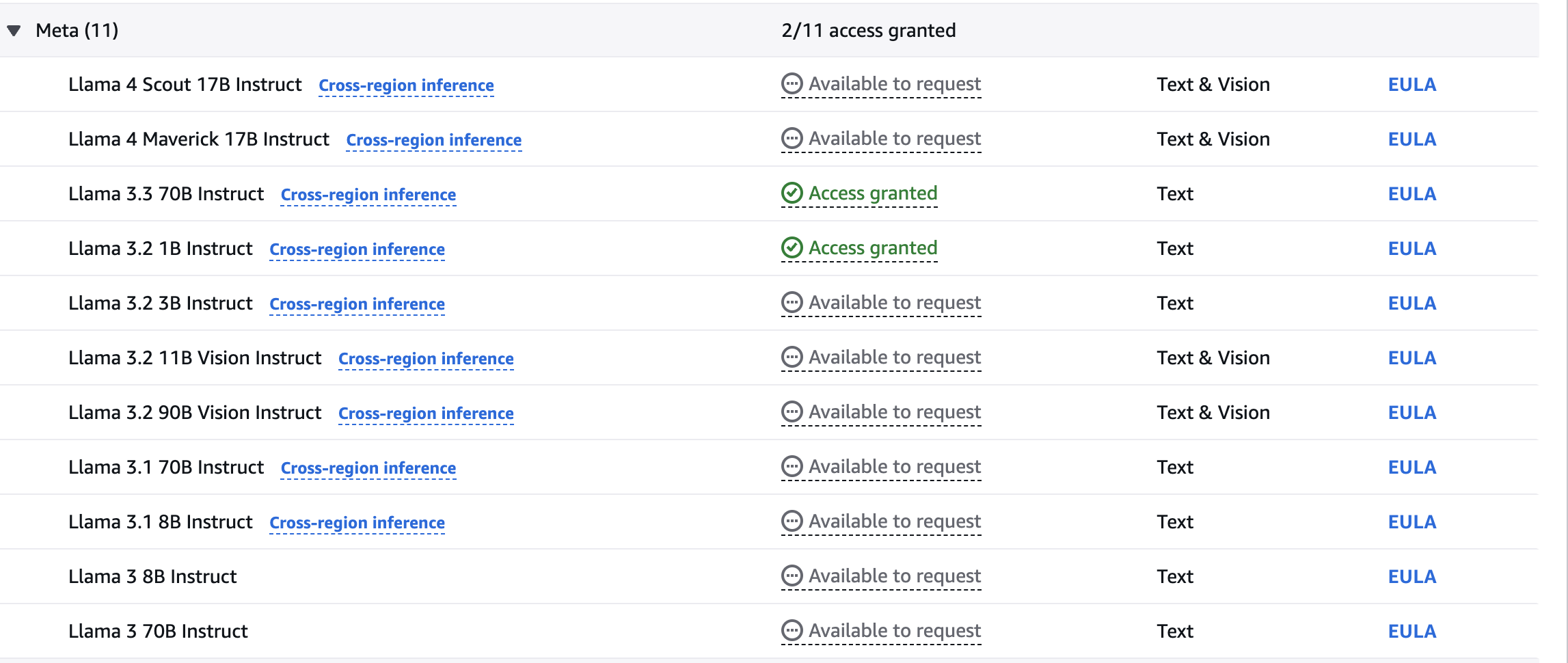
Access granted
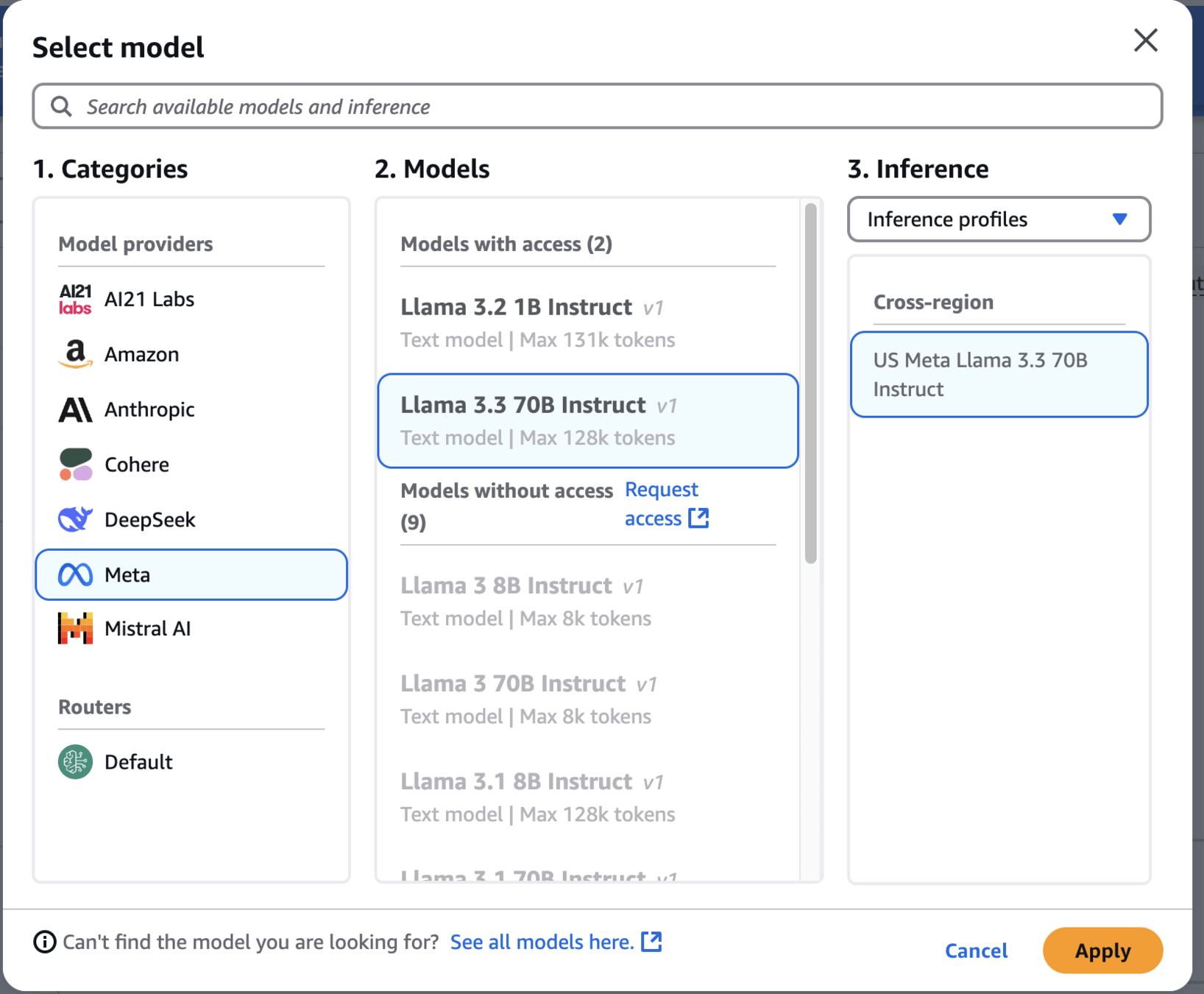
Change Model
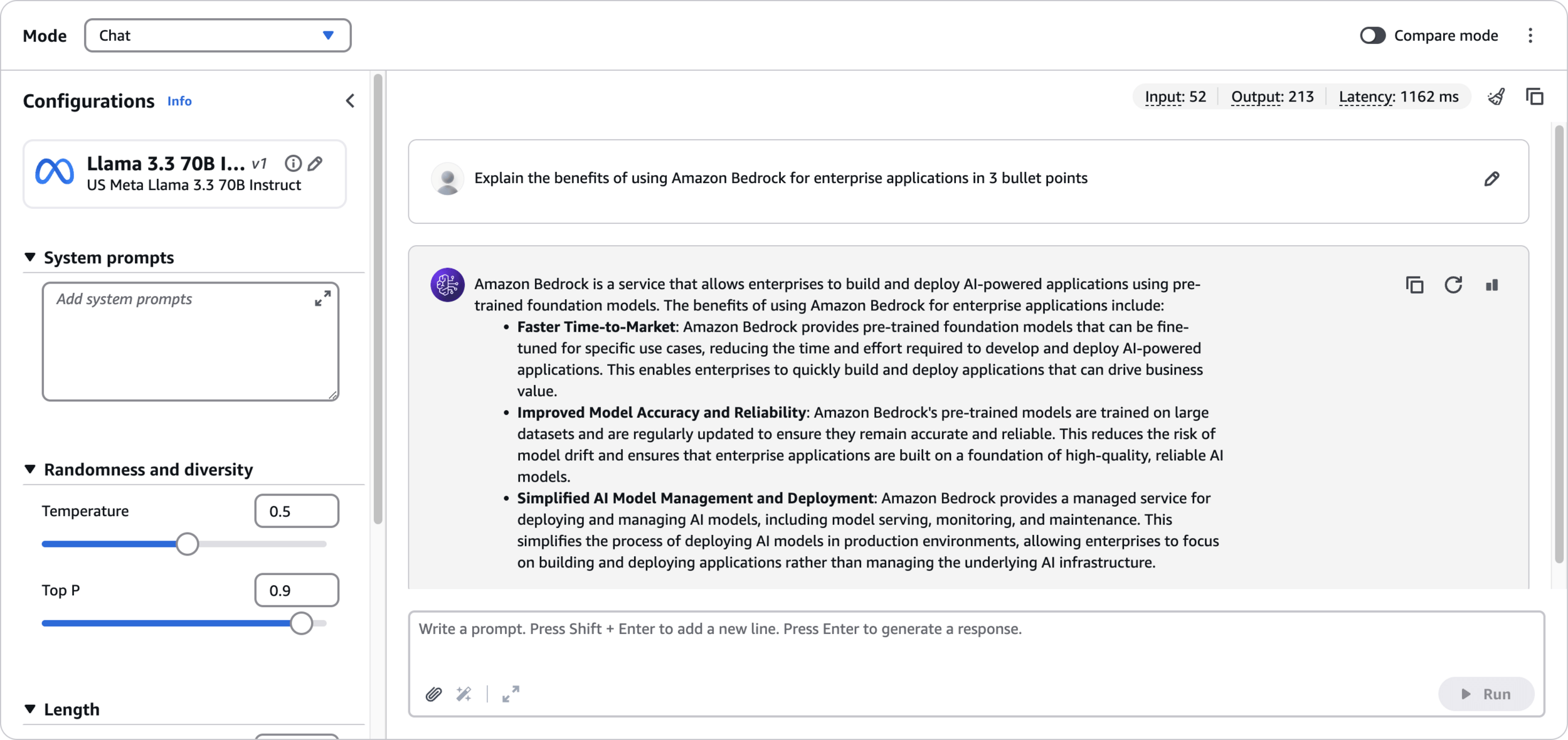
Response
Create IAM Role for Lambda Function
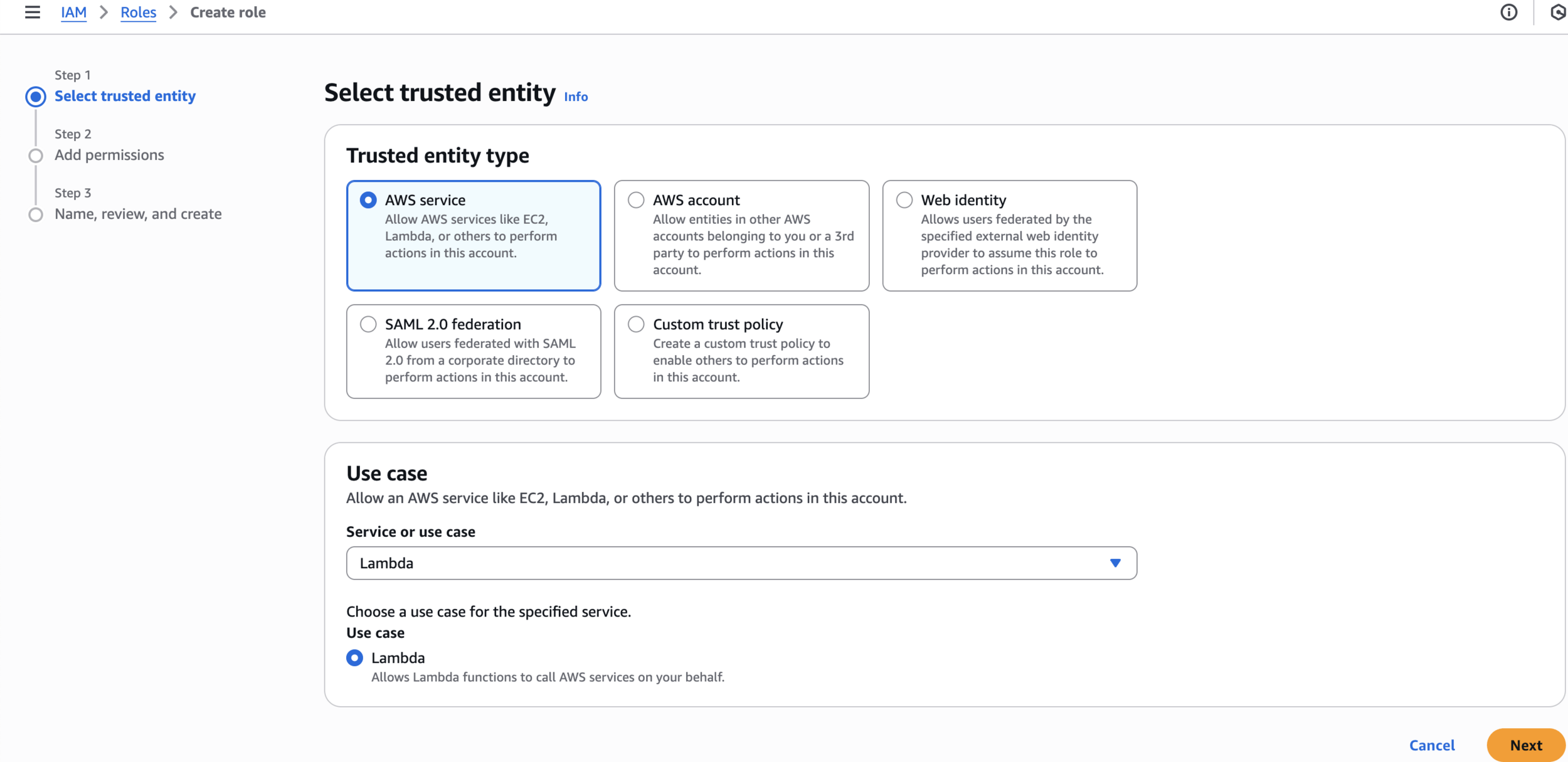
Select AWS Service
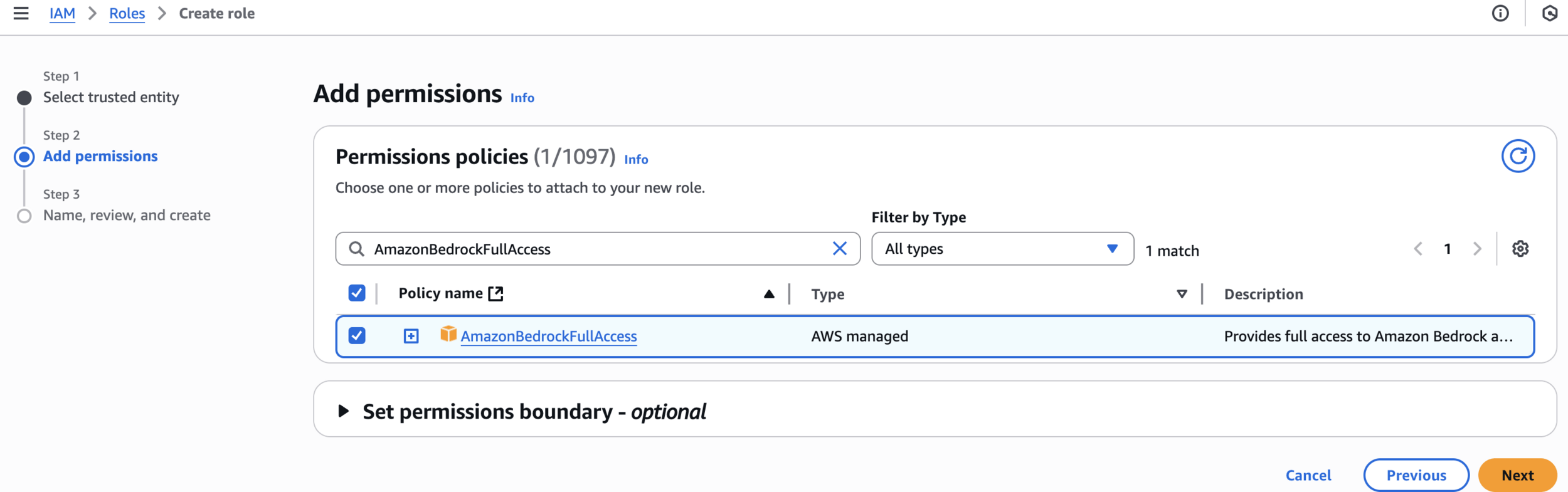
AmazonBedrockFullAccessAdd permissions

Name, review, and create
BedrockLabRole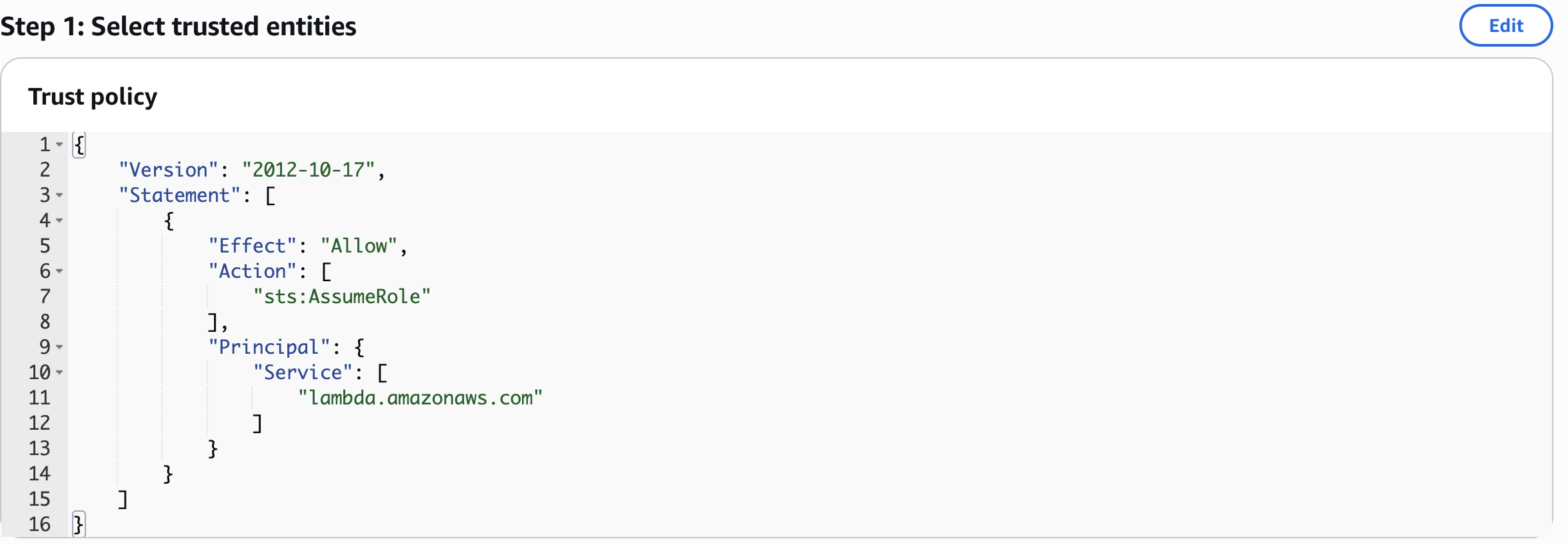
Review
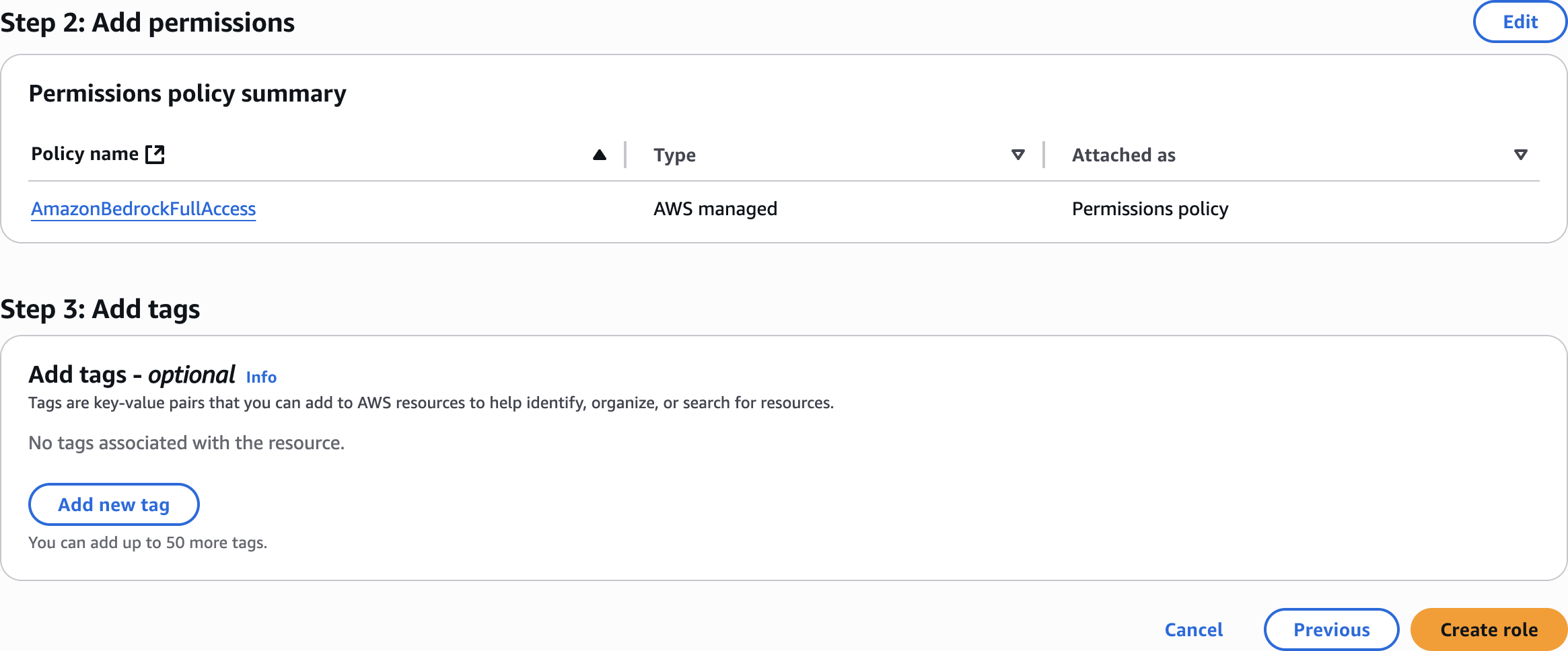
Review and Create role
Lambda Function
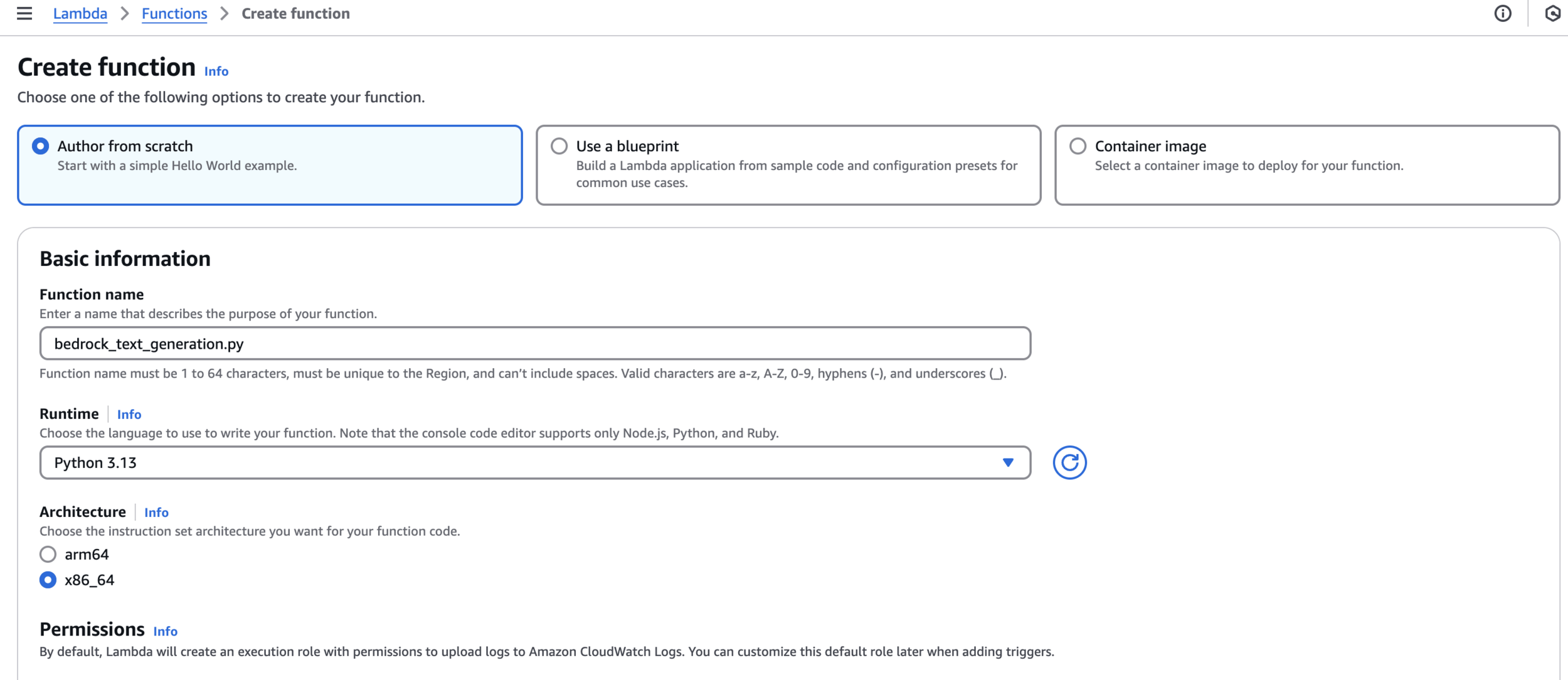
Create Lambda Function
bedrock_text_generation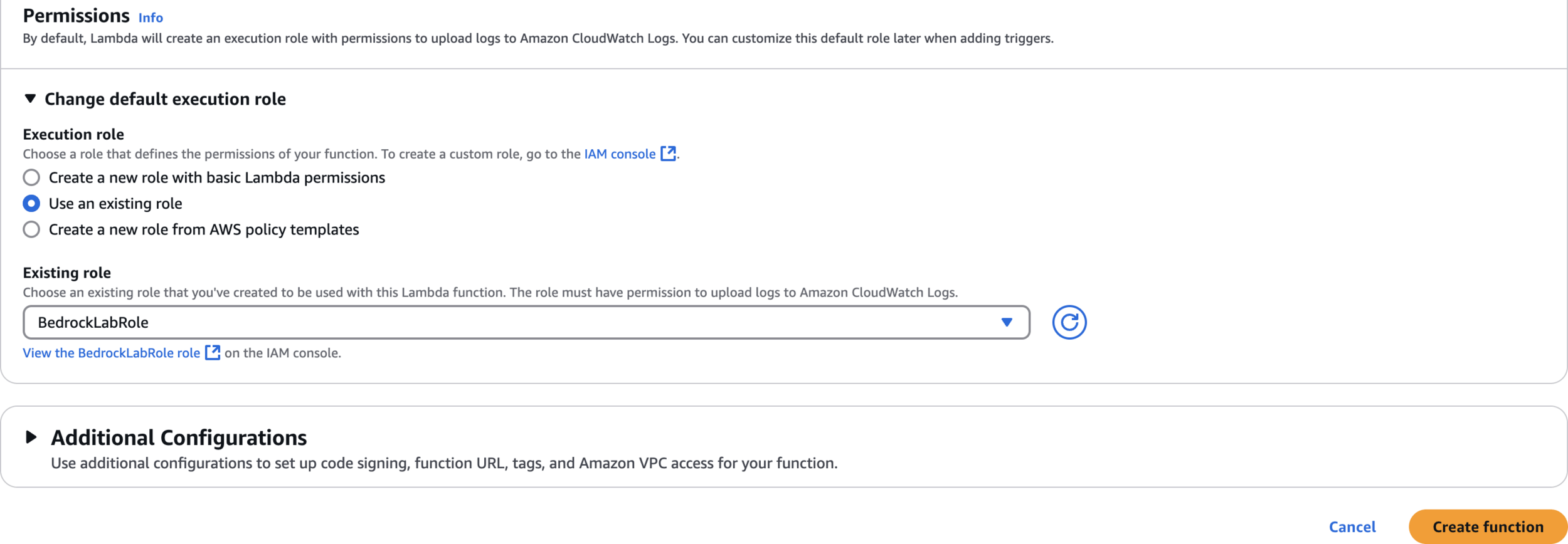
Use an existing role
Additional Configurations
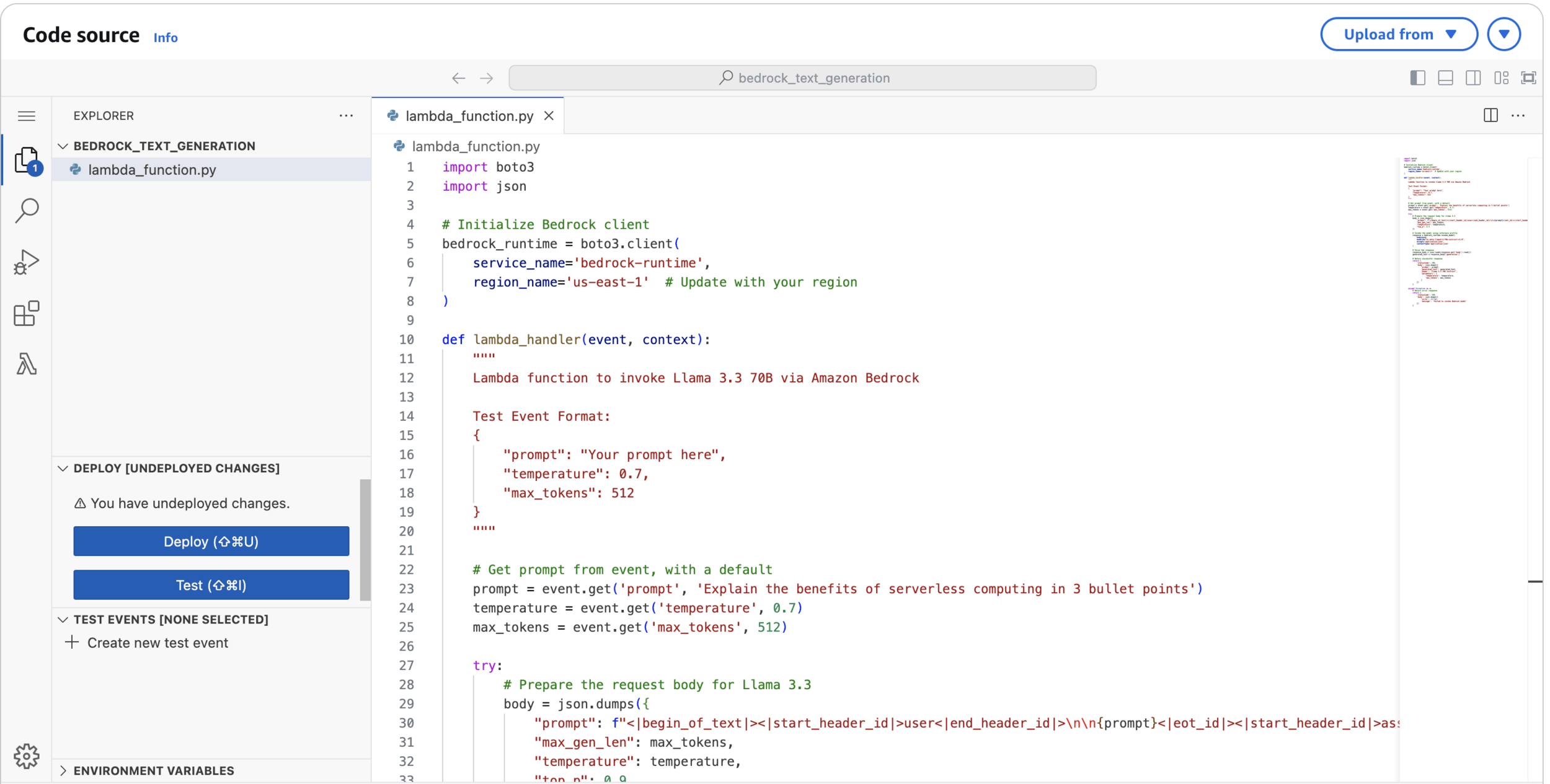
import boto3
import json
# Initialize Bedrock client
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-east-1' # Update with your region
)
def lambda_handler(event, context):
"""
Lambda function to invoke Llama 3.3 70B via Amazon Bedrock
Test Event Format:
{
"prompt": "Your prompt here",
"temperature": 0.7,
"max_tokens": 512
}
"""
# Get prompt from event, with a default
prompt = event.get('prompt', 'Explain the benefits of serverless computing in 3 bullet points')
temperature = event.get('temperature', 0.7)
max_tokens = event.get('max_tokens', 512)
try:
# Prepare the request body for Llama 3.3
body = json.dumps({
"prompt": f"<|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\n{prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n",
"max_gen_len": max_tokens,
"temperature": temperature,
"top_p": 0.9
})
# Invoke the model using inference profile
response = bedrock_runtime.invoke_model(
body=body,
modelId="us.meta.llama3-3-70b-instruct-v1:0",
accept='application/json',
contentType='application/json'
)
# Parse the response
response_body = json.loads(response.get('body').read())
generated_text = response_body['generation']
# Return successful response
return {
'statusCode': 200,
'body': json.dumps({
'prompt': prompt,
'generated_text': generated_text,
'model': 'Llama 3.3 70B Instruct',
'parameters': {
'temperature': temperature,
'max_tokens': max_tokens
}
})
}
except Exception as e:
# Return error response
return {
'statusCode': 500,
'body': json.dumps({
'error': str(e),
'message': 'Failed to invoke Bedrock model'
})
}Lambda Code
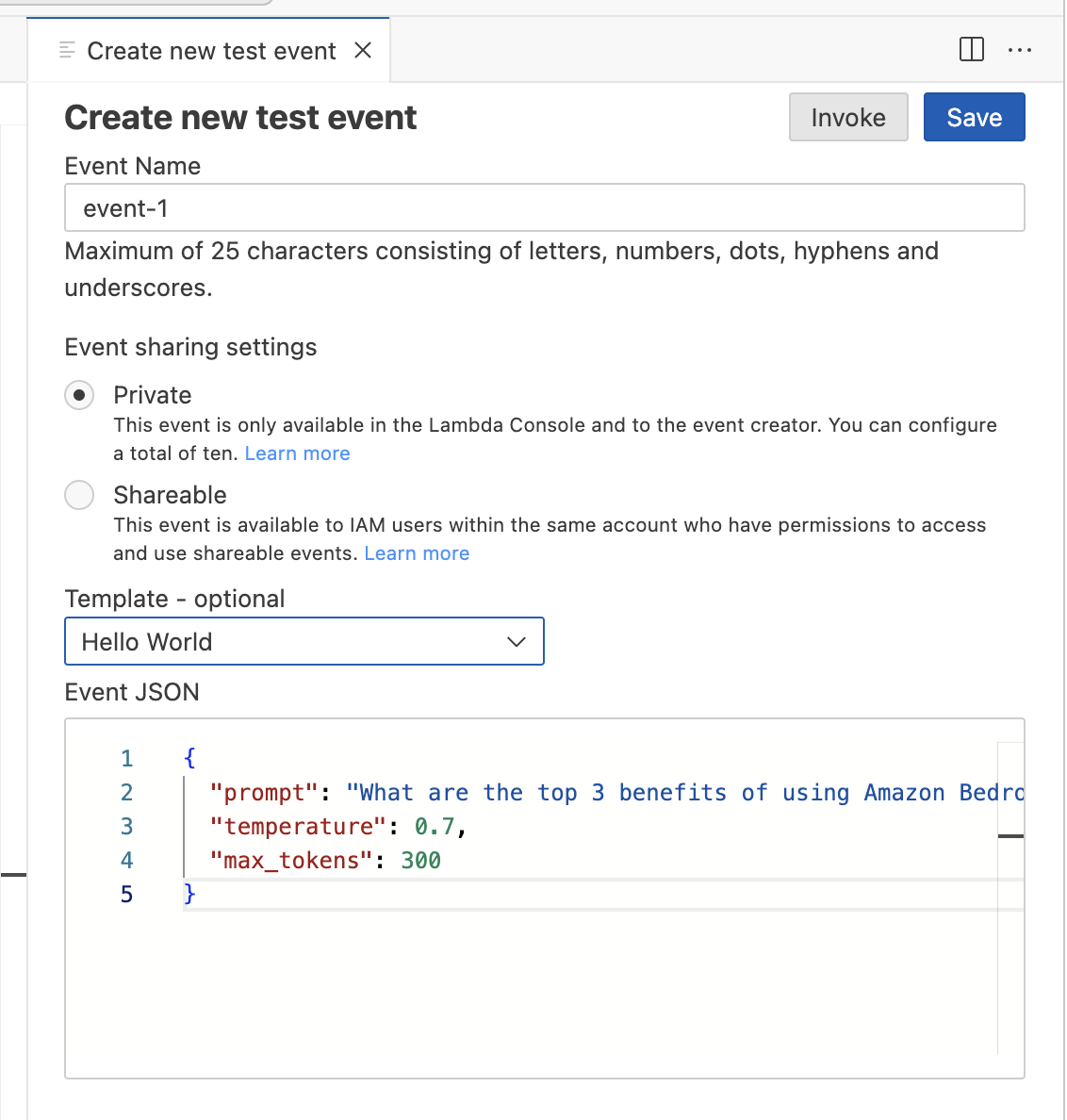
{
"prompt": "What are the top 3 benefits of using Amazon Bedrock?",
"temperature": 0.7,
"max_tokens": 300
}
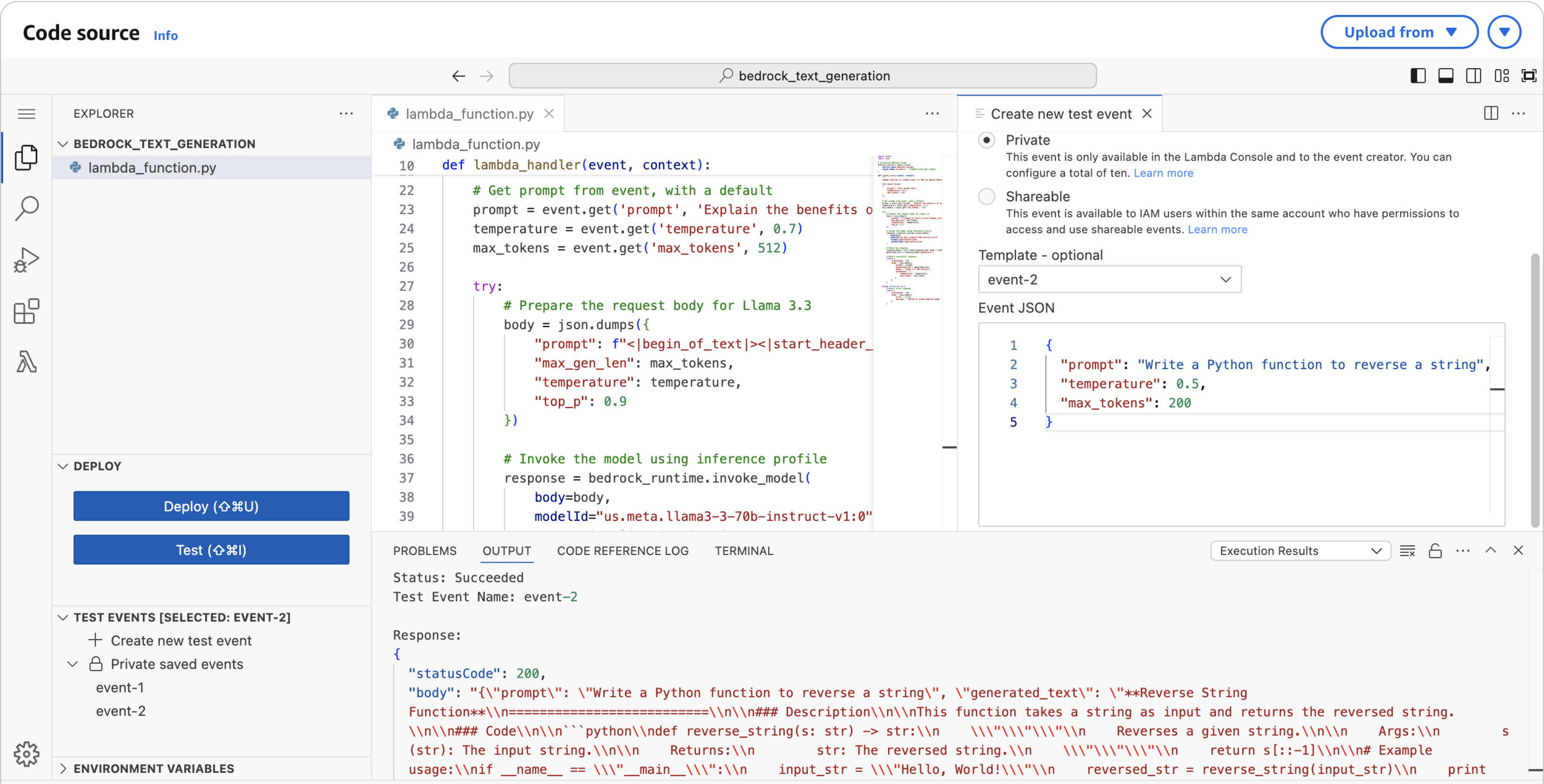
{
"prompt": "Write a Python function to reverse a string",
"temperature": 0.5,
"max_tokens": 200
}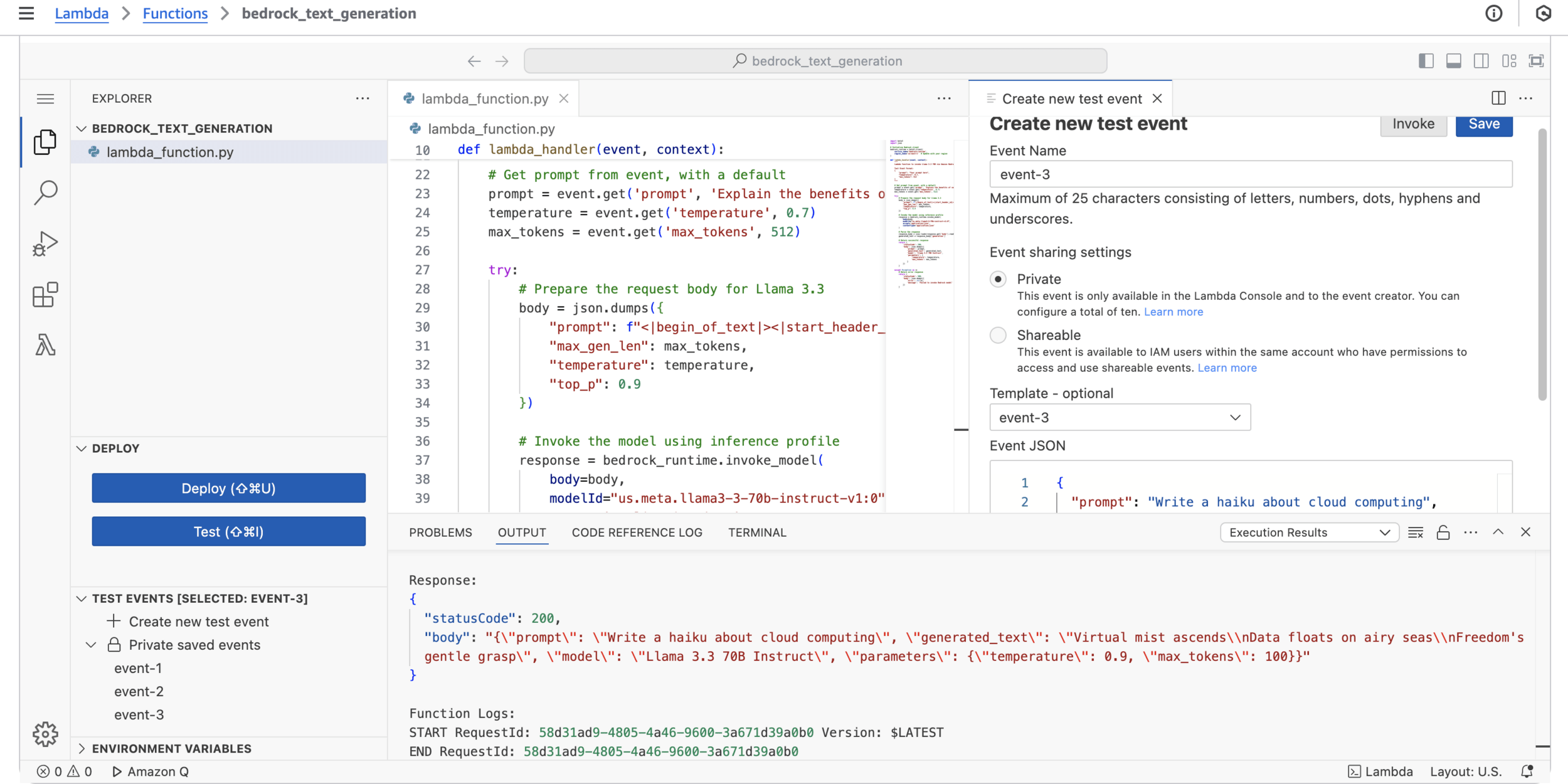
{
"prompt": "Write a haiku about cloud computing",
"temperature": 0.9,
"max_tokens": 100
}CloudShell

Test via CloudShell
cat << 'EOF' > bedrock_llama_generation.py
import boto3
import json
# Initialize Bedrock client
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-east-1' # Update with your region
)
def generate_text(prompt):
# Prepare the request body for Llama 3.3
body = json.dumps({
"prompt": f"<|begin_of_text|><|start_header_id|>user<|end_header_id|>\n\n{prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n",
"max_gen_len": 512,
"temperature": 0.7,
"top_p": 0.9
})
# Invoke the model using inference profile
response = bedrock_runtime.invoke_model(
body=body,
modelId="us.meta.llama3-3-70b-instruct-v1:0", # Using inference profile ID
accept='application/json',
contentType='application/json'
)
# Parse the response
response_body = json.loads(response.get('body').read())
return response_body['generation']
# Test the function
if __name__ == "__main__":
prompt = "Write a brief product description for an eco-friendly water bottle"
result = generate_text(prompt)
print("Generated Text:")
print(result)
EOFCommand Line Application

python3 bedrock_llama_generation.pyRun Application
Clean Up

Delete IAM Role
Delete IAM Role

Delete Lambda Function