Model Optimization

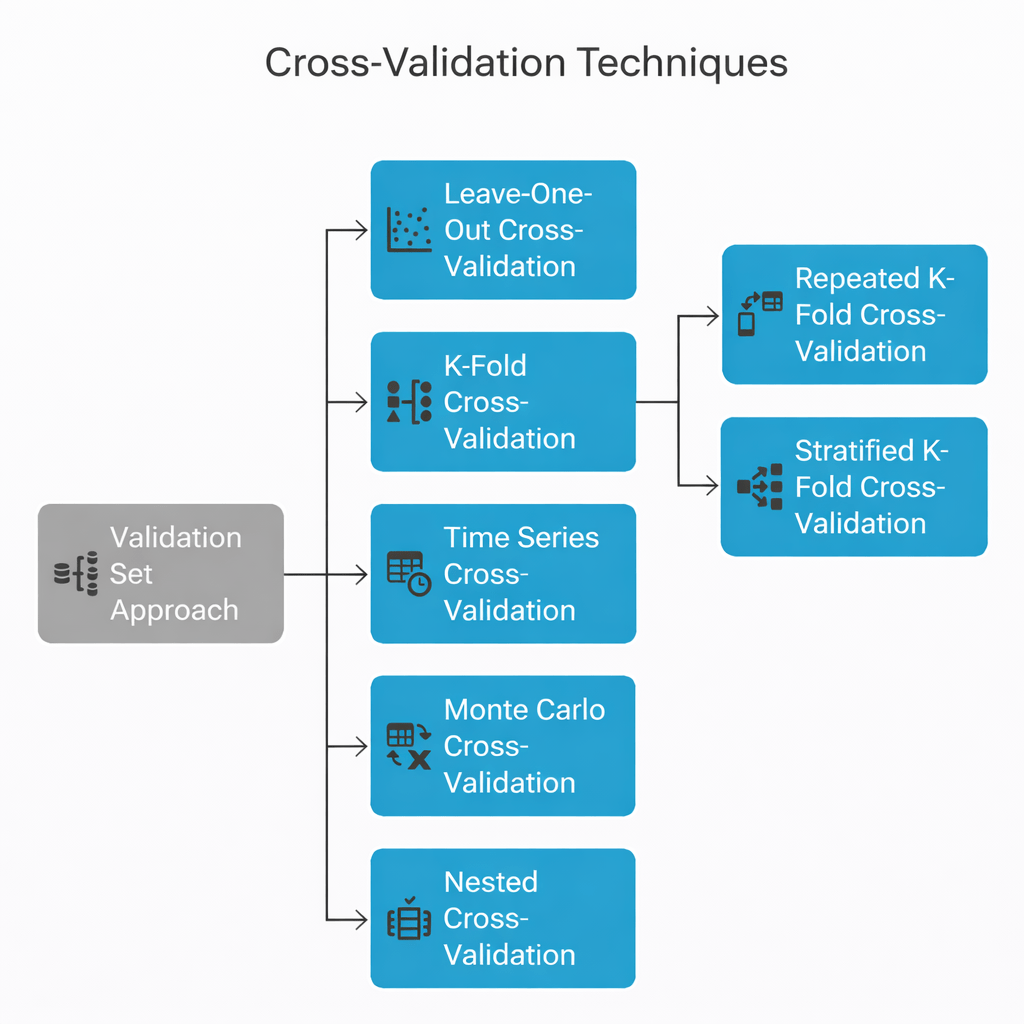
Cross-Validation Techniques


Learning Outcome
1
Understanding what Cross-Validation is.
2
Understand why cross-validation is important in machine learning.
3
Describe different cross-validation techniques.
4
Implement K-Fold Cross-Validation using Scikit-Learn.
5
Understand the role of Stratified K-Fold for classification tasks.
6
Use cross-validation to evaluate machine learning models more reliably.
Recall: Train-Test Split
Basic evaluation method:
Divide dataset into two subsets
Train on one, test on the other

Example Split
+
20%
Testing set
80%
Training set
Limitations:
Model performance may depend heavily on the specific split.
A lucky split may produce very high accuracy.
A poor split may produce low accuracy even if the model is good.
Model performance may depend heavily on the specific split.
This issue motivates the use of cross-validation, which evaluates models across multiple data splits
This issue motivates the use of cross-validation, which evaluates models across multiple data splits
You are preparing for an important exam....
You take one practice test:

You score: 85%
But does that really prove you're ready?
Maybe that test covered topics you already knew well !!

Now imagine taking many different practice tests...

Some focus on algebra
Some test probability
Some include harder questions

After taking several tests, your average score gives a much clearer picture of your true preparation

Machine learning models face the same challenge:
Evaluating a model once may give a misleading result
Evaluating it multiple times on different data splits reveals its real performance

That repeated evaluation process is called Cross-Validation
Cross-Validation is a statistical technique used to estimate how well a machine learning model will perform on unseen data
It splits data into multiple subsets and evaluates the model multiple times:
For each iteration:
-
The model is trained on a portion of the data.
-
The remaining portion is used for testing.
-
The performance score is recorded.
Why Cross-Validation?

The Problem with Single Split
• Results highly dependent on random split
• Unreliable for small datasets
• Risk of overfitting to specific split

Overfitting Risk
Model memorizes training data quirks instead of learning patterns

Cross-Validation Solution
• Multiple train-test iterations
• Uses entire dataset efficiently
• Provides robust performance estimates

Holdout Validation

Simplest Evaluation Method
Dataset divided into two subsets for training and testing
Example Split
+
20%
Testing set
80%
Training set

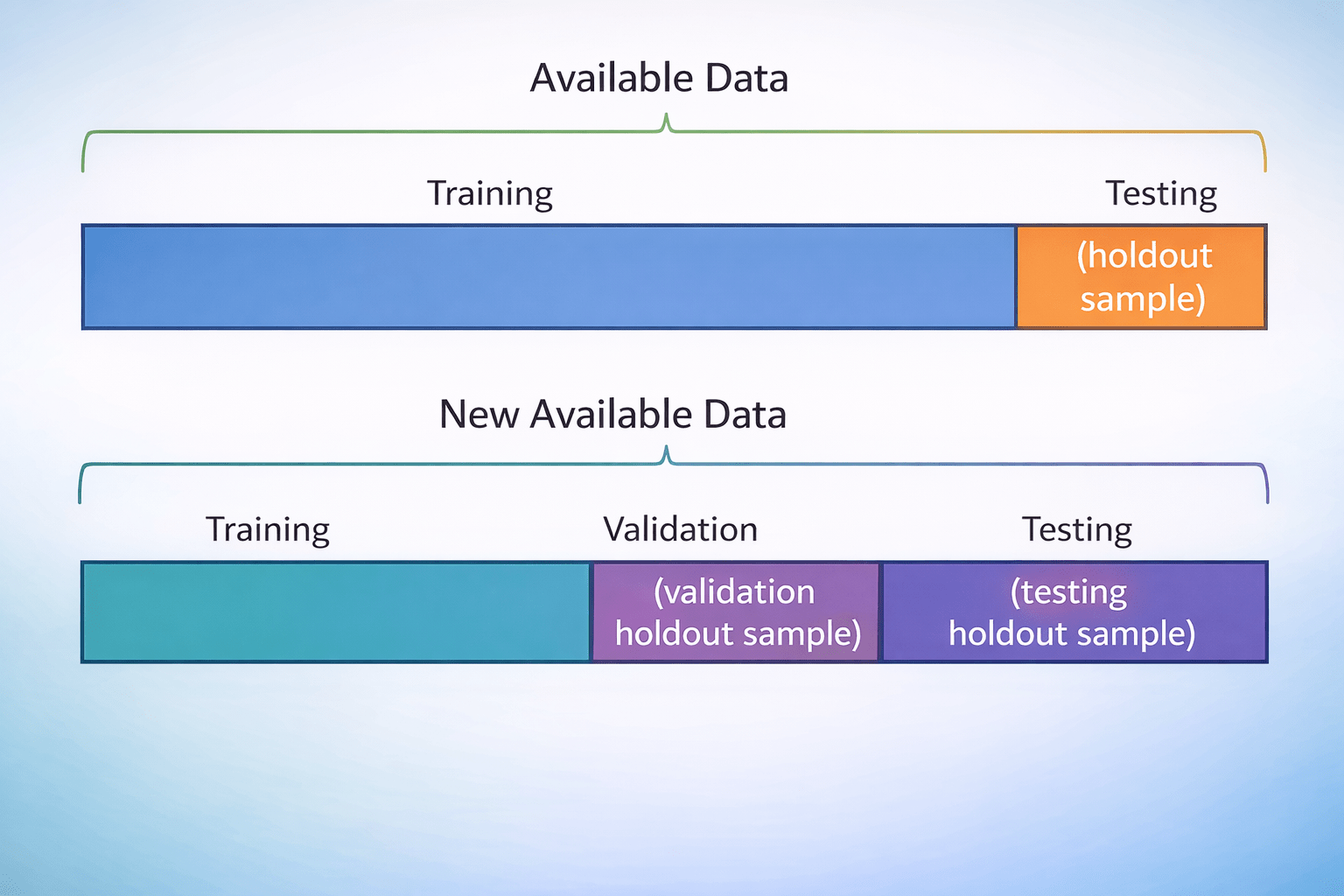
Limitations
• Results depend on split
• Unreliable for small datasets

These limitations lead to more reliable methods like K-Fold Cross-Validation
These limitations lead to more reliable methods like K-Fold Cross-Validation
Advantages
• Simple to implement
• Fast computation

K-Fold Cross-Validation

How It Works
Divide dataset into k equal folds
Example
- Train on 4 folds → Test on 1 fold
- Repeat 5 times, rotating test fold
- Average performance across all folds
k = 5
Advantages
Uses entire dataset
Reliable evaluation
Reduces Bias
Multiple iterations
Typical Values
k = 5 or 10

Implementation in Python (Scikit-Learn)

The implementation of cross-validation in Python is very similar to the process used for training models.
Step 1 — Import required libraries
from sklearn.model_selection import KFold, StratifiedKFold, cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegressionStep 2 — Load the dataset
X, y = load_iris(return_X_y=True)Step 3 — Initialize the model
model = LogisticRegression(max_iter=200)Step 4 — Apply K-Fold Cross-Validation
kf = KFold(n_splits=5)
scores_kf = cross_val_score(model, X, y, cv=kf)
print("K-Fold Scores:", scores_kf)
print("Mean Accuracy:", scores_kf.mean())Step 5 — Apply Stratified K-Fold Cross-Validation
skf = StratifiedKFold(n_splits=5)
scores_skf = cross_val_score(model, X, y, cv=skf)
print("Stratified K-Fold Scores:", scores_skf)
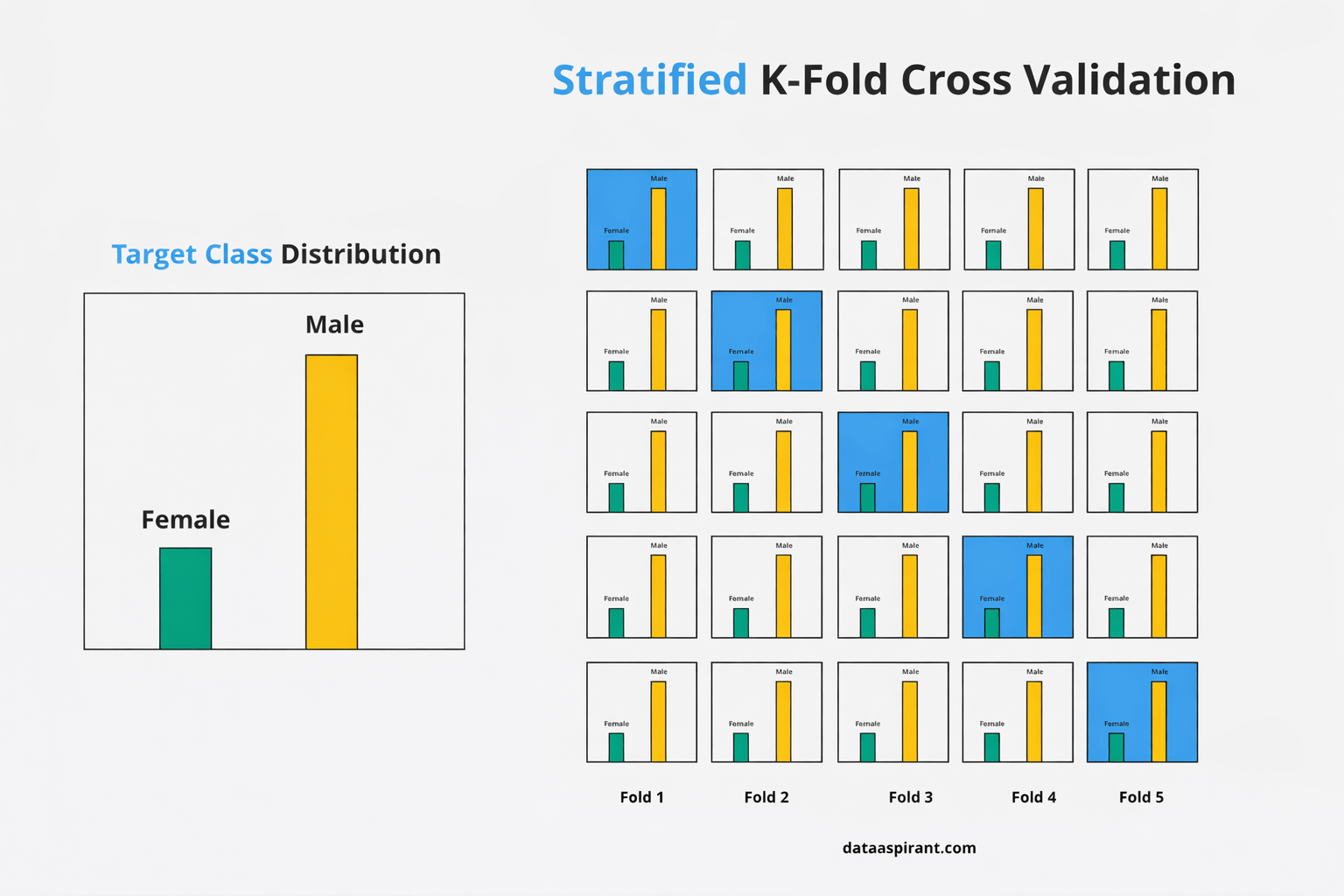
print("Mean Accuracy:", scores_skf.mean())Stratified K-Fold Cross-Validation

The Problem: Imbalanced Data
10%
90%
Class A
Class B
The Solution
Each fold maintains the original class proportion


Default CV for classifiers in scikit-learn
Default CV for classifiers in scikit-learn
This process automatically:

Splits the dataset into folds
Splits the dataset into folds
Trains the model multiple times
Trains the model multiple times
Computes evaluation scores
Computes evaluation scores
Returns the average model performance
Returns the average model performance
Summary
5
Scikit-learn automates this using KFold, StratifiedKFold, and cross_val_score.
4
Stratified K-Fold preserves class balance in classification tasks.
3
It reduces bias and uses the full dataset efficiently.
2
K-Fold splits data into k parts and averages results for better reliability.
1
Holdout validation uses an 80/20 split but can give unstable results.
Quiz
What is the main purpose of cross-validation?
A. Increase dataset size
B. Estimate model performance reliably
C. Remove missing values
D. Normalize features

Quiz-Answer
What is the main purpose of cross-validation?
A. Increase dataset size
B. Estimate model performance reliably
C. Remove missing values
D. Normalize features
